R 是一种广泛用于数据分析和统计计算的强大语言,它开始发展于 20 世纪 90 年代,得益于全球众多爱好者的不懈努力,他们随后开发了 R Studio,它基于 R,但比基本的 R 文本编辑器更好(具有更好的用户界面体验)。也正是由于全球越来越多的数据科学社区和用户对 R 包的慷慨贡献,R 语言在全球越来越受欢迎。其中一些 R 包,例如 MASS、SparkR 和 ggplot2,使数据操作、可视化和计算越来越强大。
我们谈论的机器学习和 R 有什么关系?我对 R 的第一印象是它只是一个用于统计计算的软件。但后来我发现 R 有足够的能力以快速简单的方式实现机器学习算法。这是使用 R 学习数据科学和机器学习的完整教程。阅读本文后,您将具备使用机器学习方法构建预测模型的基本能力。
注意:这篇文章对于那些对数据科学没有太多了解的同学来说尤其值得一读。同时,掌握一些代数和统计学知识对你的学习会更有益。
2. 开始使用 R
1.为什么要学习R?
其实我没有任何编程经验,也没有学过计算机。但我知道,如果想学数据科学,必须学习 R 或 Python 作为入门工具。我选择了前者,在学习的过程中,我发现了使用 R 的一些好处:
2.如何安装R/Rstudio?
你可以从官方网站下载并安装 R。需要注意的是,R 的更新速度非常快,因此下载最新版本会给你带来更好的体验。
另外,我建议你从 RStudio 入手,因为 RStudio 的界面编程体验更好。你可以前往 /products/rstudio/download/,在“支持的平台上安装”部分根据你的操作系统选择你需要的安装程序。点击桌面图标 RStudio 即可开始你的编程体验,如下图所示:
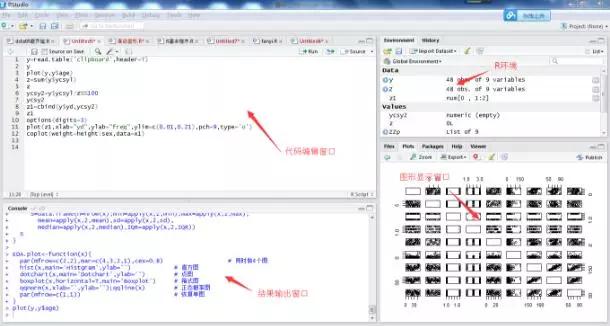
让我们快速浏览一下 R 界面:
3. 如何安装该软件包?
R 的计算能力在于其强大的 R 包。在 R 中,大多数数据处理任务可以从两个方面完成,使用 R 包和基本函数。在本教程中,我们将介绍最方便、最强大的 R 包。特别说明的是,一般不建议在 R 软件中直接安装和加载包,因为这可能会影响你的计算速度。我们建议你直接从 R 官方网站下载所需的 R 包,然后按照如下方式在本地安装:
在软件中安装:install.packages("软件包名称")
本地安装:install.packages("E:/r/ggplot2_2.1.0.zip")
4. 使用 R 进行基本统计计算
我们先熟悉一下 R 编程环境和一些基本的计算。在 R 编程脚本窗口中输入程序,如下所示:
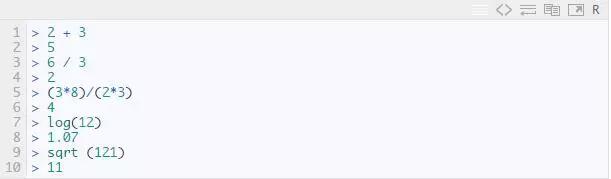
同样,你也可以尝试各种计算形式的组合,自己得出结果。但是,如果计算次数过多,这样的编程就太麻烦了。在这种情况下,创建变量是一种有用的方法。在 R 中,你可以创建变量来简化。创建变量时,使用 <- 或 = 符号。例如,我想创建一个变量 x 来计算 7 和 8 的总和,如下所示:
特别地,一旦我们创建了一个变量,你就不再直接得到输出,我们需要输入相应的变量,然后运行结果。注意变量可以是字母、字母数字,但不能是数字,数字不能创建数字变量
