雷锋网 AI 科技评论:人类非常擅长在嘈杂的环境中“压制”其他不重要的声音,从而将注意力集中在特定的人身上。这也被称为“鸡尾酒会效应”,这种能力是人类与生俱来的。然而,自动语音分离系统——将音频信号分离成单独的语音源——虽然这是一个已经被深入研究的问题,但它仍然是计算机系统研究的巨大挑战。
4月11日,Google Research软件工程师Inbar Mosseri和Oran Lang发表博文,介绍了他们在视音频语音识别分离模型方面的最新研究成果。雷锋网AI科技评论对其进行了编译整理如下。
在解决“鸡尾酒会效应”的论文《鸡尾酒会上的倾听:一种不依赖说话人的音频-视觉语音分离模型》中声音处理软件分离频率,谷歌团队提供了一种深度视音频学习模型,用于从说话人音频和背景噪音的混合音频场景中分离出特定发声对象的匹配单音频信号。在这个操作中,谷歌已经能够通过增强特定人物对象的音频并抑制其他非关键音频来计算并生成特定发声对象的单音轨视频。这种方法适用于常见的单(主)音轨视频。用户也可以选择聆听对象为其生成单音轨,或者算法可以根据上下文选择特定发声对象。谷歌认为,这种视音频语音识别分离技术具有广泛的应用场景,可以识别视频中的特定对象并增强其音频,尤其是在多人视频会议场景中可以针对特定说话人进行有针对性的音频增强。
该技术的独特之处在于结合对输入视频的音频和视频信号的分析声音处理软件分离频率,识别出需要分离的单个音轨。直观上,例如,特定人物对象的音频与其说话时的嘴部动作相关联,这有助于模型系统区分哪部分音频(音轨)对应哪个特定对象。分析视频中的视觉信号不仅可以在多个音频混合的场景下显著提高语音识别分离的质量(相比仅使用音频分离特定对象的语音),更重要的是,它还可以将分离出的纯单个音轨与视频中的视觉对象相关联。
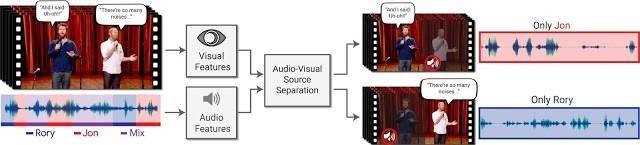
本文的视音频语音分离与识别方法中,输入是一段包含一个或多个发声对象的视频,视频中会受到其他对象或噪声背景的干扰,输出则是将之前输入的视频音轨分解为与特定发声对象对应的纯音轨。视音频语音识别分离模型
为了生成视音频语音分离模型的训练样本,谷歌在 Youtube 上收集了多达 10 万个高质量的学术和讲座视频。团队从中抽取了一些纯音频的片段(例如,没有背景音乐、观众噪音和其他演讲者的音频干扰),这些视频片段中只有一个可见的演讲者。谷歌花费了大约 2000 个小时编辑没有背景噪音干扰、只有一个可见演讲者的视频数据。团队利用这些干净的数据生成了“合成鸡尾酒会”——将分离视频源的面部动作视频和相应的音频与从 AudioSet 获得的无背景噪音视频混合在一起。
利用这些视频数据,我们能够训练一个多流卷积神经网络模型,从而分离出《鸡尾酒会场景合成》片段中每个说话者对应的音频流(音轨)。视音频网络识别系统的数据输入具体是指从视频每帧中检测到的说话者面部动作缩略图中提取出的视觉特征,以及视频音轨的声谱图信息。在模型的训练过程中,网络系统学会分别对视觉和音频信号进行编码,然后将它们融合成一个视音频表征。从视音频表征中,网络系统学会输出每个说话者的时频掩码。输出的时频掩码与有噪声的输入声谱图相乘,然后转换为时域波形,从而为每个说话者生成单独的、干净的音频信号。更多详细信息,可以点击参考Google团队的论文《鸡尾酒会上的倾听:一种独立于说话者的语音分离视音频模型》查看。
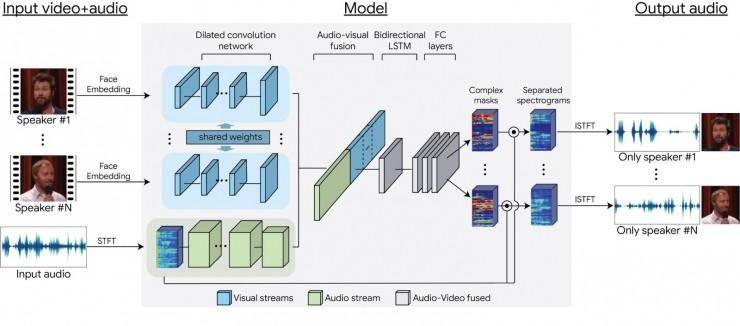
Google Multi-Stream,一种基于神经网络的模型架构
以下是谷歌团队利用最新视音频语音分离技术实现的音频分离和增强效果的几个视频示例。视频中,除了需要的特定发声物体外,其他物体(背景)的声音都被“静音”以达到预期的效果。
视频示例(截图)
视频示例(截图)
视频示例(截图)
为了突出该模型对视觉信息的利用,谷歌从谷歌首席执行官 Sundar Pichai 的同一段视频中截取了两个截然不同的片段并并排演示。在这种情况下,仅使用音频中的特征语音频率很难分离音频,尽管在如此具有挑战性的情况下,视音频模型仍然可以正确地将音频与视频分离。
视音频语音识别分离技术相关应用
该方法还可应用于语音识别和视频自动字幕加载。对于视频自动字幕加载系统来说,多个说话者同时说话导致的语音重叠是一个已知的挑战。同时,将音频分离成不同的源也有助于呈现更准确和可读的字幕。
你也可以前往YouTube观看本文中的同一段视频,并开启字幕加载(cc功能键),来比较使用视音频语音识别分离技术的视频字幕识别与YouTube原版视频字幕加载系统的性能。
视频示例(截图)

读者还可以在 Google 视音频语音识别分离项目 GitHub 页面上查看更多应用场景,以及 Google 视音频语音识别分离技术与纯音频识别分离的视频示例对比,以及其他视音频语音识别分离技术的最新进展。在 Google 团队看来,这项技术将有更广泛的应用,团队也在探索将其融入 Google 其他产品中,敬请期待!
此外,《AI技术评论》还整理了微软AI与研究院研究人员4月初发表的关于利用多波束深度吸引子网络解决鸡尾酒会问题的论文,详情可参阅《微软研究人员提出多波束深度吸引子网络解决语音识别中的‘鸡尾酒会问题’》。
