第一部分 引言 1.1 本文主要内容
在上一篇推送中我们介绍了基于base R完成数据处理的方法;在这篇推送中我们将介绍基于tidyverse完成数据处理的方法。本文主要内容包括:
基本数据操作,包括过滤、修改和排序;
数据合并,包括垂直合并、水平合并、跨表连接;
数据变换,即长宽表变换;
数据聚合,包括组排序、组过滤和组聚合。
注:tidyverse 是一套专为数据科学设计的 R 包集合,其核心包包括 ggplot2、tibble、tidyr、dplyr 等,简洁、高效、流水线操作是其基本特点,极大地推动了 R 语言的发展。
本文继续使用上一篇文章中的 gapminder 数据集,主要使用的 R 包是 tidyverse 中的 dplyr 和 tidyr。
# install.packages('tidyverse')
library(tidyverse)
1.2 管道操作员
管道操作符 %>% 是本文代码中比较重要的部分,我们先通过一个小例子来理解一下:
c(-1,2,3,4) %>%
abs() %>%
mean()#输出结果为2.5
管道运算符 %>%(RStudio 中的快捷键是 ctrl+shift+M)用于将左边的运算结果作为输入传递给右边的函数(默认情况下作为右边函数的第一个参数),该代码实现的操作为:
创建向量c(-1,2,3,4);
取向量的绝对值;
取向量绝对值后再取平均值。
此代码在没有管道运算符的情况下实现如下:
#逼死强迫症
mean(abs(c(-1,2,3,4)))#输出结果为2.5
或者:
a=c(-1,2,3,4)
b=abs(a)
c=mean(b)
c#输出结果为2.5
相比之下,管道操作符的优势就很明显了:
避免使用过多的中间变量;
增强程序的可读性!
注:R语言中的管道操作符是由magrittr包引入的,最常见的管道操作符是%>%;除了%>%之外,%T>%、%$%和%%也属于管道操作符,其含义和%>%不同统计软件教程 李东风,有兴趣的同学可以自行查看;|>的作用和%>%大致相同,但是我们建议使用%>%。
第二部分 基本操作 2.1 选择列(select)
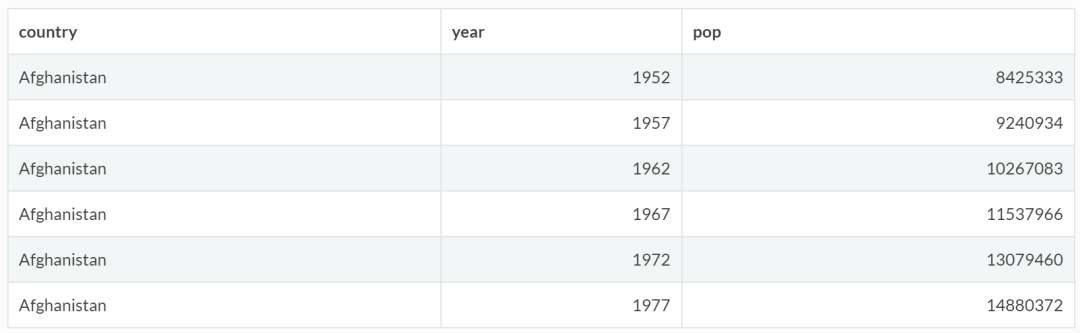
(1)结果不重复,比如筛选各年度所有国家的人口数据:
gapminder %>%
select(country,year,pop) %>%
head()