3 编程和 R 包的基本概念
1. R 中的数据类型和对象
R中的数据类型包括数字、字符、逻辑、日期和默认值。我们在使用数据的时候,可以很容易地自己理解这些数据类型,所以这里就不详细讲解了。
R 中的数据对象主要包括向量(数字、整数等)、列表、数据框和矩阵。我们来仔细看看:
○1 向量
如上所述,向量包含同一类的对象。但是r软件教程,您也可以混合不同类的对象。当不同类的对象在列表中混合时,效果是不同类型的对象会转换为一个类。例如:
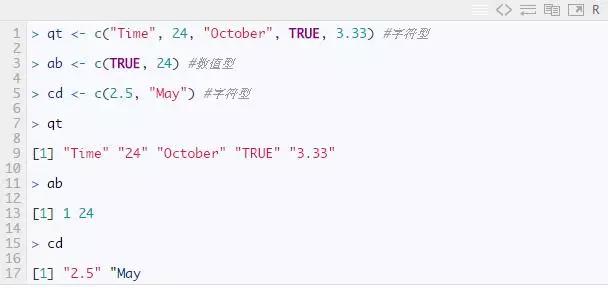
注意:1. 要检查任何对象的类,请使用 class() 函数。2. 要转换数据的类,请使用 as.() 函数。
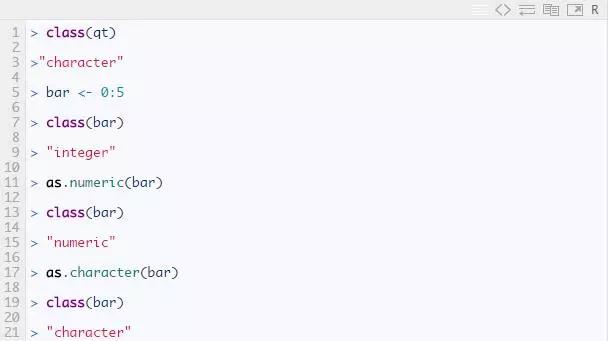
类似地,您可以尝试自己更改任何其他类向量。
○2 列表
列表是一种特殊类型的向量,其中包含不同数据类型的元素。例如
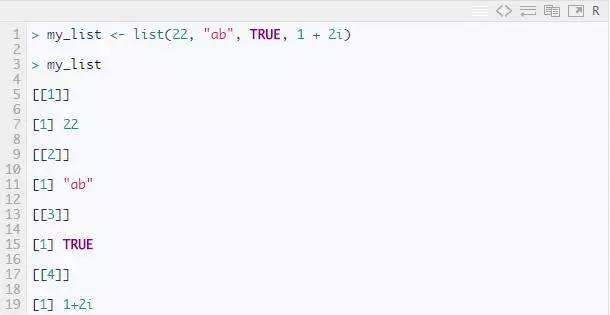
如您所见,列表的输出与向量不同。这是因为所有对象的类型不同。第一个双括号 [1] 显示第一个元素包含的内容,依此类推。或者,您可以自己尝试一下:

○3 矩阵
当向量被赋予行和列属性时,它就变成了矩阵。矩阵由行和列组成。让我们尝试创建一个有 3 行 2 列的矩阵:
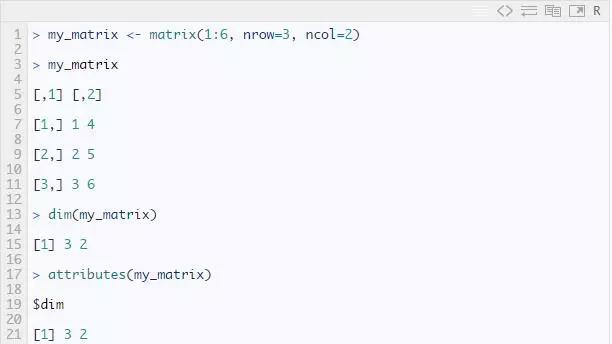
如您所见,您可以使用 dim() 或 attributed() 命令获取矩阵的维度,并且要从矩阵中提取特定元素,只需使用上面的矩阵形式。

类似地,你也可以从向量创建所需的矩阵。我们需要做的就是使用 dim() 来分配维度。如下所示:
或者,您也可以使用 cbind() 和 rbind() 函数连接两个向量。但是,您需要确保两个向量具有相同数量的元素。如果不是,它将返回 NA 值。
○4 数据框
这是最常用的数据类型,用于存储列表数据。它不同于矩阵,矩阵中的每个元素必须具有相同的类。但是,在数据框中,您可以放置包含不同类列表的向量。这意味着每列数据都像一个列表,每次在 R 中读取数据时,它都会存储在数据框中。例如:
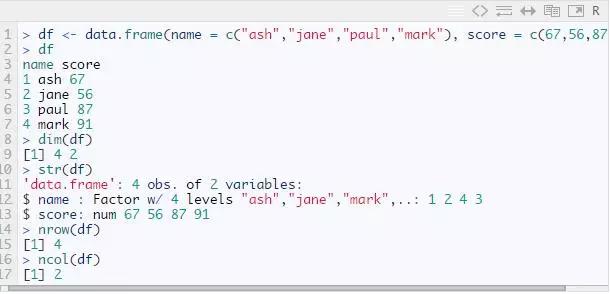
我们来解释一下上面的代码。df 是数据框的名称。dim() 返回数据框的规格,有 4 行 2 列,str() 返回数据框的结构,nrow() 和 ncol() 返回数据框的行数和列数。特别地,我们需要理解 R 中的缺失值概念,NA 代表缺失值,这也是预测建模的关键部分。现在,让我们检查一下数据集是否有缺失值。

缺失值的存在严重阻碍了我们正常计算数据集。例如因为有两个缺失值,所以不能直接做平均得分。例如:
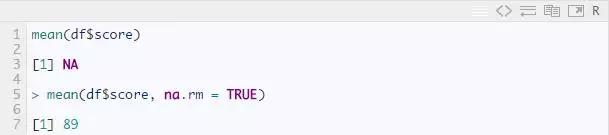
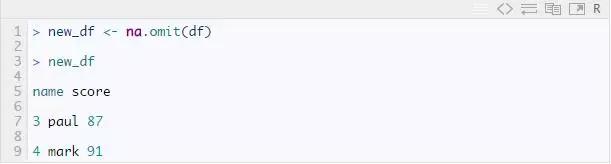
na.rm = TRUE 告诉 R 忽略缺失值,只计算所选列中剩余值的平均值(分数)。要删除数据中含有 NA 的行,可以使用 na.omit
