本文主要介绍下“视频翻译配音软件”有哪些功能,以及如何设置和使用。
该软件能实现将一种语言的视频,翻译为另一种语言的视频,处理后的新视频中的字幕和人类说话声都将是目标语言。
比如英文说话的视频,不管里面有没有字幕,处理后都将生成中文字幕,并使用中文说话。
主要功能模块有:
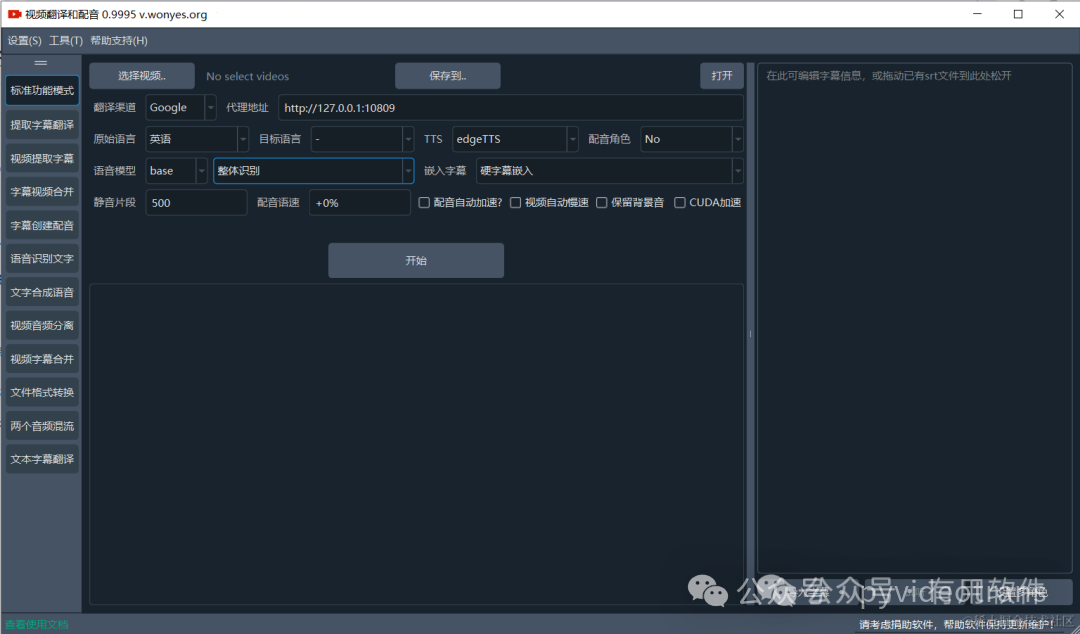
1. 标准功能模式(对应软件左侧第一个按钮):
即选择一个或多个想翻译的视频,然后软件界面中设置该视频的发音语言和想要翻译到的语言,并选择配音角色,将一键转换为目标语言字幕和配音的视频。
2. 从视频里识别生成字幕(对应左侧第二个按钮):
如果你只想为一个视频生成字幕文件,比如有一个英语视频,里面没字幕,或者虽然有字幕,但你还想要一个单独的英语字幕srt文件,那么可使用该功能,将根据视频里的说话声识别出文字并输出srt字幕文件。
3. 识别字幕并翻译(对应左侧第三个按钮):
和上个功能类似,所不同的是,你可以选择将识别出的字幕翻译为其他语言,比如从英语视频中识别字幕,选择目标语言中文,处理后将输出英语字幕和中文字幕两个srt文件。
4. 将已有的srt字幕文件嵌入视频中(对应左侧视频字幕合并按钮):
比如已有处理好的srt格式字幕文件,想嵌入本地已有的视频中作为硬字幕或者软字幕显示,那么可以选择该功能,右侧底部导入字幕文件,然后选择嵌入形式是硬字幕还是软字幕即可。
5. 根据已有的字幕文件创建配音音频(对应左侧字幕创建配音按钮):
已经有了srt格式字幕文件,只想根据该文件生成配音,那么可选该功能,右侧底部导入字幕,选择tts类型和配音角色就可以了。
6. 批量从音视频中识别创建字幕(对应左侧音视频转文字按钮):
该功能和第二个按钮“视频识别字幕”功能类似,所不同的是,该功能不仅可以从视频识别,还可以从音频中识别,并且一次可以选择多个音视频文件批量识别。
7. 将任意文字生成配音音频(左侧文字合成声音按钮):
该功能和“字幕创建配音”功能类似,不过该功能除了根据srt格式字幕创建配音外,还支持任意格式的文字,比如随便输入一行文字,就可以合成声音。
8. 从视频里的分离出来音频文件和无声影像(对应左侧视频音频分离按钮):
一般视频都是由声音和图像组成,如果你只想要一个视频里的声音,那么可以使用该功能,将抽离视频中的声音为音频文件。
同时还会创建一个无声视频,即删掉了里面任何声音的无声mp4。
9. 视频、音频、字幕三者合并为一个文件(对应左侧视音视字幕合并按钮):
比如你已有处理好的字幕文件、配音文件和mp4文件,希望合成他们为一个具有声音 字幕的视频,那么可以选择该功能,并且可以选择是否保留视频中原有的视频。
10. 两个音频文件混合为一个(对应左侧两个音频混流):
此功能适合于想创建有背景声音的音频,比如你有一段主播语音,想添加一个背景音乐,就可以使用该功能将主播语音文件和背景音乐文件混合,最终生成一个音频文件,同时有主播语音和背景音乐声。
11. 文字和字幕文件翻译(对应左侧文本字幕翻译按钮):