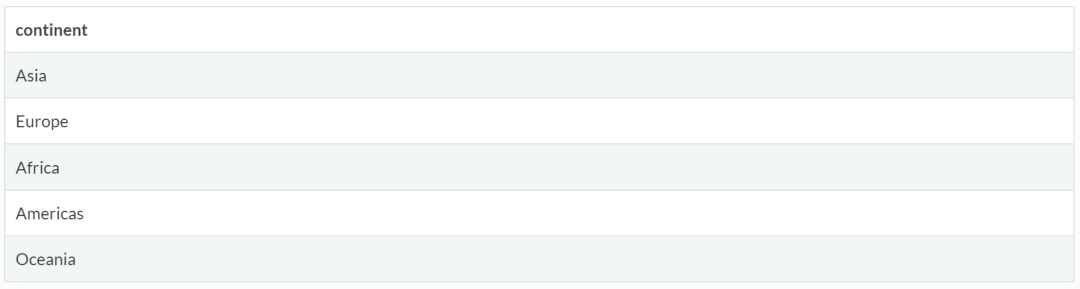
(2)结果重复,需要去除,比如过滤数据中所有大洲:
gapminder %>%
select(continent) %>%
distinct() #去掉重复项
2.2 选择行(过滤)
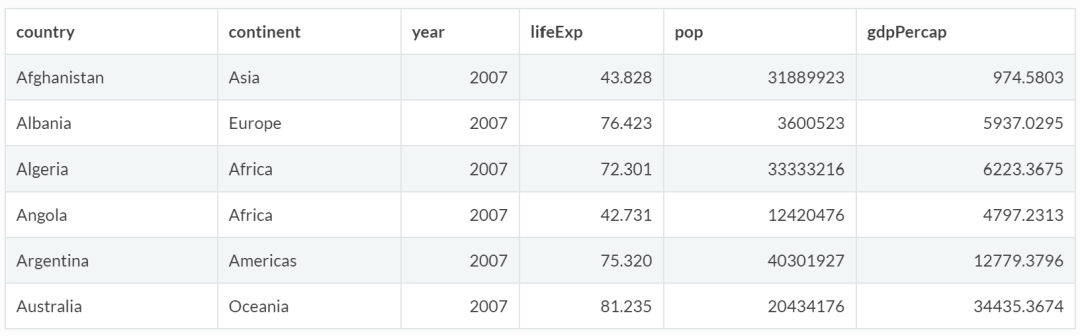
(1)使用单一条件过滤行,例如选择 2007 年所有国家的数据:
gapminder %>%
filter(year == 2007) %>%
head() #这里简要列出前6条
(2)使用多条件筛选行,例如选中中国2002年的数据和美国1992年的数据,其中|代表“或”,&代表“和”:
gapminder %>%
filter((year==2002&country =="China") | (year==1992&country =="United States"))

值得注意的是,如果选择的变量是因子或者字符类型,则需要加上引号,比如这里的“中国”和“美国”。
2.3 修改(变异)
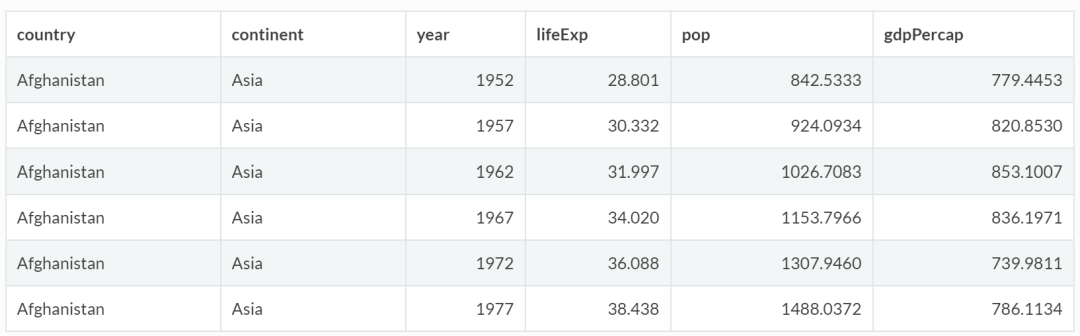
(1)在不创建新变量的情况下,修改原表中的列,如将人口由“人”改为“万人”:
gapminder %>%
mutate(pop = pop/10000) %>%
head()
(2)修改列并创建新变量,例如增加一个变量“pop_w”,表示以“10,000”为单位的人口:
gapminder %>%
mutate(pop_w = pop/10000) %>%
head()
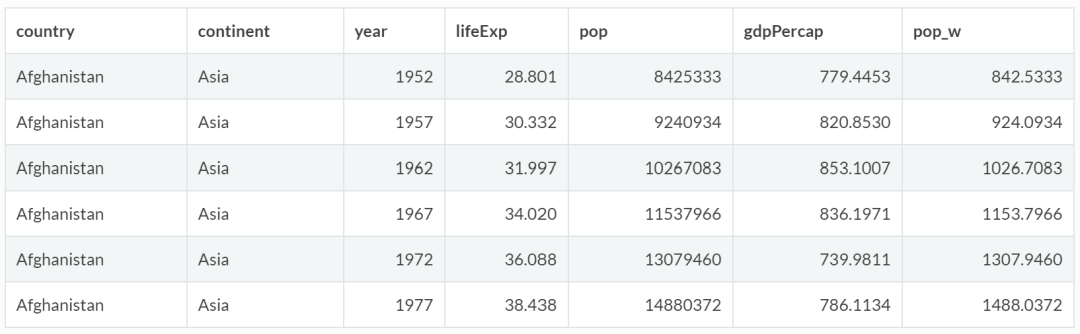
2.4 安排
accordion 函数默认为升序,使用 desc 函数可实现降序排列。例如,将所有国家按平均寿命升序和降序排列:
gapminder %>%
arrange(lifeExp) %>%
head()
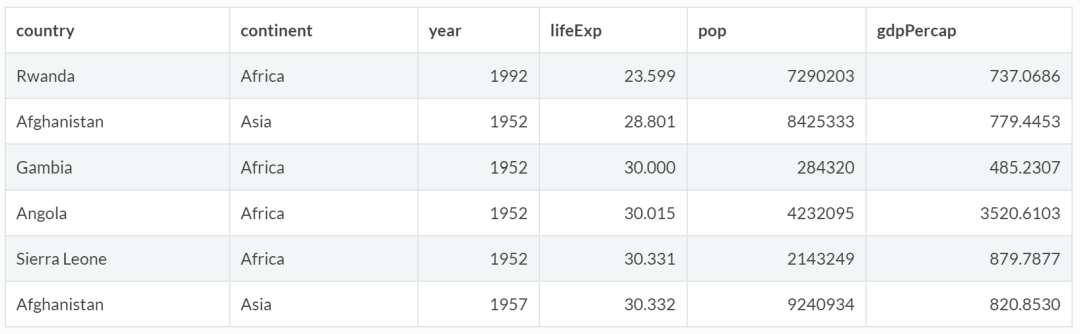
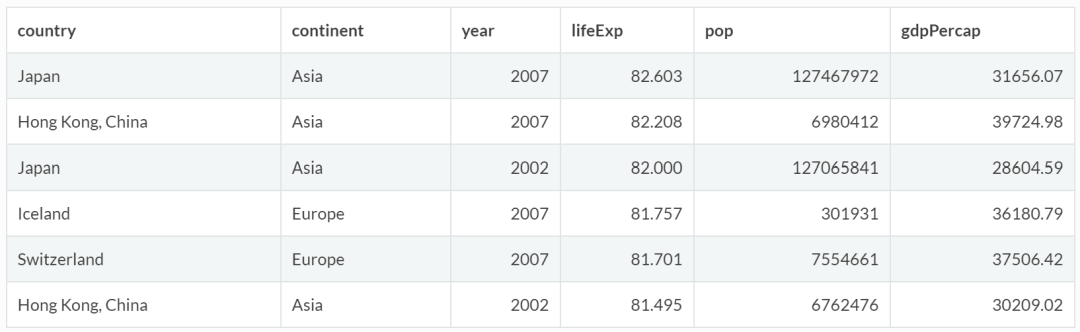
gapminder %>%
arrange(desc(lifeExp)) %>%
head()
2.5 基本操作的综合运用
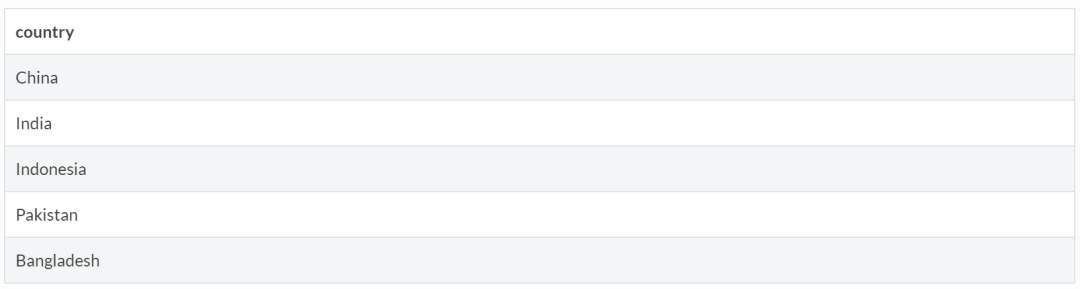
例子:筛选出2007年亚洲人口最多的五个国家。