2. R 中的控制语句
顾名思义,这类语句在编码中起到控制函数的作用。编写函数也是一组多个命令,用于自动重复编码过程。例如:你有 10 个数据集,你想找出每个数据集中存在的“年龄”列。这可以通过两种方式完成。一种需要我们运行特定程序 10 次,另一种需要我们编写控制语句来完成。我们先来了解 R 中控制结构的一个简单的例子:
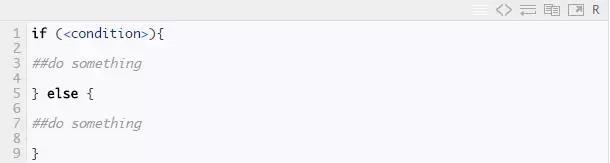
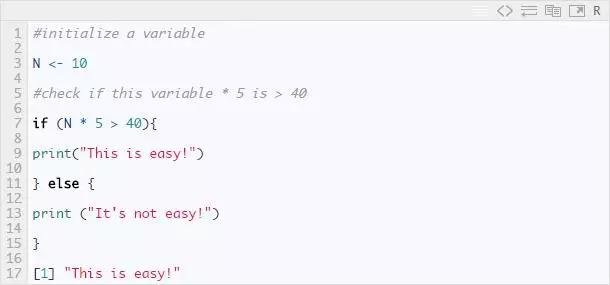
If.else,此结构用于测试条件。语法如下:
例子:
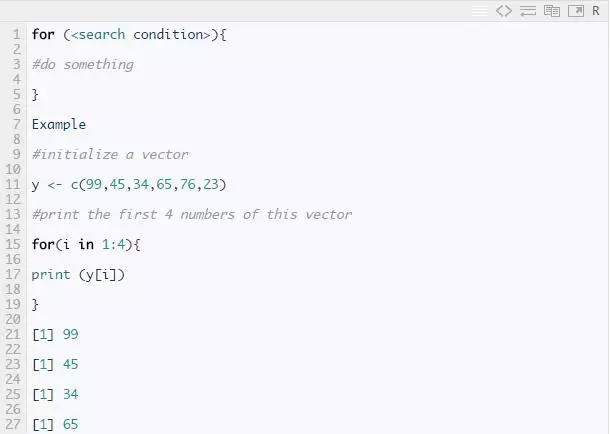
For 语句,当循环执行固定次数时使用此结构。语法如下:
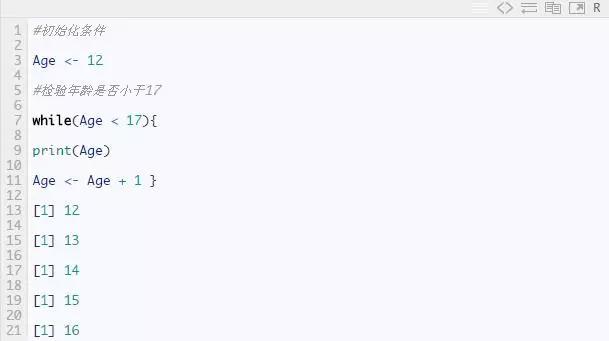
while 语句
它首先测试条件,只有条件为真时才执行,一旦执行循环,就会再次测试条件,直到满足指定的条件,然后给出输出。以下是语法
当然,还有其他控制结构,但它们的使用频率不如上面解释的那么高。例如:
注意:如果您发现控制结构的这一部分难以理解,请不要担心。R 有很多由许多人贡献的软件包,它们会对您有很大帮助。
3. 常用 R 包
在 R 镜像(CRAN)中,有超过 7800 个包可供大家使用,其中很多包都可以用于预测建模。本文中,我们将在下面简单介绍其中的几个。之前我们已经讲解了如何安装包。大家可以根据自己的需求下载安装。
导入数据
R提供了丰富的数据导入导出包,可以访问任意格式的数据,例如txt、csv、sql等,可以快速导入大文件数据。
数据可视化
R 还内置了绘图命令,非常适合创建简单的图形。但是,当您创建的图形变得更加复杂时,您应该安装 ggplot2。
数据操作
R中有很多用于数据操作集合的包,可以做基本和高级的快速计算,例如dplyr,plyr,tidyr,lubricate,stringr等。
建模学习/机器学习
对于模型学习,caret包足够强大,可以满足大多数机器学习模型的需求。当然你也可以安装算法包,比如随机森林、决策树等。
至此,你应该已经熟悉了R的相关组件,从现在开始,我们来介绍一些关于模型预测的知识。
4. 使用 R 进行数据预处理
从本节开始,我们将深入了解预测建模的不同阶段。数据预处理非常重要。这一阶段的学习将加强我们对数据操作的应用。接下来让我们在 R 中学习和应用它。在本教程中,我们以这个大型市场销售预测数据集为例。首先,让我们了解数据结构,如下所示:

1. 数据收集的基本概念
○1最后一列ItemOutlet_Sales是响应变量(因变量y),也就是我们需要进行预测的变量。前面一个变量是自变量xi,用于预测因变量。
○2 数据集
预测模型通常使用训练数据集构建,该训练数据集始终包含响应变量;和测试数据:模型建立后,将在测试数据集上进行测试,测试数据集始终包含比训练数据集更少的观测值,并且不包含响应变量。
数据的导入和基本探索
○1 使用R语言时,一个重要的设置是定义工作目录,也就是设置当前运行的路径(这样你的所有数据和程序都会保存在这个目录中)