该功能是通用文字翻译,类似百度翻译,但同时支持srt格式字幕的翻译,翻译结果将保留原字幕格式。
12. 人声背景分离:将视频或音频中的声音抽离为两个音频文件,分别是人类说话声和其他声音。
13. 下载油管视频:输入油管视频的播放页面,即可在此下载视频到计算机。
以上就是该软件的主要功能。
再介绍下软件界面中各个设置选项的涵义:
1. 选择视频按钮:这个是用来从电脑里选择要处理的视频,一次可以选择多个视频。
2. 保存到按钮:用来选择将处理后的文件保存到哪里去,如果不选择,默认就和原始视频保存在一个文件夹内的_video_out内。
3. 右上角打开按钮:用来打开目标文件夹。
4. 翻译渠道按钮:用来选择翻译文字和字幕时使用哪个翻译,支持百度翻译 google翻译 微软翻译 腾讯翻译 chatgpt翻译等。
5. 代理地址文本框:如果你使用google翻译或者chatGPT,需要在此填写代理地址才可以访问,代理格式为 http:127.0.0.1:数字端口号。
7. 原始语言:就是视频里的人类说话语言。
8. 目标语言:你想翻译为哪种语言。
9. TTS类型:使用什么配音渠道,目前支持免费的edgeTTS、openaiTTS-1、elevenlabsTTS和原声音色配音项目clobe-voice。
10. 配音角色:即发音角色,不同角色音色不同,有女声男声等。
11. 试听按钮:在选好配音角色之后,可以点击试听按钮,感受当前角色的声音,注意可能需要几秒钟来生成和输出声音。
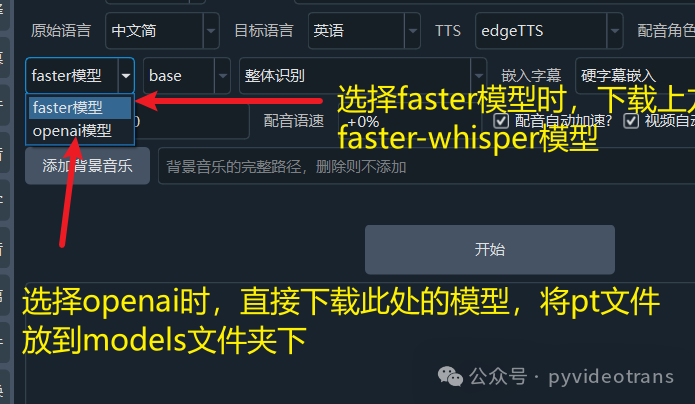
12. faster模型和openai模型:这两个模型是用来将视频里的人类说话声转为文字的,都可以选择base small medium large-v2 large-v3,从base到large-v3,效果越来越好,但所需计算机硬件条件也越来越高。具体可阅读上一篇文章。
语音识别模型哪家强,faster-whisper还是openai-whisper?语音识别选择哪个模型
13. 整体模式和预先分割:
整体模式是将整个说话声都交给模型处理,每个字幕时长也有模型控制,效果更好,但也可能出现超长字幕遮住整个视频的情况。整体模式适合有明显停顿并且没背景声音的视频。
预先分割是指提前将说话声切割为10秒左右的片段,依次交由模型处理,字幕时间比较均匀,但可能出现断句问题,即一句话没说完就强制断开了。
具体如何选择,可以根据视频情况而定。
14. 嵌入字幕:即将字幕以什么形式嵌入视频中,可选不嵌入,硬字幕嵌入,软字幕嵌入。
硬字幕嵌入是指无论在哪里播放,始终会在播放界面显示,无法隐藏,如果你希望在网页播放时也能显示字幕,难么应该选该项。
软字幕是指以链接形式嵌入:如果播放器支持,可以选择显示或隐藏字幕,但要注意,网页中播放是不支持软字幕的,而且很多播放器需要将字幕文件命名为和视频一样的名称,并放在同一位置才能显示。某些国产播放器还需要手动将srt文件转为gbk编码,否则显示会乱码。