gapminder %>%
filter(continent=='Asia' & year==2007) %>%
arrange(desc(pop)) %>%
select(country) %>%
head(5)
第 3 部分 数据合并
数据合并是指将两个或多个数据框合并为一个。常见的合并方法有两种:
直接合并行或列;
按值匹配进行合并,即连接。
下面的例子解释了这两种合并方法。
3.1 直接垂直合并(bind_rows)
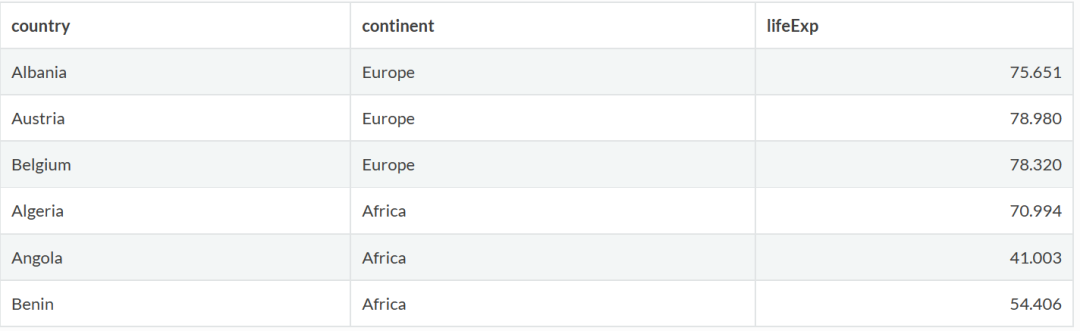
下面两个数据框Europe和Africa分别包含了欧洲和非洲前三个国家2002年的预期寿命信息,但是两个数据框的列顺序不同:
Europe <- gapminder %>%
filter(continent == 'Europe',year == '2002') %>%
select('country','continent','lifeExp') %>%
head(3)
Europe

Africa <- gapminder %>%
filter(continent == 'Africa',year == '2002') %>%
select('lifeExp','continent','country') %>%
head(3)
Africa

使用 bind_rows 根据列名垂直合并两个数据框 Europe 和 Africa,即使两个表的列顺序不同:
Europe %>% bind_rows(Africa)
笔记:
如果两个数据框中同名列的数据类型不同,bind_rows会直接报错;
与bind_rows不同,基础包中的rbind函数按顺序垂直合并两个数据框。
水平(bind_cols)
life 数据框包含 2002 年巴西和日本的预期寿命数据,gdp 数据框包含 2002 年巴西和加拿大的人均 GDP 数据:
life=gapminder %>%
filter(year==2002) %>%
filter(country=='Brazil' | country=='Japan') %>%
select(country,lifeExp)
life
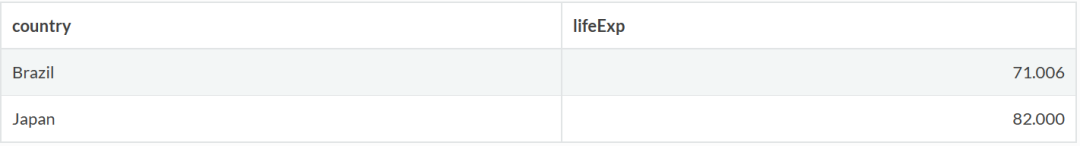
gdp=gapminder %>%
filter(year==2002) %>%