设置目录后,我们可以使用以下命令导入 csv 文件轻松导入数据:

检查数据是否已通过 R 环境成功加载,然后我们来探索数据
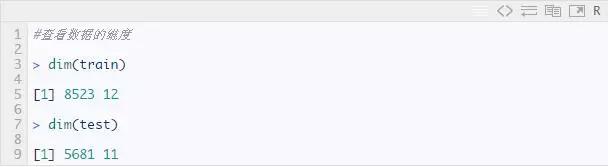
从结果中我们可以看到训练集有 8523 行 12 列数据,测试集有 5681 行 11 列训练数据,这也是正确的。测试数据应该总是少一列。现在让我们深入探索训练数据集
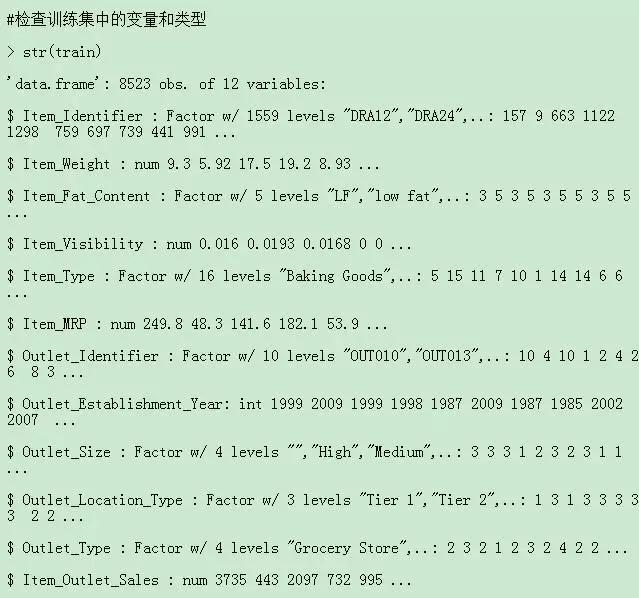
2. 图形表示
使用图表来表示,我想大家对这些变量会有更好的理解。一般来说,我们可以从两个方面来分析数据:单变量分析和双变量分析。单变量分析比较简单,这里就不讲了。本文我们以双变量分析为例:
(为了实现可视化,我们将使用 ggplot2 包。这些图可以帮助我们更好地理解数据集中变量的分布和频率)
首先,绘制两个变量 Item_Visibility 和 Item_Outlet_Sales 的散点图
1ggplot(train, aes(x = Item_Visibility, y = Item_Outlet_Sales)) + geom_point(size = 2.5, color = "navy") + xlab("商品可见性") + ylab("商品直销店销售额") + ggtitle("商品可见性 vs 商品直销店销售额")
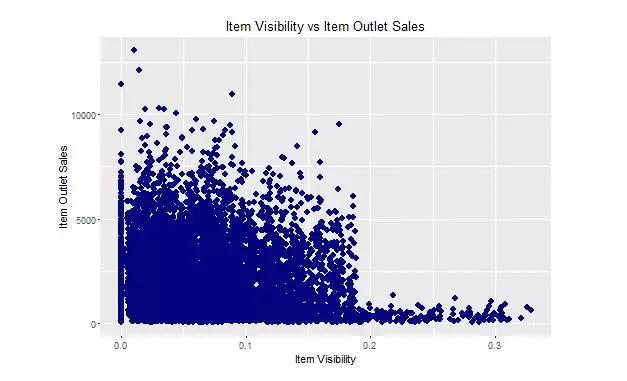
从图中我们可以看出,大部分销量来自可见度小于 0.2 的产品。这表明,如果 item_visibility < 0.2,那么这个变量一定是决定销量的重要因素。
制作 Outlet_Identifier 和 Item_Outlet_Sales 变量的条形图
1ggplot(train, aes(Outlet_Identifier, Item_Outlet_Sales)) + geom_bar(stat = “identity”, color = “purple”) + theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color = “black”)) + ggtitle(“Outlets vs Total Sales”) + theme_bw()
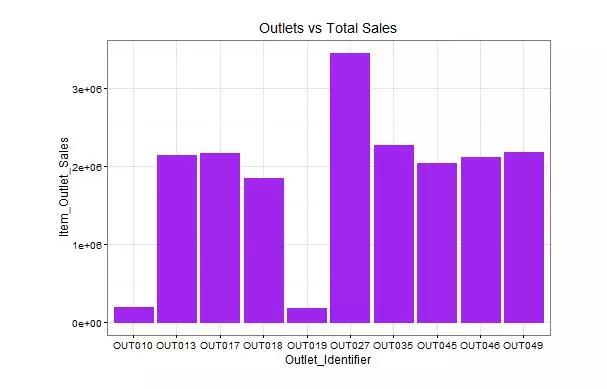
这里我们推断OUT027的销量可能影响了紧随其后的OUT35的销量,OUT10和OUT19可能客流量最少,导致门店销量最少。
绘制 Outlet_type 和 Item_Outlet_Sales 变量的箱线图
1ggplot(train,aes(Item_Type,Item_Outlet_Sales))+ geom_bar(stat =“identity”)+ theme(axis.text.x = element_text(angle = 70,vjust = 0.5,color =“navy”))

从该图表中,我们可以推断出,在零食销售量方面,水果和蔬菜对该店的收益最大,其次是家居用品。