15. 静音片段:填写整数数字,代表以多少的静音间隔切分说话声,默认500,即在检测到两段说话声之间的停顿大于等于500ms时,将在此切割为两部分。如果设置太小,可能导致大量的1s 2s等过短片段,过大可能导致30s 60s等过长片段,造成字幕占满屏幕。
16. 配音语速: 是否对配音进行加减速。
如果加速,填写+开头后跟数字和%号,比如+50%,代表将在正常速度基础上速度加快50%,即1.5倍速。
如果减速,使用负号-开头,比如-50%,代表在正常基础上降低50%的速度,即0.5倍速。
17. 配音自动加速和视频自动慢速:同一句话,在不同语言下发音时长是不同的,因此翻译配音后,时长必然发生变化,带来的影响就是字幕 声音 画面不同步,可通过两种方式来调节。
配音自动加速,是指当配音后的时长大于原发音时长时,通过加快配音语速来缩短配音时长,以达到和原时长一致。
视频自动慢速是指,如果配音后时长比原时长更长,配音时长不变,将原视频里对应时长的视频慢速播放,延长视频播放时长和配音时长一致。
存在的问题是:配音自动加速可能会太快,导致听不清在说什么,而视频慢速播放又可能太慢,简直成了慢动作回放。
可以通过同时选中该两项,稍稍进行缓解。当然最好方式还是在识别后和翻译后手动精简字幕避免字幕太长。
18. 启用CUDA:如果你有英伟达显卡并且配置好了cuda环境,可选中该项,将明显提升速度。具体安装配置cuda环境查看之前一篇文章。
19. 保留背景音:如果不选择该项,那么配音后,视频中将不存在原视频里的背景声音,如果你想保留,可以选择该项。另外如果背景音太大或识别效果不好时,除了使用large大模型外,也可以选择启用该项,将会先分离背景声音后再做识别,效果可能更好。
20. 添加背景音乐按钮:如果你想对结果视频额外加一个背景音,比如一段轻音乐,那么你可以点击该按钮,选择一个音频文件,将在视频生成前,将该音频文件嵌入作为背景声音播放。
如果添加后在执行前又不想要它了,直接在右侧文本框内删除显示的内容即可。
21. 右侧字幕区大文本框:识别后和翻译后均会在此显示字幕内容,你可以点击当时左侧出现的“暂停按钮”在暂停后修改字幕。
22. 字幕区下方的导入字幕按钮:可以导入你本地已有的字幕,当导入后,就不再从视频中识别了,而是直接使用你导入的。
23. 导出按钮:可将字幕区当前显示的内容导出到计算机。
24. 字幕区下方试听按钮:试听当前字幕区内容
25. 多角色配音:为每一行字幕指定一个配音角色,实现多角色配音。
24. 菜单设置:可以在这里分别设置各个翻译渠道用到的key和密钥等信息,比如百度翻译、腾讯翻译、chatGPT、DeepL等信息均在此点开查看。
25. 菜单支持与帮助:该菜单下是各个有用工具、开源地址、文档站点、常见问题页面等链接,比较有用。
----
视频翻译与配音开源地址:
https://github.com/jianchang512/pyvideotrans/
B站教程:搜索用户名 pyvideotrans