filter(country=='Brazil' | country=='Canada') %>%
select(country,gdpPercap)
gdp

与 bind_rows 函数不同,bind_cols 水平合并两个数据框,完全根据位置匹配。两个数据框中的行数必须相同:
life %>%
bind_cols(gdp)
上述合并导致了列名冲突,在实际中不建议这么做。

3.2 加入
与上面不同的是,join功能类根据两个表的共同属性进行等值匹配,将两个表合并,然后根据不同的连接方式保留不同的行。
左连接(left_join)和右连接(right_join)
左连接意味着匹配两个表并保留左表中的所有行:
life %>%
left_join(gdp,by = 'country')

left_join的调用方式为:left_join(x,y,by)。x、y分别为左表和右表,by为join中共同的属性列。显示左表全部数据,只显示右表数据共同的部分,若没有对应部分则补全显示(如上例中日本的人均GDP)。
相对于左连接来说,右连接函数为right_join,将两个表进行匹配后,显示右表的全部数据。
内连接(inner_join)和全连接(full_join)
内连接(inner_join)只保留左右表匹配的行;而全连接(full_join)会保留所有的行,如果没有对应的部分则填充空白:
life %>%
inner_join(gdp,by="country")#内连接

life %>%
full_join(gdp,by="country")#全连接

第 4 部分 数据转换
本节主要介绍长表与宽表之间的转换,以满足不同情况下的应用需求。
4.1 长表与宽表 长表
长表一般是指数据集中变量细分不清晰的情况,即至少有一个变量存在严重的取值循环,变量很少,观测值很多,例如:
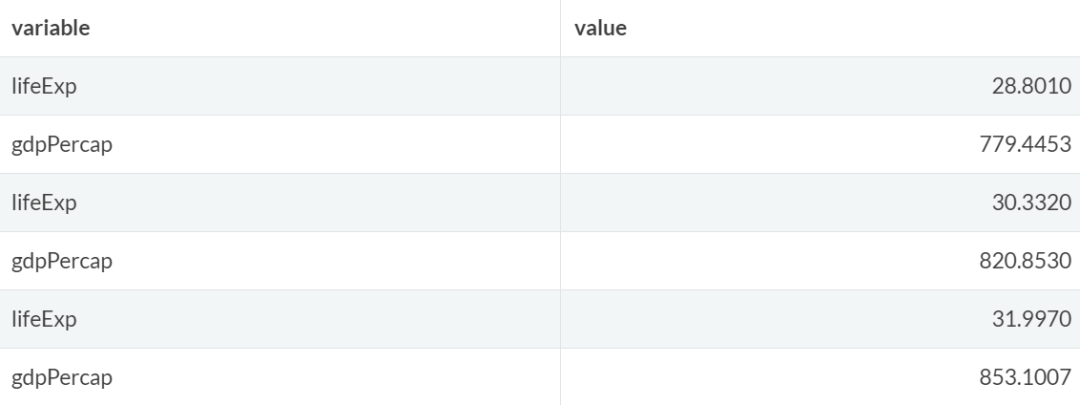
当使用ggplot2等包或tableau等BI工具进行绘图时,将数据转换成长表格式会更加方便。
宽表
宽表一般是指所有变量已经明确分割的数据集,各变量值不重复,无法分类,变量较多但观测值较少。例如:
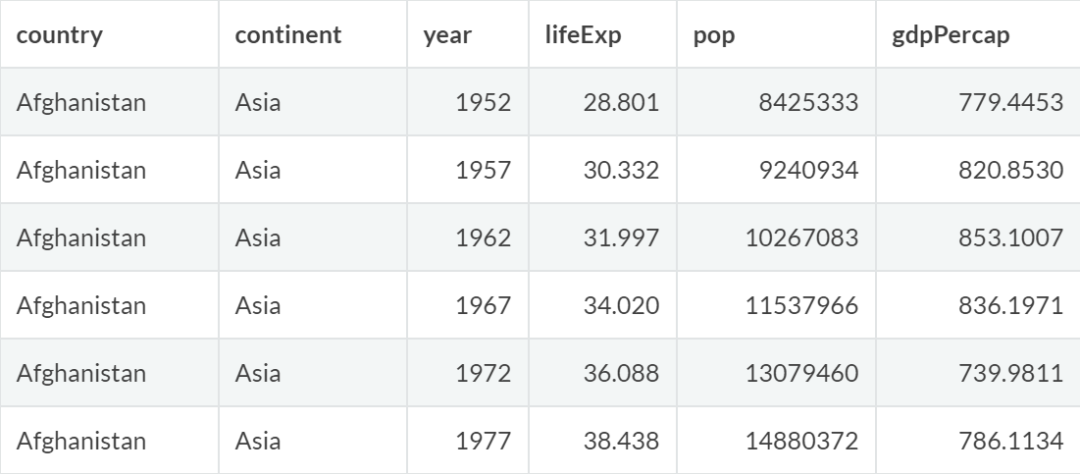
宽表格的优点是一目了然,更适合阅读统计软件教程 李东风,并且易于导入SPSS等软件进行进一步的数据处理。
4.2 将宽表转换为长表(pivot_longer)
