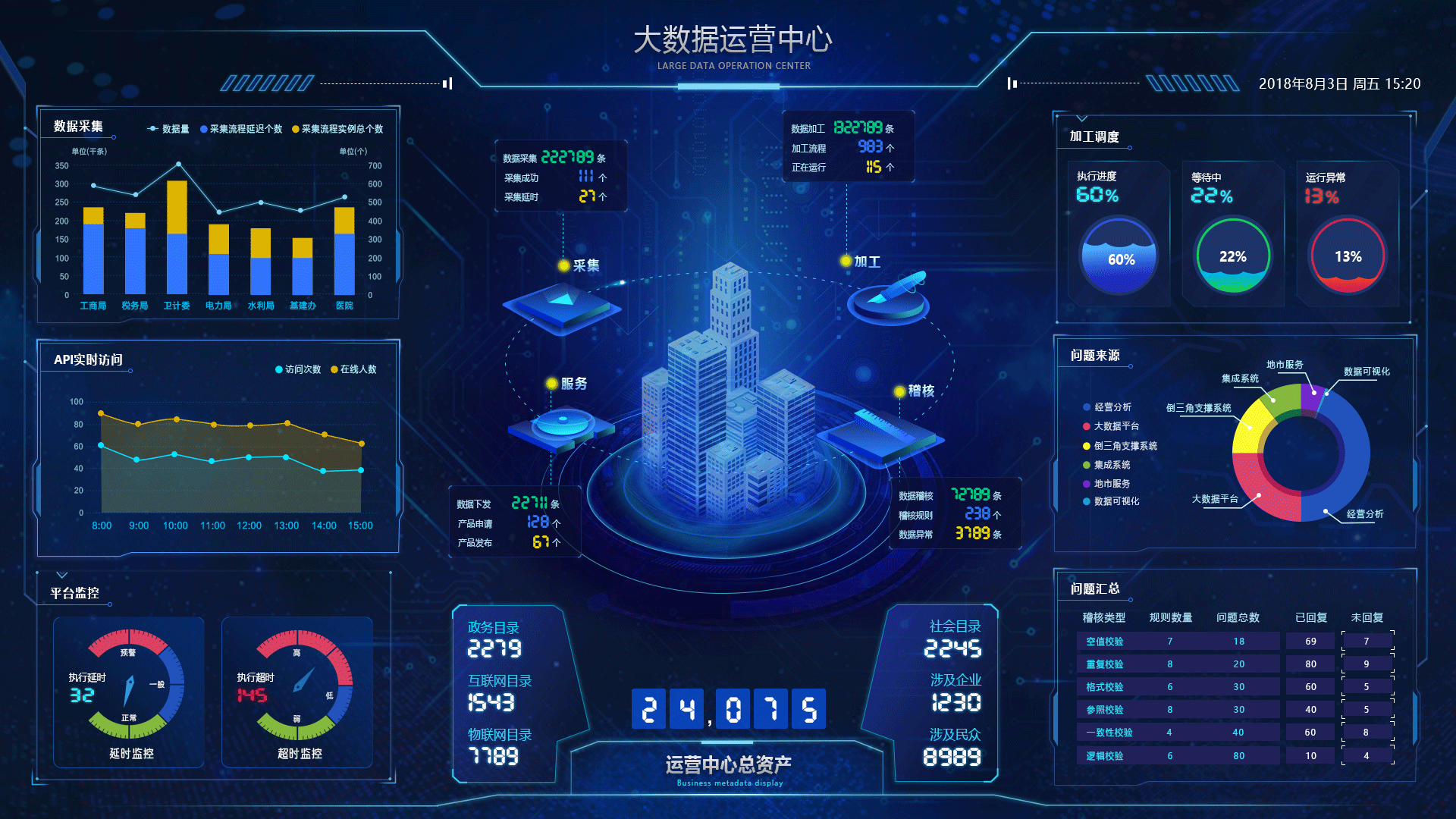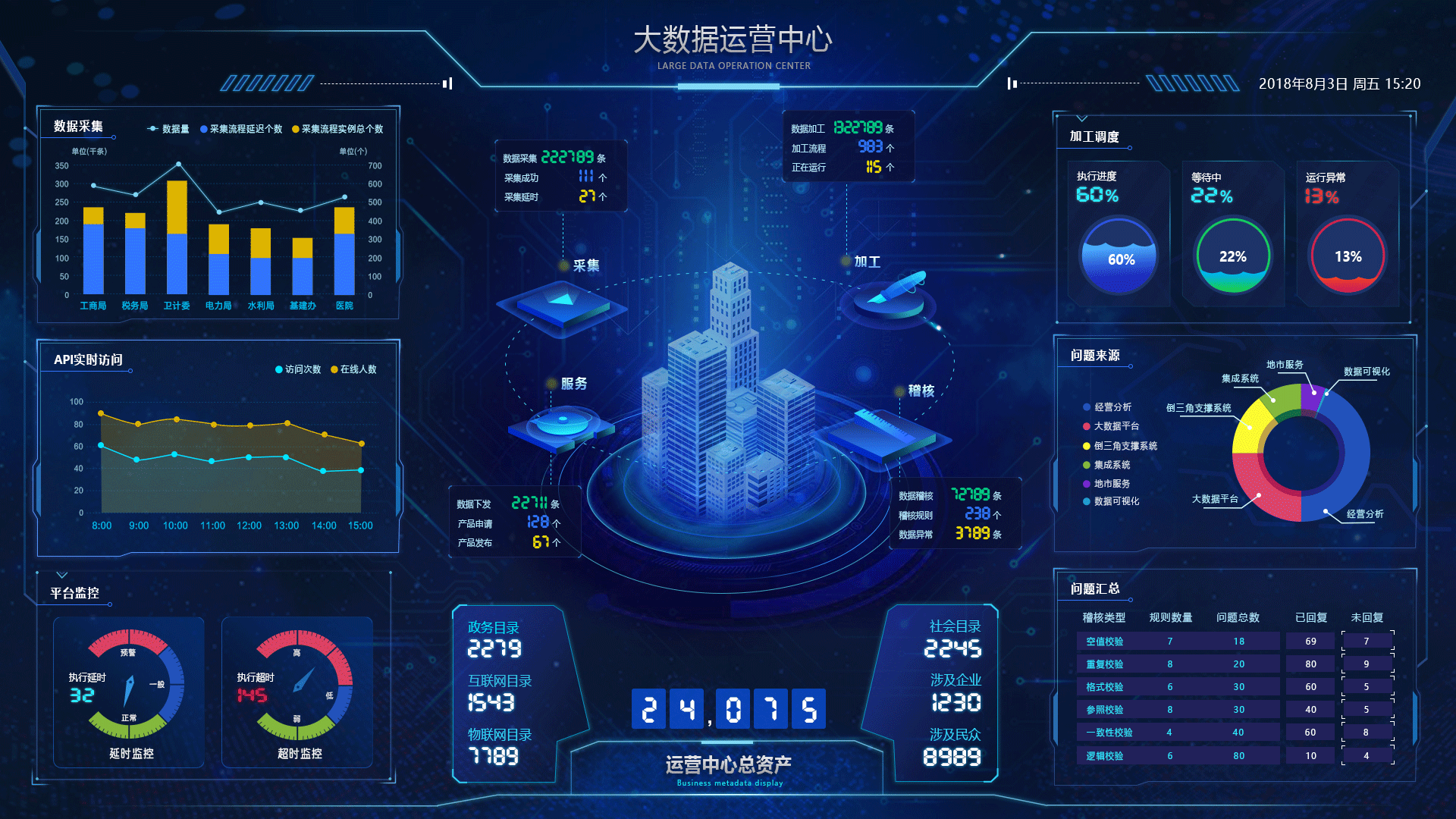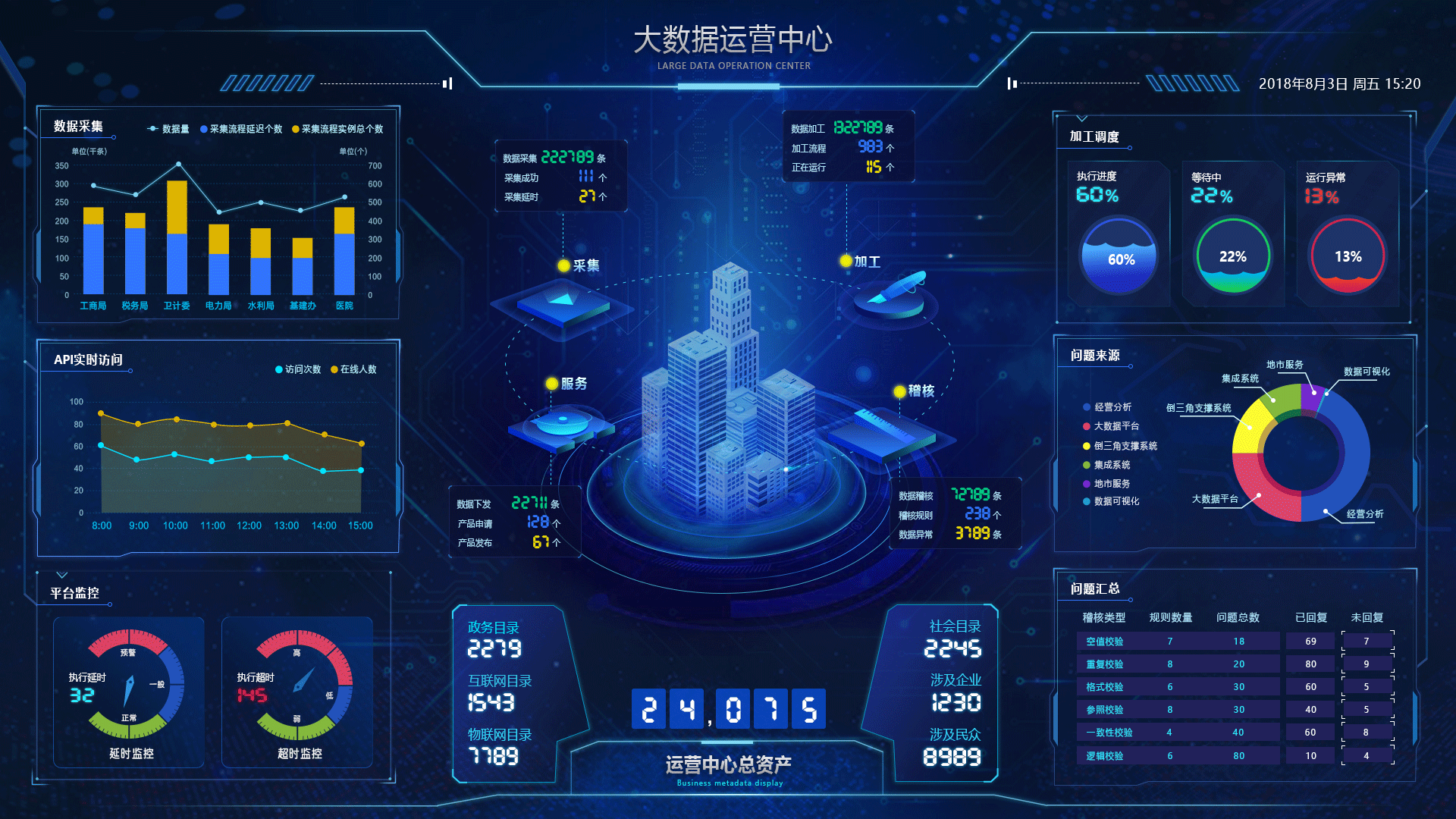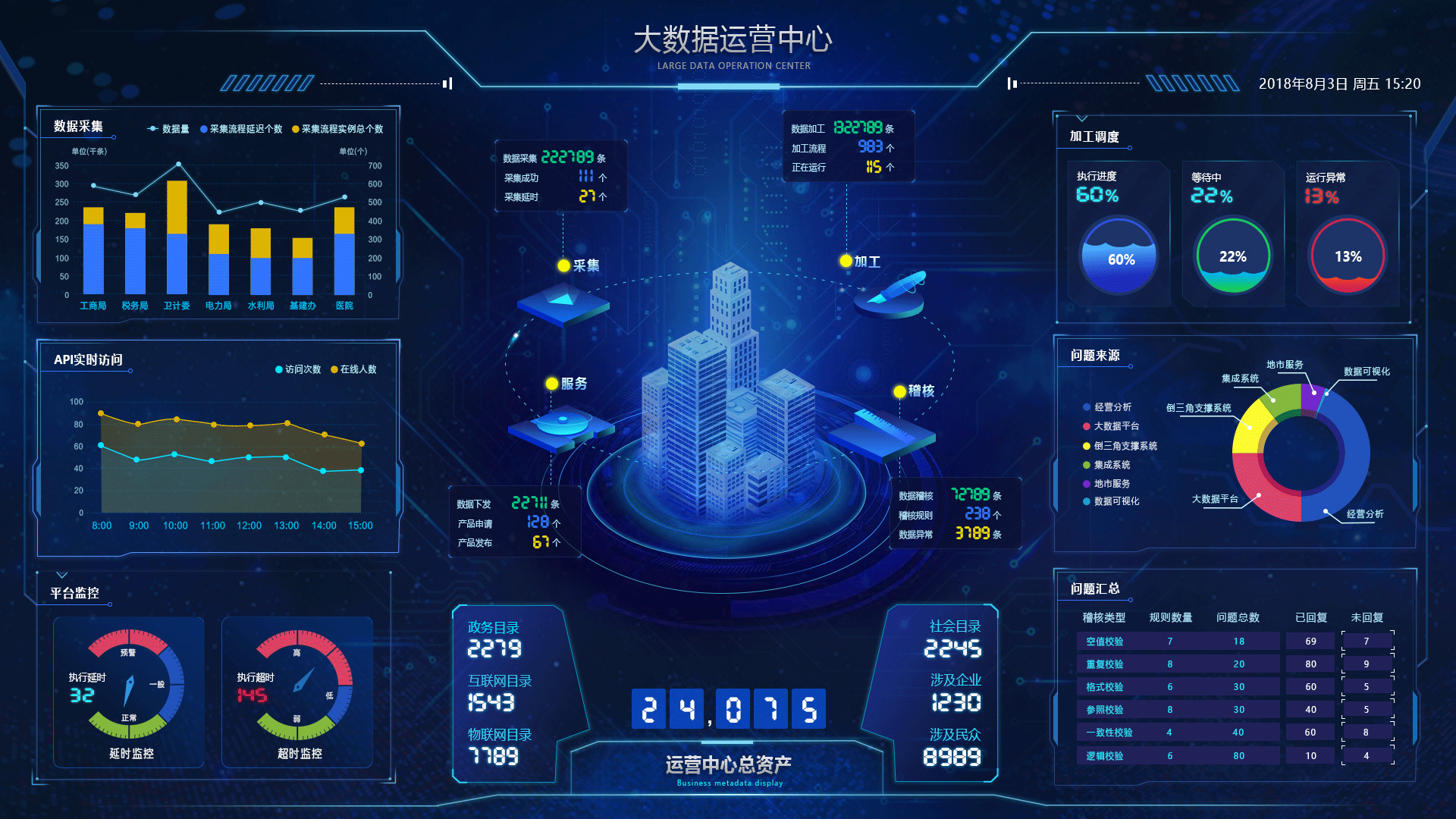
本文目录导航:
大数据剖析系统平台打算有哪些?
目前罕用的大数据处置打算包含以下几类一、Hadoop。
Hadoop 是一个能够对少量数据启动散布式处置的软件框架。
