丰富的色彩来自奥飞寺
量子比特报告 | 公众号QbitAI
很多3D人体模型很厉害,但总是“条纹”。
要打造真正的人类“阿凡达”模型3d人体模型软件,衣服和头发缺一不可。
但这些元素的精确 3D 数据很少且难以获得。

三星AI中心(莫斯科)等团队的技术人员一直致力于这方面的工作,最终他们开发了这样一个模型:
生成的3D人物以原来的服装和发型毫无保留地呈现出来。
乍一看,“看起来像真人”。
更棒的是,不需要模特示范,模特还可以“举一反三”,摆出各种姿势!
效果是这样的:

该模型名为 StylePeople。
让我们看看它是如何工作的!
神经穿衣模型
其实不只是“裸奔”,很多三维人体模型也非常“僵化”:模特摆出什么姿势,模特就会跟着走。
和之前一样,利用隐式函数生成的三维人体模型可以高度还原模型的服装和发型,但人物姿势仍然不够灵活,只能从原始模型的几个特定角度生成。
附: 也是这个团队的研究成果
因此,在为3D人体模型还原衣服颜色、褶皱、发型的同时,还要保证角色的姿势能够“举一反三”。
为此,研究人员采用了将多边形实体网格建模与神经纹理相结合的方法。
多边形网格负责控制和建模粗糙的人体姿势几何形状,而神经渲染负责添加衣服和头发。
首先,他们设计了一个神经穿衣模型(The Neural Dressing Model),它结合了可变形网格建模和神经渲染,如下图所示。

最左边的列代表可视化的前三个 PCA 组件。
第 2 列和第 3 列是叠加在使用 SMPL-X 建模的人体网格上的“人体头像”的纹理。
第 4 列和第 5 列是使用渲染网络进行光栅化的结果。
宽松的衣服、长发以及复杂的服装结构都能优雅驾驭!
接下来,基于上述神经穿衣模型,研究人员创建了一个可以生成“全身”的3D人体模型。
最终的生成架构是 StyleGANv2 和神经修整的结合。
StyleGAN 部分使用反向传播算法生成神经纹理,然后将其叠加在 SMPL-X 网格上并使用神经渲染器进行渲染。
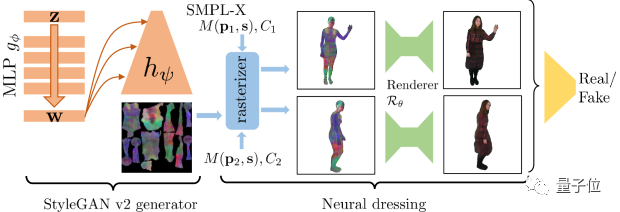
在对抗性学习中,鉴别器将每对图像视为同一个人。
改进了从视频和少量图像生成 3D 人体模型的技术
在验证神经穿衣方法的效果时,研究人员首先评估了基于视频素材的3D模型生成结果。
效果就像文章开头的图片一样。 左侧是样本源帧,其余图像是左侧视频角色的“化身”。 在一个简单的增强现实程序的背景下,呈现了模型之前未曾呈现的各种姿势。
接下来,评估基于小样本图像材料的神经穿衣效果。
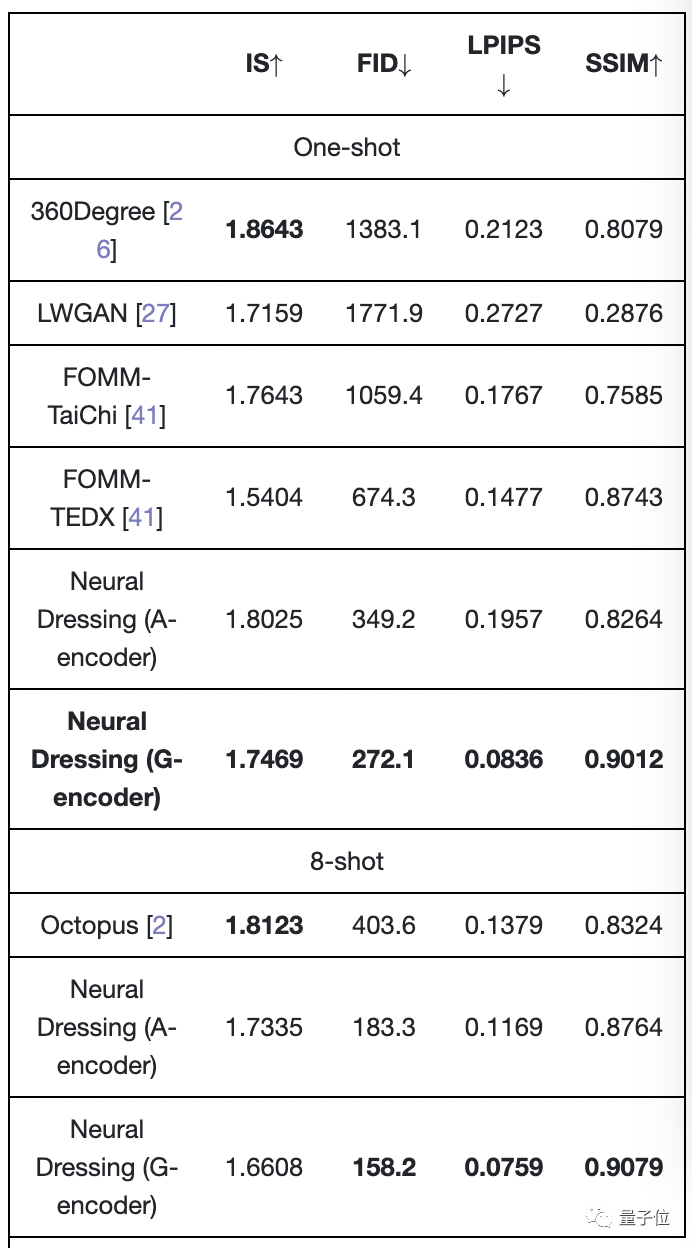
研究人员使用两个人的人物快照数据集将他们的神经穿衣方法与各种其他方法(例如 360Degree 等人,见表)进行了比较。
衡量生成模型质量的指标包括 LPIPS(感知相似性)、SSIM(结构相似性)、FID(特征空间中真实样本与生成样本之间的距离)和 IS(清晰度和多样性得分)。
结果表明他们的方法在所有指标上都优于3d人体模型软件,
除 IS 外,但影响并不显着,因为它与视觉质量的相关性很小。
最后,团队表示,他们的模型的生成效果(如下图)仍然受到当前样本数据的大小和质量的限制,未来的工作将集中在提高模型的数据利用率上。

有兴趣的同学可以继续关注团队的研究进展。
参考链接:
[1]
- 超过-
本文为网易新闻·网易精选内容激励计划签约账号【量子比特】原创内容。 未经账号授权,禁止任何转载。
加入AI社区,扩大您在AI行业的人脉
量子比特“AI社区”招募中! 欢迎AI从业者和关注AI行业的朋友扫描二维码加入,与50000+朋友一起关注AI行业的发展和技术进步:


量子比特QbitAI·今日头条签约作者
̾'ᴗ' ̫ 追踪AI技术和产品新进展
连续点击三下“分享”、“点赞”、“观看”
尖端科技的进步天天可见~