使用 pivot_longer 函数将多个观察值水平堆叠在一列中。
单项类别
选项names_to指定新的变量名,并将原有的列标题转换为变量的值;选项values_to指定新的变量名,并将原有列对应的测量值保存在变量名的列中。
longer1 = gapminder %>%
filter(year == "1977") %>%
select(country,lifeExp,gdpPercap) %>%
pivot_longer(
cols = lifeExp:gdpPercap,
names_to = "variable",
values_to = "value")
longer1 %>% head()
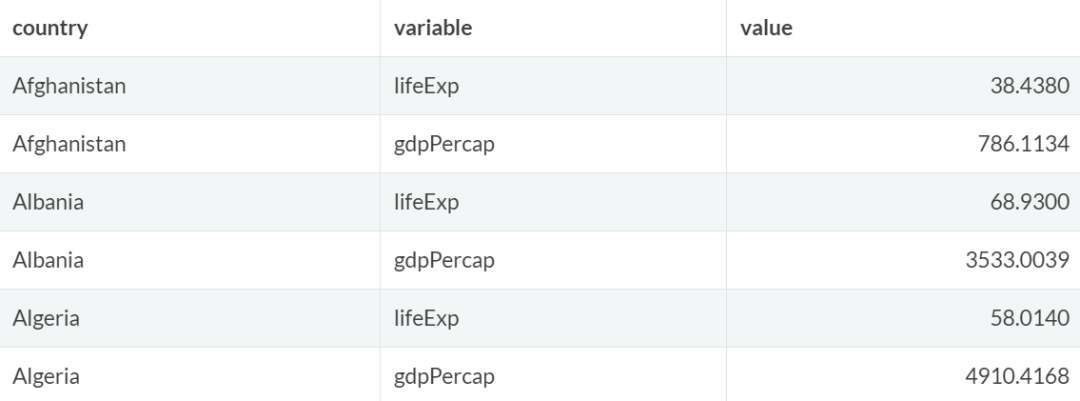
注意,要堆叠的列的数据类型应该相同,否则堆叠将失败。
从列名中提取多个变量
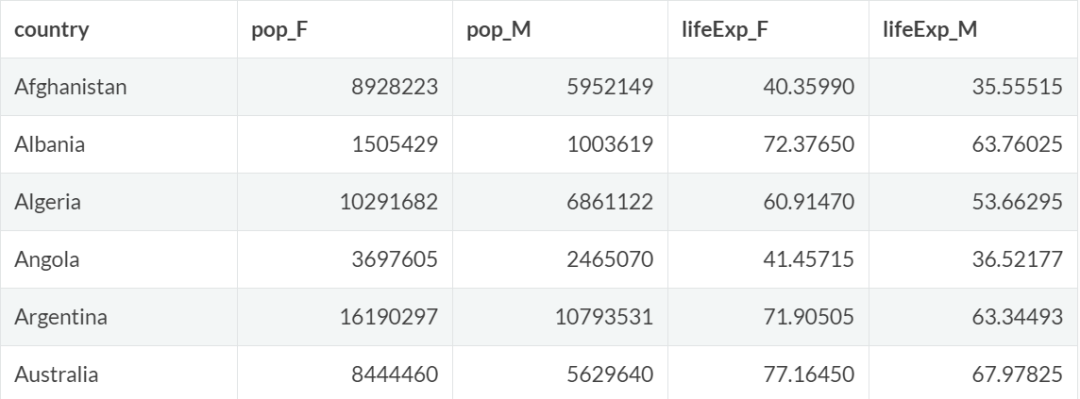
这里构建了每个性别的人口和预期寿命以供显示:
gapminder_1 = gapminder %>%
filter(year == "1977") %>%
select(country,pop,lifeExp) %>%
mutate(pop_F = pop*0.6,pop_M = pop*0.4,lifeExp_F = lifeExp*1.05,lifeExp_M = (lifeExp*pop -lifeExp_F*pop_F)/pop_M) %>%
select(country,pop_F,pop_M,lifeExp_F,lifeExp_M)
gapminder_1 %>% head()
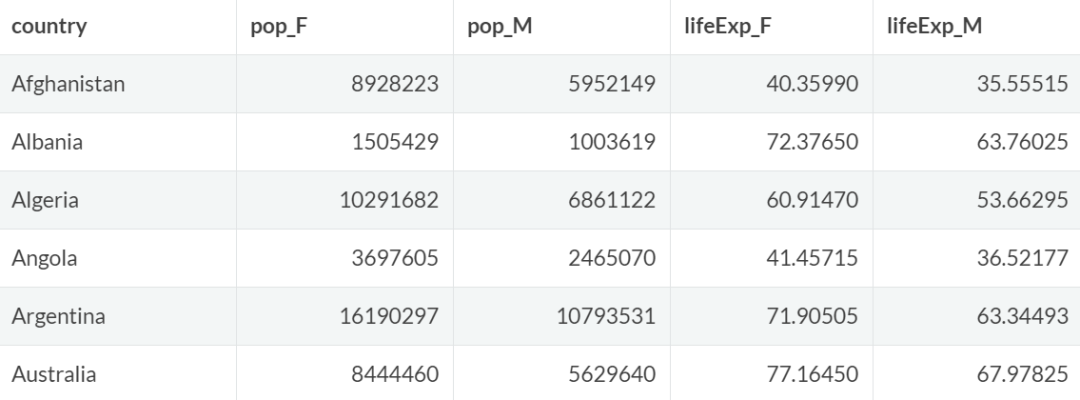
此时每个列名都包含两个信息:性别、统计指标。将这组数据按照性别和统计指标两个维度进行归类,宽表转化为长表如下。关键在于列名的切分:
longer2 = gapminder_1 %>%
pivot_longer(
cols = pop_F:lifeExp_M,
names_to = c("variable","gender"),
values_to = "value",
names_sep = "_", # 指定如何拆分列名
names_ptypes = list(
gender = c("F", "M"),
variable = c("pop", "lifeExp"))