绘制两个变量 Item_Type 和 Item_MRP 的箱线图
这次我们用的是箱线图,箱线图的好处是可以看到对应变量的异常值和均值偏差水平。
1ggplot(train, aes(Item_Type, Item_MRP)) + geom_boxplot() + ggtitle(“箱线图”) + theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color = “red”)) + xlab(“商品类型”) + ylab(“商品 MRP”) + ggtitle(“商品类型 vs 商品 MRP”)
图中黑点为异常值,框内的黑线为各个item类型的平均值。
3.缺失值处理
缺失值对自变量和因变量之间的关系有很大的影响。现在,让我们了解处理缺失值的知识。让我们做一些快速的数据探索。首先,我们将检查数据是否有缺失值。

我们可以看到训练数据集中有 1463 个缺失值。我们来检查一下这些缺失值的变量在哪里。事实上,许多数据科学家已经多次建议初学者在数据探索阶段要密切关注缺失值。
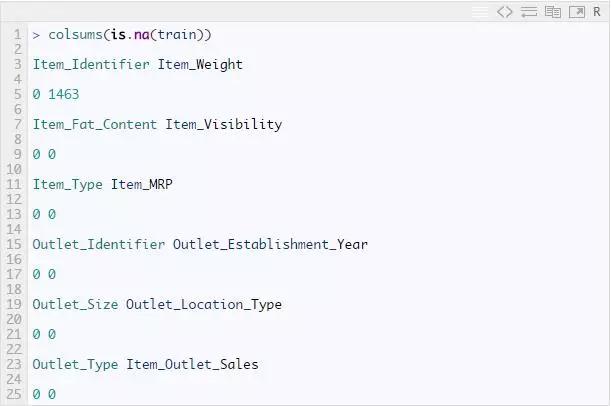
因此,我们看到Item_Weight列有1463个缺失数据。我们还可以从这些数据中得出更多推论:
1> 总结(训练)
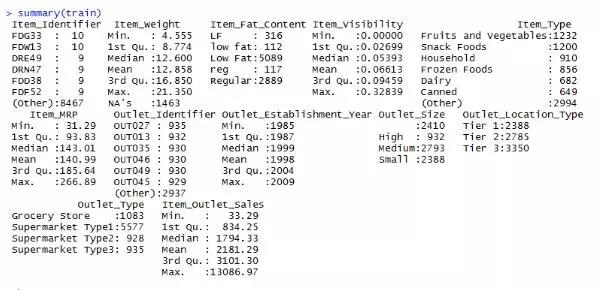
从图中我们可以看到每列的最小值、最大值、中位数、均值、缺失值信息等。我们可以看到变量Item_Weight中存在缺失值,而Item_Weight是连续变量。因此,这种情况下我们一般会用样本中该变量的均值或者中位数来赋值缺失值。计算变量item_weight的均值和中位数是处理缺失值最常用的方法,其他方法这里就不多说了。
我们可以先将两个数据集合并起来,这样就不需要编写独立的编码训练和测试数据集,这也会节省我们的计算时间。但是,要合并两个数据框,我们必须确保它们具有相同的列,如下所示:

我们知道测试数据集少了一列因变量。我们先添加该列。我们可以为该列分配任何值。一种直观的方法是,我们可以从训练数据集中提取销售额的平均值,并使用 $Item_Outlet_Sales 作为测试变量的销售额列。但是,在这里,我们保持简单,并为最后一列分配值 1。
接下来,我们计算中位数。之所以选择中位数,是因为它在离散值中非常具有代表性。
4. 连续变量和分类变量的处理
在数据处理中,区分连续数据集和分类变量非常重要。在这个数据集中,我们只有 3 个连续变量,其他都是分类变量。如果你仍然感到困惑,建议你使用 str() 再次查看数据集。
对于变量Item_Visibility,我们在上图中可以看到,这个item的部分visibility为0,这几乎是不可行的,所以我们考虑把它当做缺失值,用中位数来处理。
现在让我们讨论分类变量。在我们最初的数据探索中,我们发现有些变量的级别不正确,需要进行纠正。

使用上面的命令,我们为其他未命名的变量指定了名称“others”,这些变量只是对Item_Fat_Content级别进行分类。
5. 特征值变量计算
