追求系统的高可用性就像人追求身体健康一样。 整个软件开发团队必须自始至终遵循关心软件系统的态度。 及时发现并解决系统中问题的能力。

相传,魏文王与名医扁鹊有这样一段对话:
魏文王曰:“兄弟二人,谁的医术最好?”
扁鹊:“大哥最好,三弟较差,我是五人中最差的。”
” 魏文王:“那你为什么最有名呢?
扁鹊:“大哥治未病之先,病人未发病前已祛病,所以他的医术不被认可,名气不大;三哥治病之初疾病之说,三哥以药治病,你以为三哥擅长治小病,名气只在本村;而我治大病,你看我要么扎筋放血,要么敷药生殖器上的毒以毒攻毒,或者用大规模的放射治疗直接针对病灶,使重症患者的病情得到缓解或者治愈,所以我认为我的医术高超,名声传遍天下。省。”
在前面的小故事中,根据疾病发展的不同阶段医生的治疗可以分为三个阶段:
技术人员整改系统就像医生治病救人。 为了保证系统能够对外提供稳定的服务并具有较高的可用性,需要关注系统开发的整个生命周期。 了解细节,一方面可以发现软件开发中潜在的问题并尽快解决; 另一方面,当系统出现小问题时,不要忽视,及时处理; 最后软件高可用性,当系统出现重大问题时,可以使用迅雷快速恢复,保证系统可用。
为了提高系统的可用性,我们需要关注这三个阶段。 本文将试图通过分析影响系统可用性的激励因素,找出在这三个阶段我们需要采取的必要措施。
什么是系统可用性?
首先,我们看一下维基百科上关于可用性的一些定义:
可用性是系统处于工作状态的时间比例
系统可用性是判断一个系统是否能够正确地对外提供服务(可行)的能力。 我们一般用SLA(ServiceLevelAgreement)来判断系统可用性,也就是我们经常看到的几个9,对应的系统不可用时间可以参考下表:
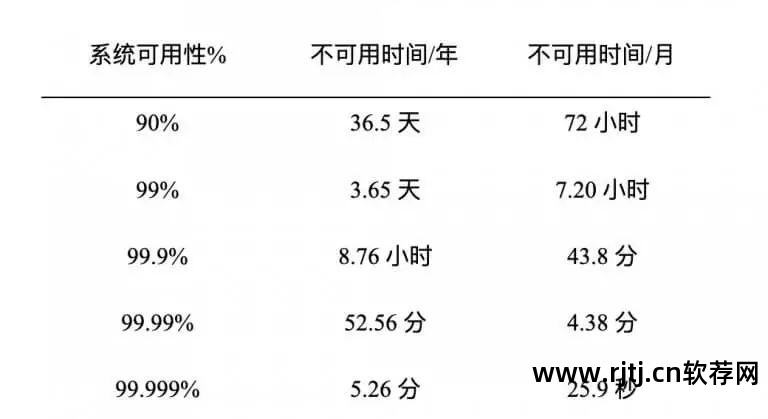
三个九(99.9%)意味着一个月的最大不可用时间不超过43.8分钟,这对于每个月例行停机维护的系统来说基本上很难实现; 五个九(99.999%)要求系统不可用的时间不超过5分钟,这听起来不可思议。
哪些触发器会影响系统的可用性
不仅是人为原因造成的故障,基础设施的定期维护、硬件设备损坏、自然洪水等都会导致系统不可用,因此100%的系统可用性基本不可能实现; 要提高系统可用性,首先要分析影响可用性的问题的原因和影响。 根据我的经验,下面列出了一些对系统可用性影响较大的原因:
人员滥用
rm-rf./等经典操作在日常开发过程中并不少见,例如:
数据和文件存储无疑是大多数企业的核心资产。 涉及数据的故障通常是非常大的故障。 除了影响范围大之外,如果前期没有足够的容灾预案,短时间内很难恢复,甚至可能难以恢复,造成巨大损失。
雪崩效应
分布式系统架构下,服务需要协作来完成复杂的业务流程。 当请求数量增加时,服务提供者的不稳定会逐渐演变成整个系统的雪崩效应。
雪崩效应一般会经历以下过程:
服务提供商不可用(宕机或性能不佳)
服务调用方请求减少(业务量减少、失败重试、缓存穿透等)
服务调用者系统资源耗尽,服务调用者不可用
雪崩可能导致整个系统瘫痪。 之前以我们的系统为例,雪崩了,一个核心服务在没有修改代码的情况下减少了用户数量(可以理解为批量向用户开放)。 当请求量较小且请求数减少时,服务的socket性能无法满足需求,请求激增对数据库造成特别大的压力(CPU被占满)。 处理其他请求,导致整个系统瘫痪,如右图:
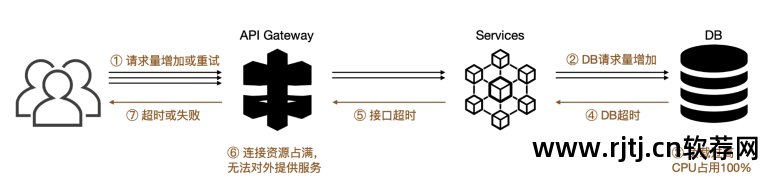
本质上来说,雪崩的发生是因为服务提供方未能满足当前业务的高并发要求,同时又没有好的对策来保证系统中其他服务的正常运行。
未经过全面测试就发布
上述两类故障的发生一般都会造成非常严重的问题,但频率比较低。 常规版本发布经常会因为缺乏完整的测试而导致上线失败。 严重的时候还会对可用性造成很大的影响。 影响。
随着系统服务周期的下降,业务量的下降使得系统变得越来越复杂。 依靠人工黑盒测试基本上很难覆盖所有业务场景(我们曾经有一个开发了3年多的系统,在没有人工标准化回归测试的情况下,每次发布后,需要四名测试人员)花费2个小时进行只读关键场景回归测试软件高可用性,成本极其高昂),这导致常规版本发布经常会带来一些意想不到的失败。 每次发布后都需要有人值班来修复此类故障。
系统之间的集成测试成本较高。 一方面,集成测试需要跨多个部门的沟通和协调。 另一方面,集成的一方一般很难了解另一方的实现细节,也很难保证全面的测试用例。 对于关键系统的集成,如果变更后没有充分的回归测试,很可能会造成影响主流程的故障,影响上线后用户的使用。
基础设施故障和定期升级和维护
无论是自建基础设施还是使用第三方云服务,基础设施故障和定期升级维护都是不可避免的,也是影响系统可用性的关键因素。
影响可用性的基础设施相关触发器包括:
如何提高系统可用性
影响系统可用性的因素有很多。 上面列出了一些典型的场景,足以让我们对影响可用性的因素有一个非常直观的了解。 为了从可行的角度讨论如何提高系统可用性,这里不考虑基础设施硬件故障等不可控的激励因素。
从以往的激励措施中不难发现,有些问题可以通过提升工程能力、优化工作流程来解决,但如何落实这些工程能力和流程也是一个非常复杂的问题。 为此我会从技术和团队两个角度来阐述如何提高系统的可用性。
从技术角度看,需要不断加强工程能力

根据可用性的定义,提高系统的可用性就是减少系统不可用的时间长度,保持系统的健康状态。 回顾文章开头的小故事,我们可以分三个阶段采取一些针对性的措施:
发病早
病情严重
从团队的角度来说,一定要有一个专注于技术的团队
在软件系统开发和维护的过程中,我们发现问题的方式有很多,比如在线故障、监控报告、评审会等,但往往很难从根本上解决问题。 最终的结果是一堆技术债务和频繁的在线故障。 虽然找到了解决问题的办法,但是在实施过程中还是会遇到很多问题。
探究原因可能比较复杂,但从团队的角度来看,一般都有团队对技术不那么严谨,对生产环境不那么敬畏,对自己的代码不那么苛刻。
要提高系统的可用性,就需要有一个专注于技术的团队。 这个团队应该具备以下特点:
结语
追求系统的高可用性就像人追求身体健康一样。 整个软件开发团队必须自始至终遵循关心软件系统的态度。 及时发现并解决系统中问题的能力。
这不仅仅是一个技术问题。 一个有良好治理体系的团队,首先要在团队内部营造尊重技术、尊重工程的文化氛围,建立团队的行为规范,严守纪律,有事有事不做; 在此基础上,在团队不断发展的过程中,我们会找到解决问题的最佳实践,做正确的事,并相信高可用性是必然的结果。