)
longer2 %>% head()
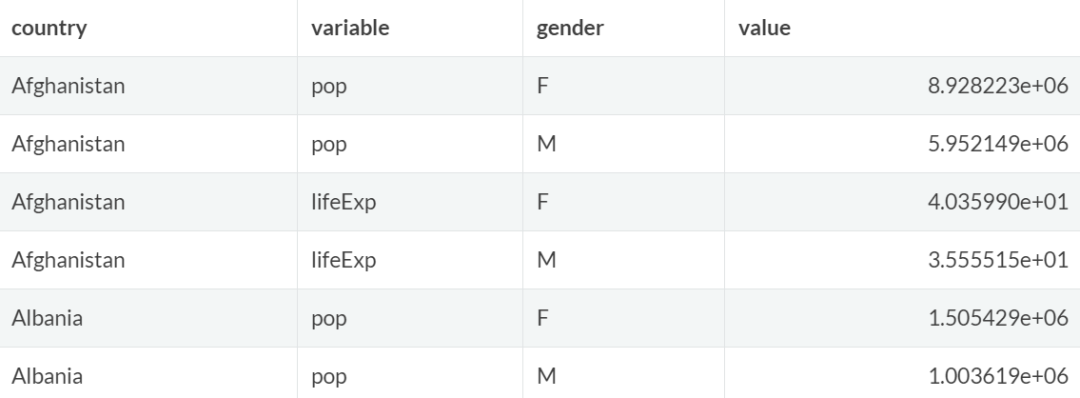
注意,names_to 的长度大于 1,需要提供 names_sep 或 names_pattern 之一来指定如何拆分列名,本例中指定了 names_sep。
4.3 将长表转换为宽表(pivot_wider)
使用pivot_wider函数将长表转换为宽表。
基本应用程序
使用names_from指定区分不同变量的列,使用values_from指定存储实际变量值的列。上文中的longer1表还原为宽表如下:
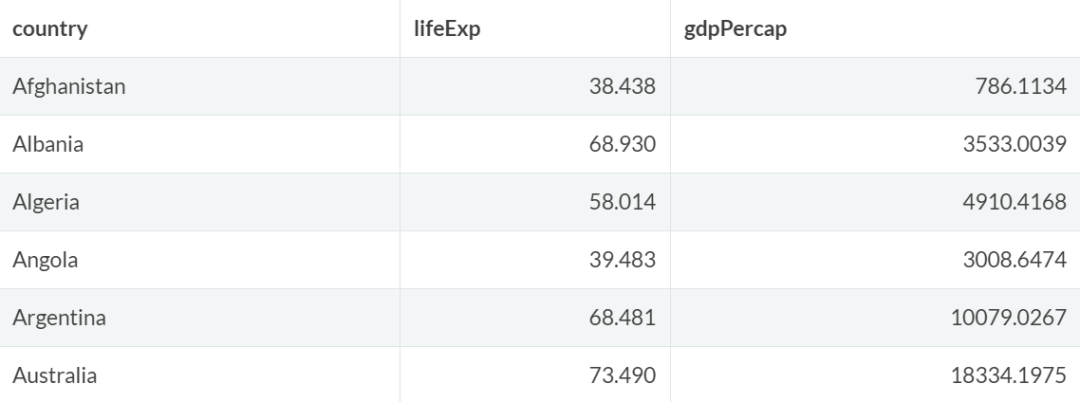
longer1 %>%
pivot_wider(
names_from = "variable",
values_from = "value") %>%
head()
将交叉类别合并为一个观察结果
为 names_from 选项指定两列,可以将包含交叉类别的长表还原为宽表,以上文中的 longer2 表为例:
longer2 %>%
pivot_wider(
names_from = c("variable","gender"),
values_from = "value") %>%
head()
第 5 部分数据摘要
通过使用group_by()函数对数据进行分组,使用summarize()函数获取统计数据,可以进一步处理数据,获取有关数据的更多信息。
5.1 数据分组(group_by)
如果您想按几列对数据进行分组,只需将列名传递到 group_by() 函数中。
单变量分组
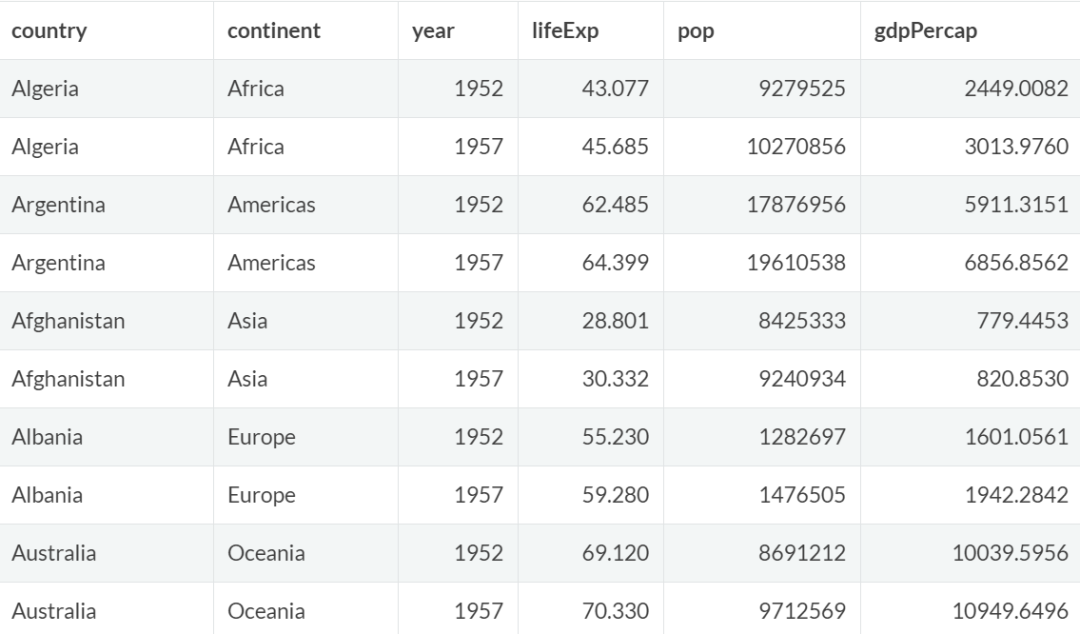
例如,按大洲对数据进行分组,并显示每组的前两条数据:
gapminder %>%
group_by(continent) %>%
slice(1:2) #每个分组内取前两条数据
多变量分组
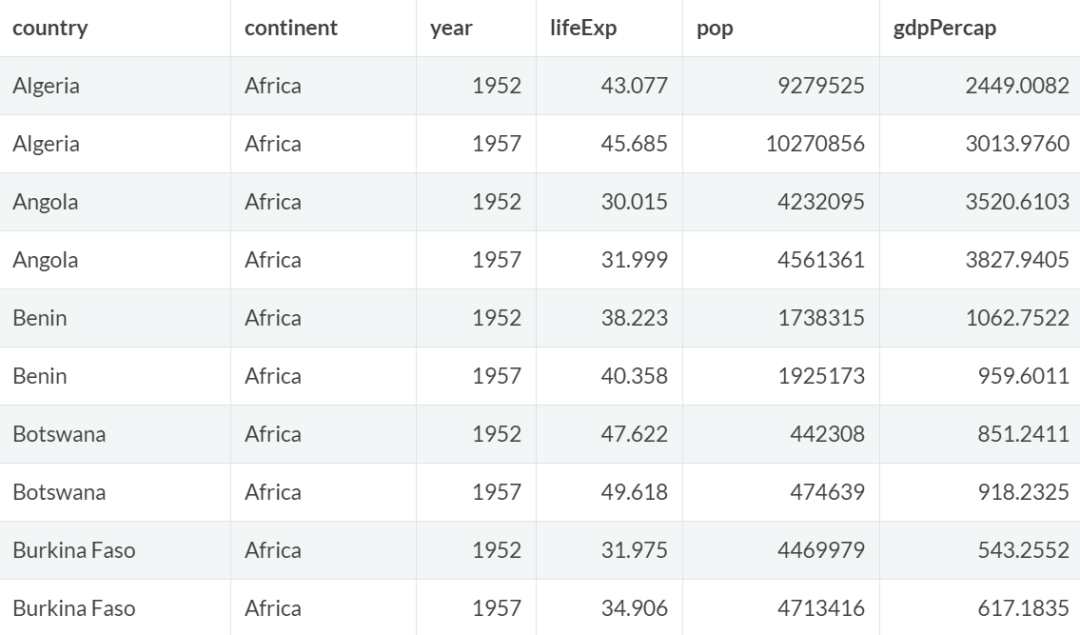
除了按单个变量分组之外,group_by()函数还支持按多个变量分组。
例如,按大洲和国家对数据进行分组,并显示每组中的前两条数据:
gapminder %>%
group_by(continent,country) %>%
slice(1:2) %>% #每个分组内取前两条数据
head(10) #只展示前10条数据