现在我们已经进入大数据时代,很多时候需要大量的数据算法计算,但之前选定的变量可能与模型拟合度并不好。因此我们需要提取新的变量,提供尽可能多的“新”信息,帮助模型做出更准确的预测。以合并后的数据集为例,你认为哪些因素可能会影响Item_Outlet_Sales?
关于商店类别变量计算
源数据中有 10 家不同的商店。商店越多,某种产品在该商店销售的可能性就越大。
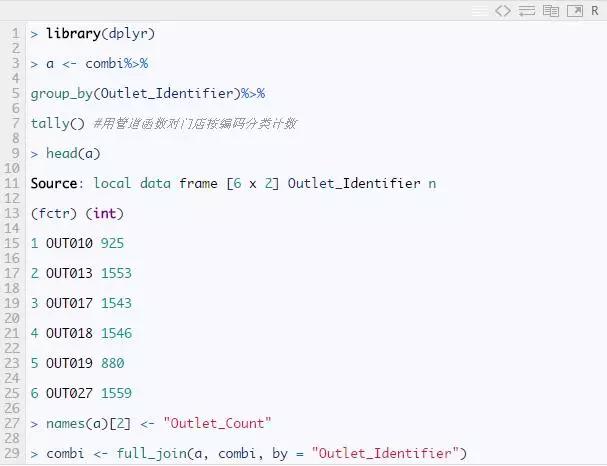
注意:管道函数的思想是将左边的值通过管道传输到右边调用的函数的第一个参数中。
产品类别计算
同样的,我们还可以计算产品类别的信息,这样通过结果就可以看到产品在各个商店出现的频率。
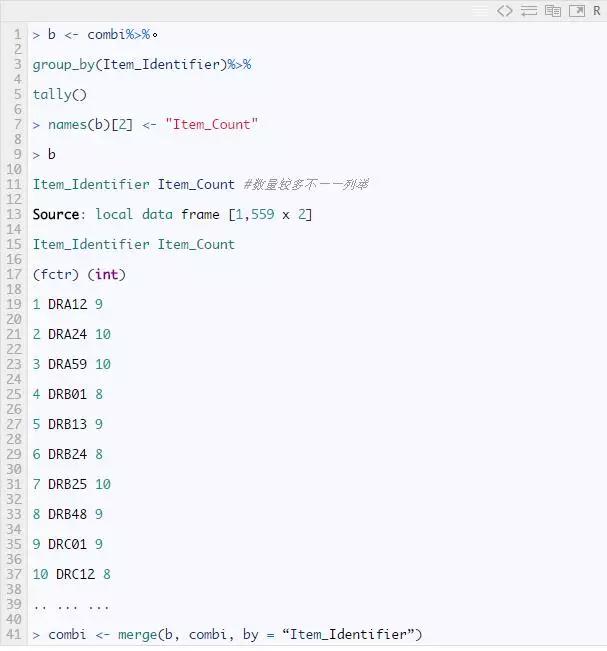
探索店铺开设时间的变量
我们假设商店越老,其客流量和产品销量就越大。
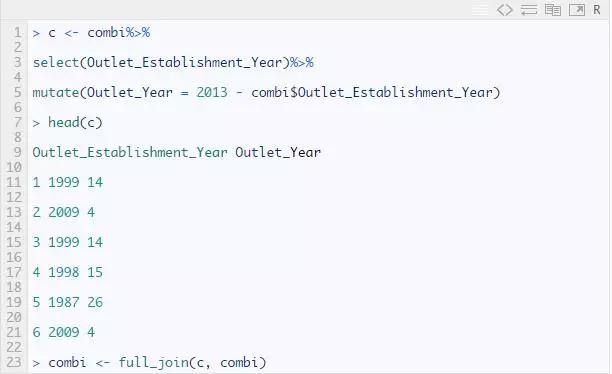
以第一年为例,表示该机构成立于1999年,迄今已有14年历史(2013年为结束年份)。
注意:mutate函数对现有列执行数据操作并将其添加为新列。
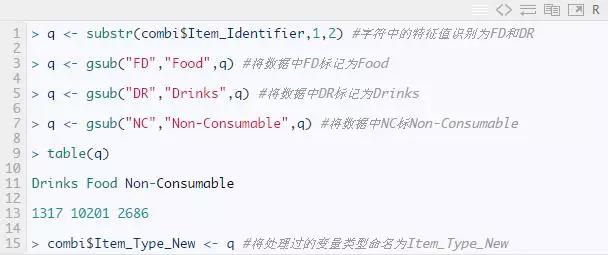
与产品类型相关的计算
通过计算商品种类,我们可以发现人们的消费趋势。从数据中我们可以看到,标记为 DR 的商品大部分是可食用食品。对于 FD,它们大多属于饮料类别。同样,我们注意到 NC 类别可能是日用品(非消耗品),但 NC 类别中的标签更复杂。因此,我们将这些变量提取出来,并将它们放入一个新变量中。这里我将使用 substr() 和 gsub() 函数来提取和重命名变量。
当然你也可以尝试加入一些新的变量来帮助建立更好的模型,但是加入新变量的时候一定要与其他变量不相关,如果你不确定与其他变量是否有相关性,可以使用函数 cor() 来判断。
编码字符变量
○1标签代码
这部分的任务是对字符标签进行编码。例如,在我们的数据集中,变量 Item_Fat_Content 有 2 个级别:低脂肪和常规。我们将低脂肪编码为 0,常规编码为 1。这有助于我们进行定量分析。我们可以使用 ifelse 语句来做到这一点。
1> 组合$Item_Fat_Content
○2-hot 编码
One-hot 编码又叫单比特有效编码,它用一个 N 位状态寄存器来编码 N 个状态,每个状态由一个独立的寄存器位组成,任何时候,只有其中一个状态有效。例如:变量 Outlet_ Location_Type。它有三个层级。在 one-hot 编码中,会创建三个不同的变量 1 和 0,1 代表变量存在,0 代表变量不存在。如下:
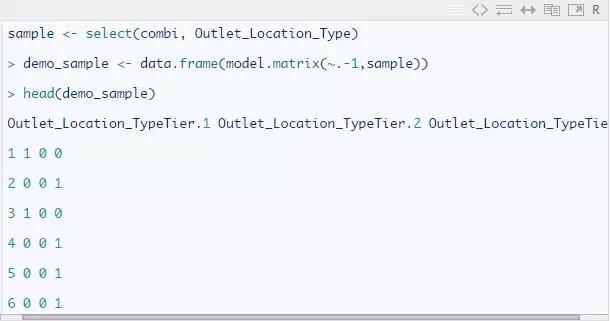
这是 One Hot Encoding 的演示。希望你现在理解了这个概念。现在让我们将这项技术应用于数据集中的分类变量(不包括 ID 变量)。
>图书馆(傻瓜)
>组合
上面我们介绍了两种在R中进行独热编码的不同方法。我们可以检查一下编码是否已经完成。
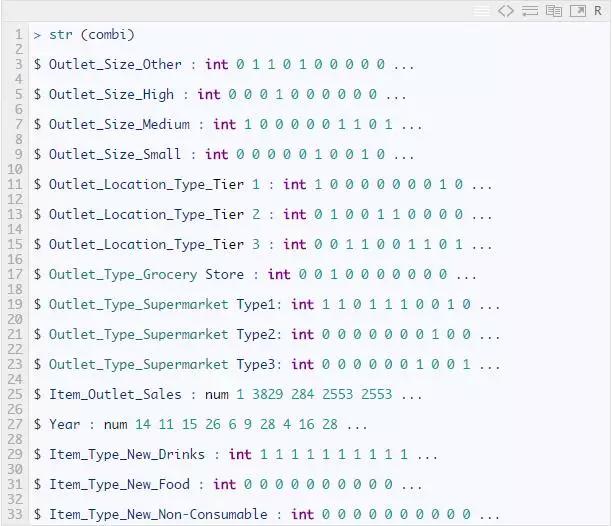
