这是最后一篇开源软件的文章了,下周我们会推送语言相关或者项目管理相关的内容,敬请期待。以下为正文:
所谓集群系统,是指由多个进程和服务器组成的完成某种功能的系统。系统的一个重要目标就是拥有多个节点(进程或服务器),实现容灾。然而,要让大量的服务器协同工作,必须有一个中心负责组织整个集群。由于这个中心是唯一的,所以往往是一个单点。这时就出现了一个问题,如果这个单点发生故障,整个集群可能会瘫痪,而这正是成功的关键。因此,为了防止集群中心成为单点,Google 开发了著名的开源软件 ZooKeeper。
什么是 ZooKeeper

ZooKeeper是Apache Hadoop的一个子项目,其官方网站为:
它是Google Chubby 的一个开源实现,基于著名的 Paxos 算法,有兴趣可以搜索一下这个算法。ZooKeeper 主要的作用是充当集群的中心,维护集群中各个节点的配置信息,提供名字服务,实现分布式同步,这些功能的核心是一个分布式最终一致性存储系统,集群的共享信息都放在 ZooKeeper 上,这样集群中任意一个节点都可以相互协作。
ZooKeeper本身可以由多个进程组成一个服务,因此不存在单点风险。在这些进程当中,会有一个“leader”角色,为整个集群提供一致性保障。ZooKeeper服务中存储的数据都是保存在进程的内存中,同时还可以提供事务日志、持久化快照存储功能。客户端通过TCP与ZooKeeper服务进程建立连接,如果连接的ZooKeeper进程挂了,可以在ZooKeeper算法的引导下,连接到另外一个。由于ZooKeeper数据在多个服务器进程上都有复制,因此特别适合读写比为10:1的场景。
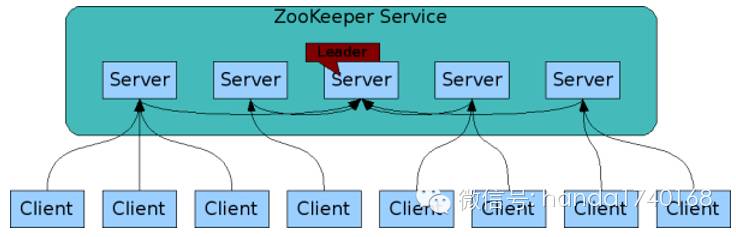
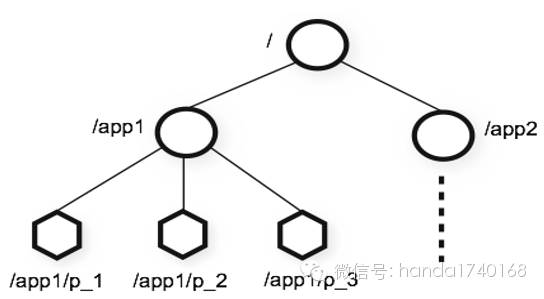
ZooKeeper 中存储的数据模型感觉就像是目录树,跟文件系统很相似,是树形结构,各个节点之间用字符串和反斜杠分隔。用户可以在“根”节点上创建多个任意名称的子节点,然后在这些子节点下创建其他子节点,或者只是在子节点下存储一些数据。这些数据都是序列化的字节数组类型,可以用来存储任意信息。
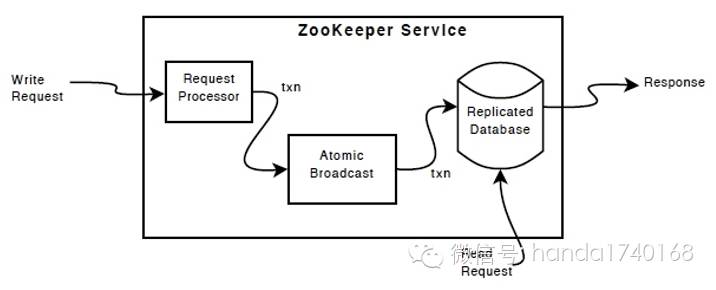
ZooKeeper内部处理请求的时候,读写是分离的:
写入数据的请求会经过一个请求处理器,然后被转发到原子广播系统,该系统会“真正地”把请求内容同步到所有节点,并更新各个节点的副本数据库,然后返回结果。
读请求比较简单,直接从节点的复制数据库读取结果就可以完成。
ZooKeeper 会在内存中保留上述树数据的完整版本,并记录写入操作到磁盘以便恢复。写入操作会先将记录写入磁盘,然后再更新内存中的状态。每个 ZooKeeper 服务进程都可以提供服务,客户端可以通过任意一个特定的服务进程提交读写请求,读操作可能通过任意一个就近的数据库副本完成,写操作则通过一致性协议进行处理。也就是说,客户端并不是一直只连接到一个 ZooKeeper 服务进程,在进行不同的读写操作时集群软件 开源,连接到不同的服务进程。