叠加分组
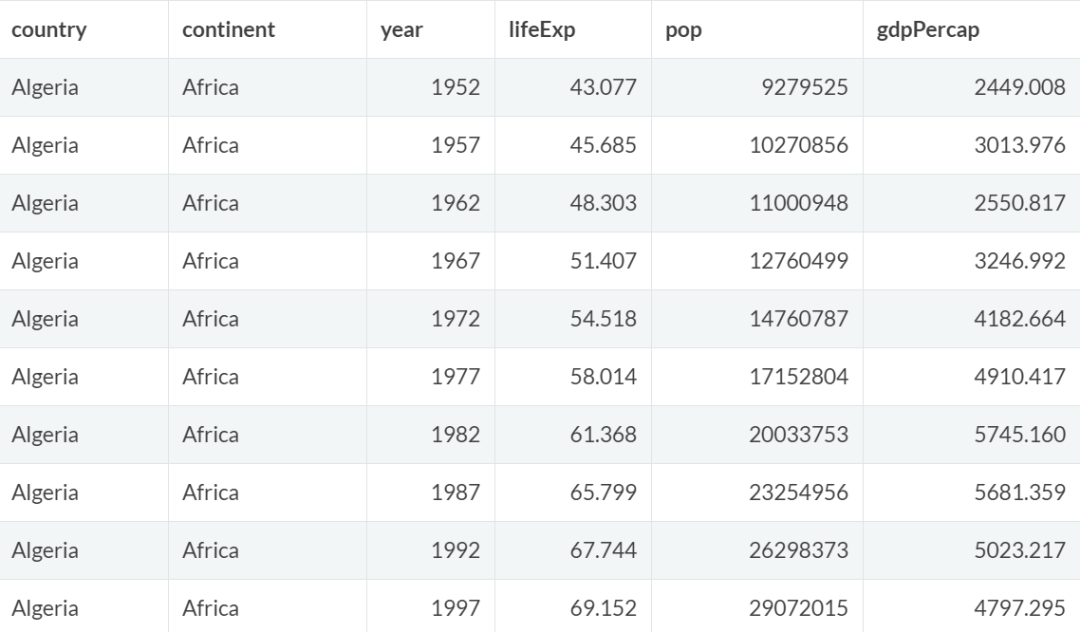
在当前版本的dplyr中,每次group_by操作都会覆盖之前的分组,之前的分组自动失效。如果想在之前的分组上叠加一个分组,需要在group_by()函数中设置参数,并添加add = T。
例如,按大洲和国家对数据进行分组后,再按年份进行分组:
# 按照continent,country,year分组
gapminder %>%
group_by(continent,country) %>%
group_by(year,add = T) %>%
slice(1:2) %>% #每个分组内取前两条数据
head(10) #只展示前10条数据
取消群组
需要注意的是,group_by操作之后,整个数据表处于分组状态,所有的操作都会基于分组进行,对组内的数据分别进行操作。如果有n个分组,那么就会得到n个结果。如果还想对原有的数据继续操作,需要使用ungroup()函数取消分组。
gapminder %>%
group_by(continent) %>%
ungroup() %>%
head(10) #只展示前10条数据
输出结果中已经没有Groups:continent的标识,说明取消分组成功。
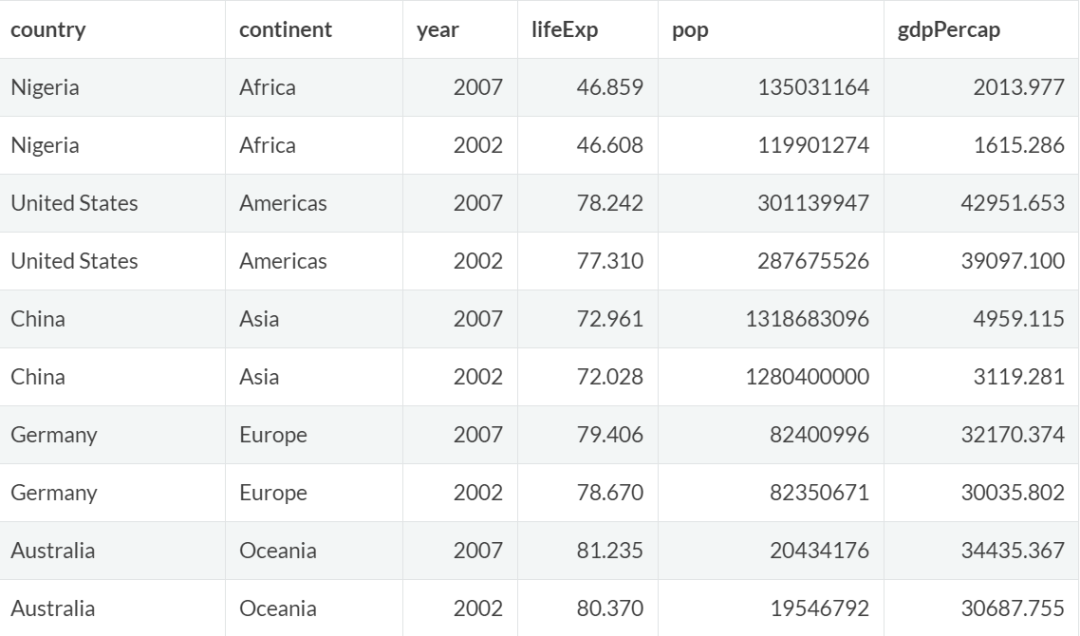
分组和排序
group_by()函数可以与arrange()函数结合使用,对数据进行分组和排序。
例如,按大洲查看人口,并显示每个大洲人口最多的两条记录:
gapminder %>%
group_by(continent) %>% # 按照continent分组
arrange(desc(pop)) %>% #根据pop做降序排列
slice(1:2) #取每组前两条记录
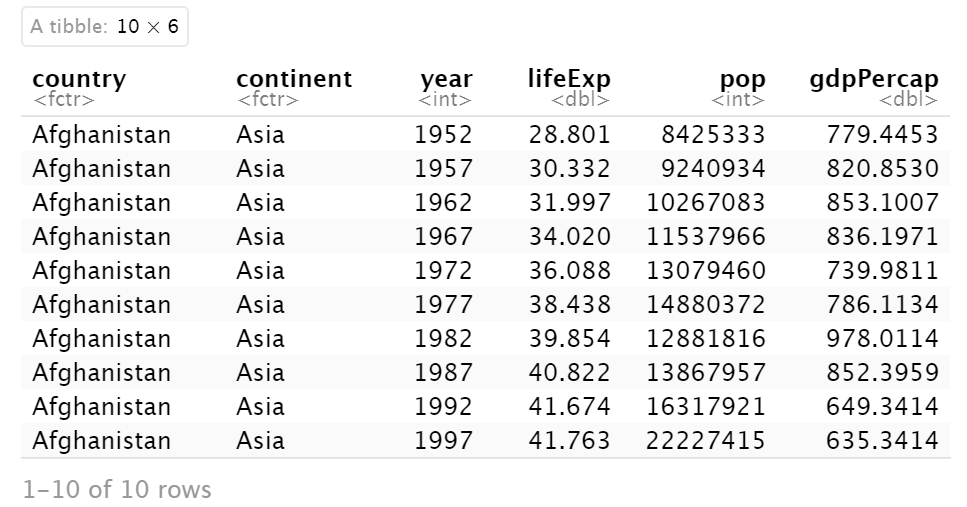
组过滤器
group_by()函数可以与filter()函数结合使用,对数据进行分组和过滤。
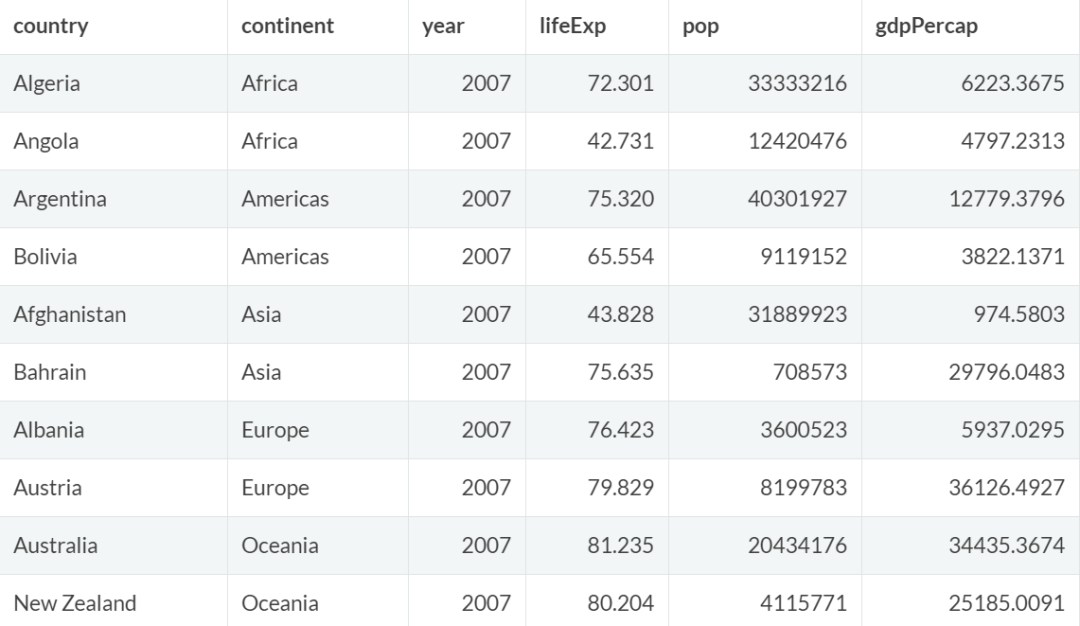
例如,让我们看看 2007 年各大洲的记录:
gapminder %>%
group_by(continent) %>% # 按照continent分组
filter(year == 2007) %>% # 筛选year
slice(1:2) #取每组前两条记录
5.2 数据汇总