我们可以看到,经过独热编码后,先前的变量已自动从数据集中删除。
5. 使用机器学习方法进行预测建模
在构建数据模型之前,我们将删除之前已经转换过的原始变量。这可以通过使用 dplyr 包中的 select() 来实现,如下所示:
> 组合
> str(组合)
在本节中,我将介绍回归、决策树和随机森林等算法。这些算法的详细解释超出了本文的范围。如果你想了解更多,我建议阅读有关机器学习的书籍。现在我们需要将两个数据集分离出来,以便进行预测建模。如下所示:
1.多元线性回归
使用多元回归建模时,一般用于响应变量(因变量)为连续型,且预测变量较多的情况。如果因变量是分类的,我们一般使用逻辑回归。在做回归之前,我们先了解一下回归的一些基本假设:
在 R 中我们使用 lm() 函数进行回归,如下所示:
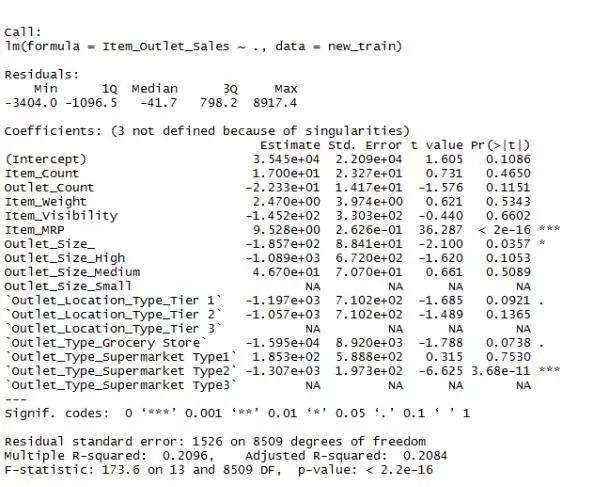
Adjusted R² 是衡量回归模型拟合优度的一个很好的指标,R² 越高,模型拟合度越好。从上图可以看出,adjusted R²= 0.2084,这意味着我们拟合的模型并不理想。而 p-value 则表明这些新增变量如 Item count、Outlet Count 和 Item_Type_New 对我们的模型构建并没有什么帮助,因为它们的符号远小于 0.05 的显著性水平。对模型比较重要的变量是那些 p-value 小于 0.05 的变量,也就是上图中后面带有 * 的变量。
另外我们知道变量之间存在相关性,这会影响模型的准确率,我们可以使用cor()函数看一下变量之间的相关性。如下:
cor(新列车)
另外,你也可以使用 corrplot 包来做相关系数。下面的程序可以帮助我们找到两个具有强共线性的变量
可以看出变量Outlet_Count与变量Outlet_Type_Grocery Store呈高度负相关。另外,通过刚才的分析我们发现模型中存在一些问题:
接下来,我们尝试创建一个更大的回归模型,无需编码和新变量。它如下:
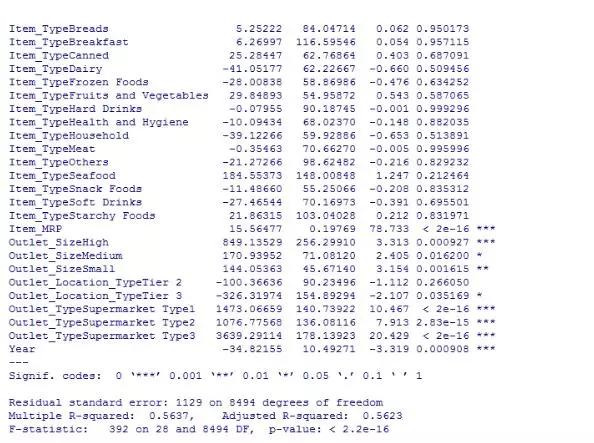
如上图所示,调整后的 R² = 0.5623。这告诉我们,有时只需简化计算过程,就可以获得更准确的结果。让我们从一些回归图中找出一些提高模型准确性的方法。
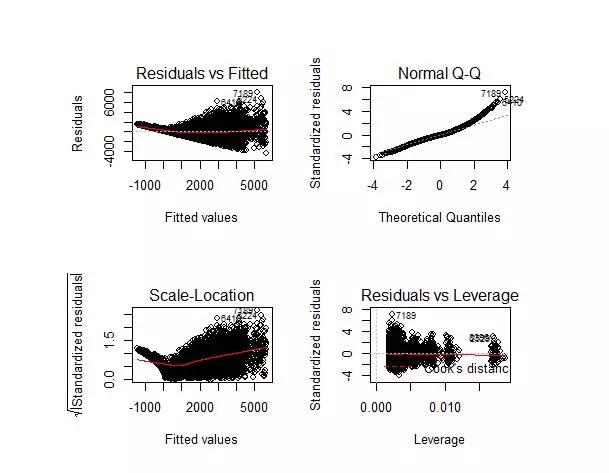
从左上角第一个残差拟合图我们可以看出,实际值和预测值之间的残差不是常数,这表明模型存在异方差。解决异方差的一个常用方法是对响应变量取对数(以减少误差)。
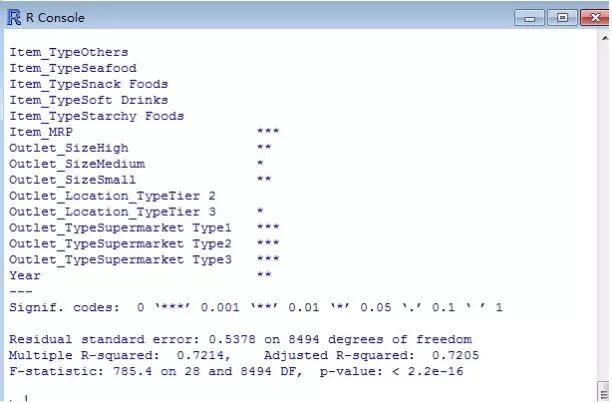
可以看出调整后的R²=0.72,说明模型的构建得到了明显改善。我们可以再画出拟合的回归图
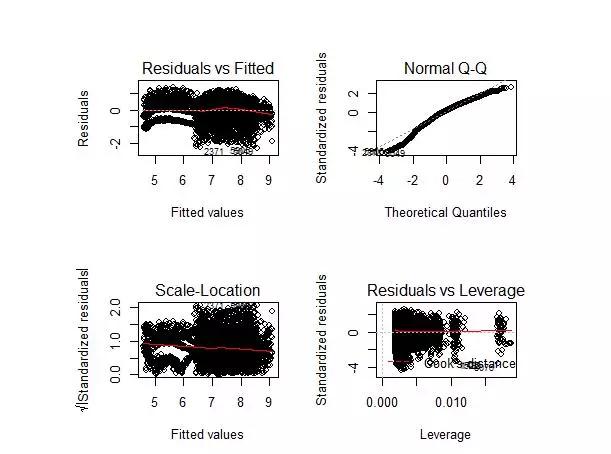
上图中残差值与拟合值之间没有长期趋势,说明模型拟合效果比较理想。我们也经常用RMSE来衡量模型的好坏,可以用这个值来和其他算法进行比较。如下图
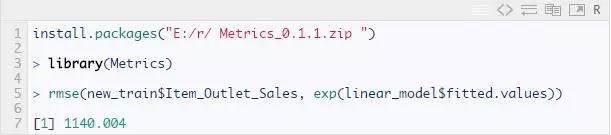