那么,到底由哪个服务进程来处理写操作呢?其实都是转发给某个服务进程,这个进程被称为“leader”。这个进程写入数据后,其他进程会跟随这个进程的数据进行同步,所以被称为“follower”。因此,ZooKeeper 服务进程中就存在两个角色,一些进程负责领导,另一些进程负责跟随,从而保证数据的最终一致性。因此我们可以看出,ZooKeeper为了保证各个服务节点上数据的一致性,采用了复制数据、更新广播的方式,所以读的效率比写的效率高很多。
由于ZooKeeper是一个安全的数据同步解决方案,因此它可以提供非常高的可靠性保证:
一致性:无论客户端连接到哪个服务器,都显示的是相同的视图。
顺序性:客户端更新请求按照发出的顺序进行处理。
原子性:节点上的更新操作要么成功,要么失败。
高可用性:2n+1台机器组成的集群,即使n台机器出现故障,也不会影响系统整体的可用性。
效率:由于使用了内存镜像,读取延迟减少了。
最终一致性:经过一段时间后,客户端看到的数据是最终一致的。
ZooKeeper 的 API 看起来类似于文件系统,并提供 C 和 JAVA 接口。它们包括:
create(path,data,acl,falg) 创建一个节点
delete(path,version)删除一个节点,如果子节点不为空,则不能删除。
setData(path, data, version) 更新节点的内容
getData(path,watch) 读取节点,并在监视节点发生变化时发出通知
exist(path,watch) 判断节点是否存在
getchildren(path,watch) 获取子节点
setACL(path,acl,version) 设置 Acl
getACL(path) 获取 Acl
可以看到,基本操作和文件系统区别不大,比较特殊的是可以设置一个“监控”(watch)集群软件 开源,当集群节点数据发生变化时,可以及时通知相关客户端进程。这种主动通知方式比客户端轮询(不断刷新)状态更高效、更及时。因此,它是ZooKeeper中使用最多的功能之一。监控的具体用法为:
1.所有读操作都可以设置监听:getData()、getChildren()、exists()
2、监控定义:当监控的数据被修改时,会向设置了监控的客户端发送监控事件,监控只触发一次。
3. 仅触发一次
a) 数据改变只会向客户端发送一个监听事件,如果数据再次改变,则不会发送任何监听事件,除非客户端设置另一个监听器。
4.监测数据的设置
a) getData() 和 exist() 用于设置当前节点的监控
b) getChildren() 是设置对子节点的监控
c) setData() 将触发对当前节点的监控
d) Create() 将触发当前节点及其子节点
e) Delete()会触发当前节点及其子节点
5、若客户端与服务端断开连接,且在此期间监控的数据发生变化,则重新连接后,仍然会触发监控。
6.有一种情况会遗漏监控消息:监控某个节点是否存在,但是该节点还未创建,若是处于断开连接状态,则创建该节点,删除该节点。
7. 节点必须先监听事件,然后才能看到新数据
但也有一些问题需要注意:
因为 watch 只会触发一次,在获取事件和发送下一个 watch 之间会有延迟,所以无法可靠地监控数据的每一次变化。要小心处理在获取 watch 事件和再次设置 watch 之间节点多次变化的情况。换句话说,在获取 watch 事件之后和再次调用 getData(path,watch) 之前,您将不知道数据发生了变化。如果您只是想保持最新的数据状态,而不是每次变化过程,这没有问题。
监听事件,或者说函数上下文对,只会触发一次。例如,如果你在同一个节点上注册了exists()和getData()的监听器,当文件被删除时,你只会收到删除通知。所以你最好计划一下哪些节点监听数据变化,哪些节点监听存在性。
当你与服务器断开连接(比如服务器故障)时,你将不会得到任何监听事件,直到重新建立连接。也就是说,事件不会重播,你最好在重新连接后立即读取最新数据。
最后,这里是官方的性能数据:
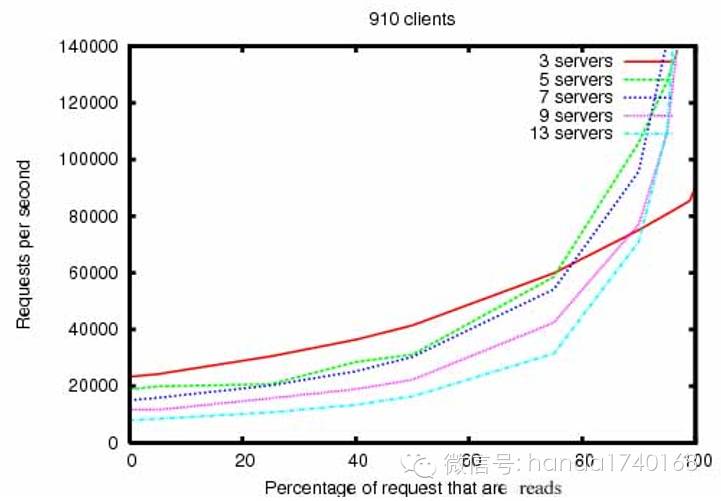
测量数据:
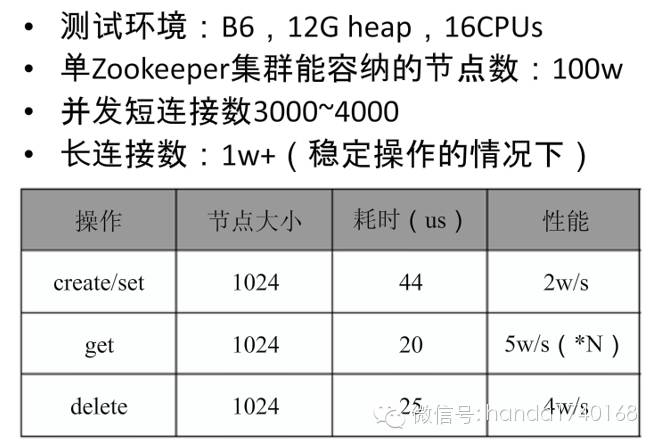
一个集群承载每秒2万次写入操作的能力其实相当低了,所以要非常小心,不要用ZooKeeper处理太多的写入操作,例如不要让它处理NoSQL或者Memcache的功能。
ZooKeeper 可以做什么
最常见的用法就是管理集群。方法是在ZooKeeper上创建一个EPHEMERAL类型的目录节点,然后各个服务器在自己创建该目录节点的父目录节点上调用getChildren(String path, boolean watch)方法,并将watch设置为true。由于是EPHEMERAL目录节点,当创建它的服务器死了,目录节点也会被删除,所以Children会发生变化。这时候就会调用getChildren上的Watch,所以其他服务器就知道某个服务器死了。这样,集群中的各个服务进程就可以通过ZooKeeper及时知道集群中有哪些进程是“活着”的。当然如果添加了新的进程,目录节点也会发生变化(创建了新的子节点),所以其他服务进程也会知道。
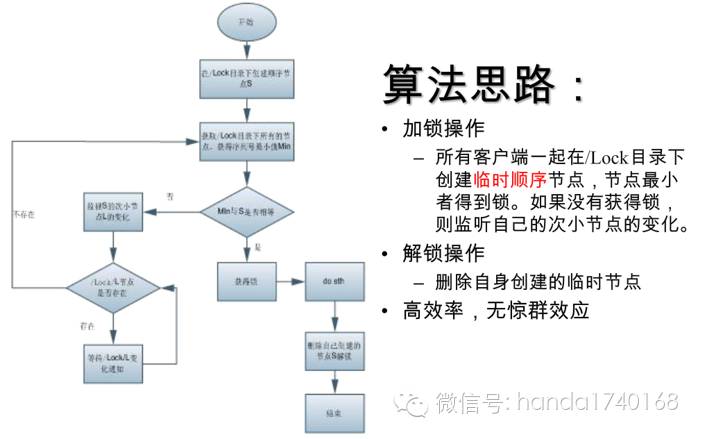
第二种用法是分布式锁:有时候在我们的集群系统中,不同的进程可能需要锁定同一个资源。比如我们的集群系统只有一个发送短信的端口,我们无法一起往这个端口发送短信。这时候就需要一把“锁”,当一个进程在发送短信时,其他所有想发送短信的进程都被锁住了,无法发送。
第三个用途很常见,就是用于配置管理。配置文件一直以来都是服务器软件的重要数据,在集群系统中,有很多数据是需要多个进程共享的。传统的做法往往是把配置文件写在服务器磁盘上,当需要修改配置时,就批量的把文件复制到各个服务器上,然后给服务进程发一些信号,让它主动重新读取配置然后生效。这个过程比较繁琐,而且容易出错,因为批量复制文件、批量发送信号,中间可能会出现错误。如果把配置信息放在ZooKeeper上,一旦修改了配置,watch机制就会触发所有进程去刷新配置。这样,我们只需要在ZooKeeper上修改配置信息,整个配置刷新过程就会自动完成。有时候我们需要同步的信息不仅仅是静态的配置信息,还有一些业务数据信息,只要写入操作不是太频繁,ZooKeeper是可以胜任的。