如果要汇总数据并进行进一步的分析,例如获取平均值和中位数等统计数据,则需要使用summarize()函数。
summary() 几乎可以与任何聚合函数配合使用,并允许进行其他算术运算。常用的聚合函数有:
基本应用程序
生成一个附加表格,总结 1957 年所有国家的平均预期寿命。
gapminder %>%
filter(year==1957)%>%
summarize(meanLifeExp=mean(lifeExp))

小组摘要
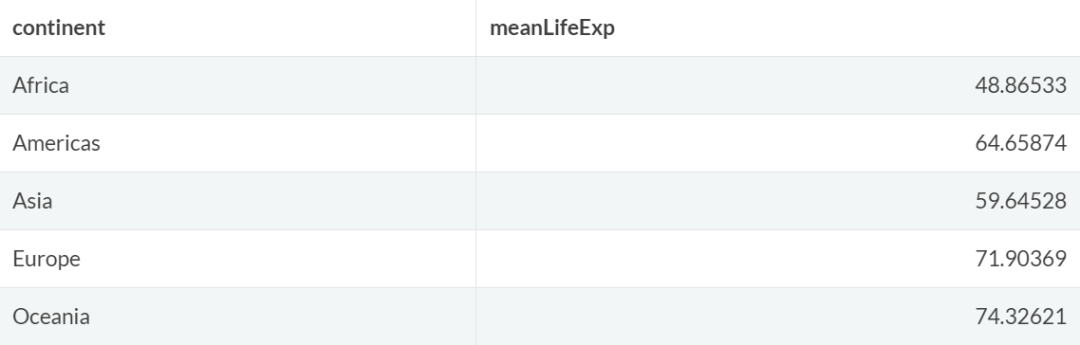
在实际应用中,我们经常会对数据进行分组和汇总,这种情况下我们需要将group_by()函数与summarize()函数结合使用。
例如,创建一个额外的表格,总结各大洲的平均预期寿命。
gapminder %>%
group_by(continent)%>%
summarize(meanLifeExp=mean(lifeExp))
例如,计算按大洲分组的国家数量和人均 GDP 最大值:
gapminder %>%
group_by(continent)%>%
summarize(CountryNum = n_distinct(country),
maxGdpPercap = max(gdpPercap))
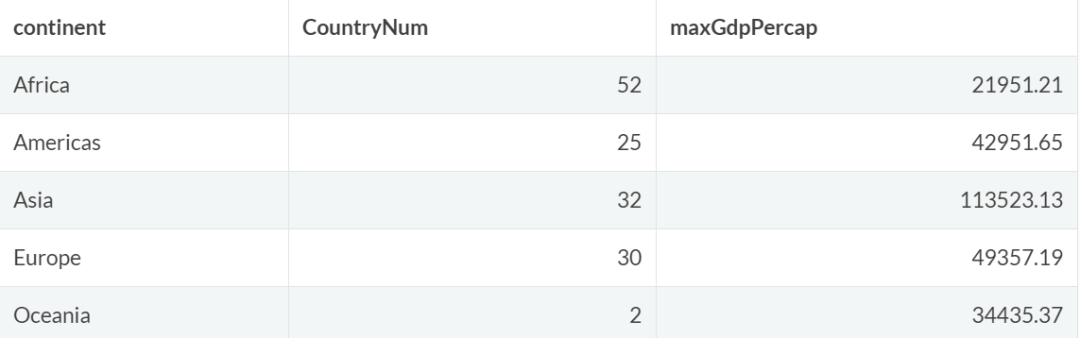
请注意,summarize 的返回值一般是一个新的数据框,这个数据框的长度一般和原数据框不一样,列数应该是 group_by 参数个数 + summary 参数个数,本例中生成的数据框有 1(group_by)+ 2(summarize)= 3 列。
以上就是基于tidyverse进行基本数据处理的简单介绍,给出的例子有限,更全面的应用和更多细节,还请读者在实践中去探索,掌握tidyverse的功能,将会成为学习和生活中的一大助力。
第 6 部分参考文献
[1] 李东风。2022. R 语言教程 27 数据管理。2023 年 3 月 8 日检索自 #dplyr-filter
[2] 李东风。2022 年。R 语言教程 28 数据摘要。检索于 2023 年 3 月 8 日,摘自
[3] 张静欣. R语言程序设计——基于tidyverse[M]. 北京: 人民邮电出版社, 2022

撰稿人:曹浩群、刘冠菁
王心凌与朱宣
黄石磊点评
题图:朱轩
未按顺序列出名称