接下来让我们执行决策树算法来提高 RMSE 分数
2.决策树
决策树算法一般比线性回归模型效果要好。我们先简单介绍一下,在机器学习中,决策树是一种预测模型。它表示对象属性和对象值之间的映射关系。树中的每个节点代表一个对象,每条分叉路径代表一个可能的属性值,每个叶子节点对应从根节点到叶子节点的路径所代表的对象的值。
在 R 中,决策树算法可以使用 rpart 包来实现。另外,我们会使用 caret 包进行交叉验证。交叉验证技巧可以用来构建更复杂的模型,使得模型更不容易过拟合。(读者可以参考交叉验证获取更多信息)另外,决策树使用参数 CP 来衡量训练集的复杂度和准确率。较小的 CP 值可能导致决策树较大,这也可能导致模型过拟合。相反,较大的 CP 值也会导致模型欠拟合,即我们无法准确掌握所需变量的信息。下面我们使用五折交叉验证的方法来寻找具有最佳 CP 的模型。

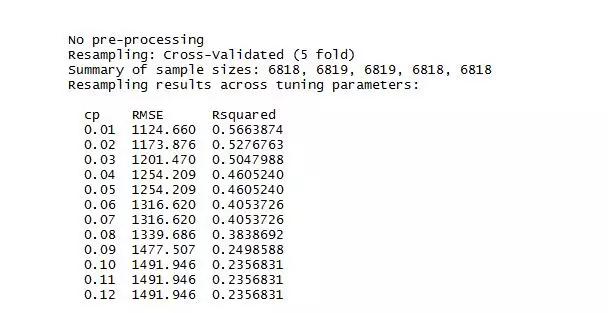
从上图可以看出,参数cp = 0.01对应的RMSE最小,这里我们只提供了部分数据,大家可以在R控制台中查询更多信息。
1主树
#在cp=0.01下构建决策树
prp(main_tree) #输出决策树
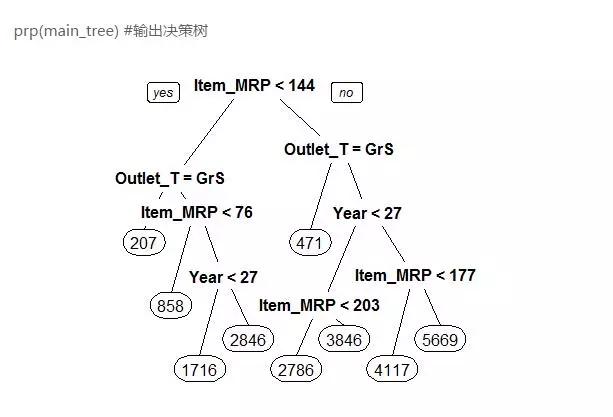
以上就是我们的决策树模型的结构,我们可以清楚的看到变量Item_MRP是最重要的根节点,因为最重要的变量是根节点,用来划分预测的未来销量。另外我们来看看这个模型的RMSE是否有所提升。

可以看到决策树得到的误差为1102.774,比线性回归得到的误差要小,说明这个方法效果比较好,当然你也可以通过调整参数来进一步优化降低这个误差(比如使用10倍交叉验证的方法)
3.随机森林
随机森林顾名思义就是用随机的方式建立一个森林,森林里有很多棵决策树,随机森林里每棵决策树之间没有相关性。得到森林之后,当有新的输入样本进入时,森林里的每一棵决策树都会做一个判断,看这个样本应该属于哪个类别(对于分类算法来说),然后看哪个类别被选中的最多,就把样本预测到那个类别。随机森林算法可以很好的处理缺失值,异常值等非线性数据,读者可以自行参考其他相关知识。

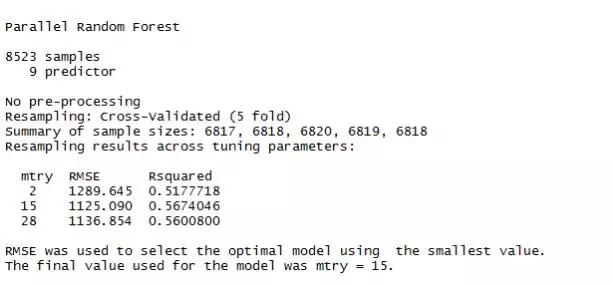
在上面的语句中,你可以看到 = “parRF”,这是随机森林的并行实现。这个包可以让你花更少的时间计算随机森林。或者,你也可以尝试使用 rf 方法作为标准随机森林的函数。从上面的结果中,我们选择 RMSE 最小的一个,也就是 mtry = 15。我们尝试用 1000 棵树来计算,如下所示:

该模型的RMSE为1132.04,此外,它没有改善决策树模型,从下面的图中显示,随机森林的功能之一是显示最重要的变量。
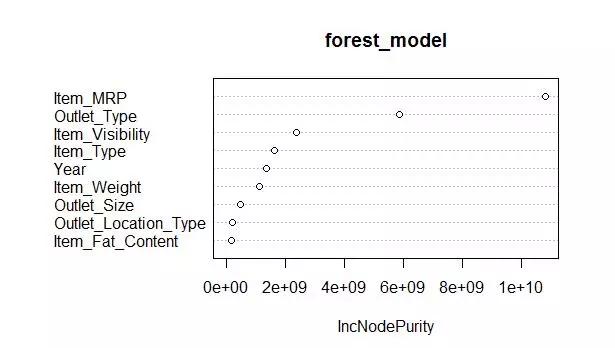
显然,该模型可以进一步优化,同时r软件教程,我们将测试集与最佳RMSE一起使用。

预测其他样本数据时,我们可以通过调整参数来优化此模型的RMSE。
如果您有任何可以使模型预测更好的新方法,请随时讨论它们。