第四种用法是做名字服务,用来存放“名字”-“地址”的映射表。在RPC体系、SOA架构的集群中,为了让集群服务能够根据运行状况动态负载均衡或者容灾,在集群中请求服务时,往往不硬编码一个物理IP地址,而是通过服务请求的“名字”,去查询这个IP+端口地址上哪个进程可以提供该服务,然后进行连接。这种情况下,可以用ZooKeeper来承担名字查找服务的任务。由于在集群中注册服务的操作远少于查询服务地址的操作,所以用ZooKeeper来完成是非常适合的。
ZooKeeper 使用技巧
ZooKeeper 的常见错误有哪些?
ZOPERATIONTIMEOUT/ZCONNECTIONLOSS/ZSESSIONEXPIRED。前两个可以重试,而后者表示发生了严重的通信错误。
2、ZooKeeper性能相关指标有哪些?
长短连接模式 > 现有连接数 > 读写节点大小 > 读写节点深度 > 服务器上节点数。
3.ZooKeeper 在最大并发读取时可以达到什么样的性能?
12000个连接并发读取1K数据。
4、ZooKeeper的最大并发写性能是多少?
10000个连接并发写入1字节数据。5600个连接并发写入2k数据。
5.Leader故障对ZooKeeper有什么影响?
导致服务暂停1到2秒(官方说法是200ms)
6. 单个ZooKeeper节点可以写入的数据大小是多少?
标准 1MB
7.单个ZooKeeper服务器故障是否会影响服务?
没有影响,已经连接到该服务器的客户端将被转移并收到连接丢失警告。
8、ZooKeeper的瓶颈在哪里?
瓶颈就是 Leader 节点,除了只读操作外,其他操作都要经过 Leader,因此它的 CPU 是其他节点的 4 到 5 倍,网络流量也是 4 到 5 倍。大于 1MB 的数据不要写入该节点,否则 Leader 服务器的带宽很容易被耗尽。由于是 JAVA 结构的服务,Leader 的 GC(垃圾回收)操作会非常频繁。
9. 遇到超时/连接失败怎么办?
经过2到3次重试后,ZooKeeper作为集群系统在大多数情况下可以恢复。
10.删除节点或者创建节点失败怎么办?
这是一个逻辑代码问题,通常是由于子节点非空(ZooKeeper 没有 rm -rf 功能)以及父节点不存在(不允许一步构建多层节点树)导致的。
11. 如果我一直遇到连接中断的情况,该怎么办?
ZooKeeper 集群出现严重问题,或者并发连接数过多,ZooKeeper 无法接受。
ZooKeeper 作为一个严谨且最终一致的数据系统,接口非常简单,安装部署也非常容易,是搭建集群服务中心的最佳选择。只是使用时要注意不要滥用其功能,严格控制节点内数据的大小和写入操作的次数。读取操作也要控制不要太多,比如不适合作为公共的 DNS 服务器使用。如果确实需要对外提供大量的读取操作,可以对外以复制缓冲区的形式建立多个缓存服务器,开发起来也非常简单。
回顾过往亮点:
回复服务器架构 - 经典游戏服务器架构概述
回复程序员-如何提高程序员生产力
回复 RPC - 如何设计 RPC 系统