然而 Hadoop 是以一种牢靠、高效、可伸缩的方式启动处置的。
此外,Hadoop 依赖于社区主机,因此它的老本比拟低,任何人都可以经常使用。
二、HPCC。
HPCC,High Performance Computing and Communications(高性能计算与通讯)的缩写。
HPCC关键目的要到达:开发可裁减的计算系统及相关软件,以允许太位级网络传输性能,开发千兆 比特网络技术,裁减钻研和教育机构及网络衔接才干。
三、Storm。
Storm是自在的开源软件,一个散布式的、容错的实时计算系统。
Storm可以十分牢靠的处置宏大的数据流,用于处置Hadoop的批量数据。
Storm允许许多种编程言语,经常使用起来十分幽默。
Storm由Twitter开源而来四、Apache Drill。
为了协助企业用户寻觅更为有效、放慢Hadoop数据查问的方法,Apache软件基金会近日发起了一项名为“Drill”的开源名目。
该名目协助谷歌成功海量数据集的剖析处置,包含剖析抓取Web文档、跟踪装置在Android Market上的运行程序数据、剖析渣滓邮件、剖析谷歌散布式构建系统上的测试结果等等。
如何搭建大数据剖析平台?
自己为大数据技术员,可以分享一些心得体验给题主:其实题主须要搞分明以下几个疑问,搞分明了,其实疑问的答案也就有了:1、是从团体学习生长的角度想搭建平台自学?还是如今的公司须要大数据技术启动剖析?——假设是从团体学习生长的角度,倡导间接依照Hadoop或许Spark的官方教程装置即可,倡导看官方(英文),在大数据技术畛域,英语的把握是十分关键的,由于触及到组件选型、日后的装置、部署、运维,一切的义务运转信息、报错信息都是英文的,包含遇到疑问的解答,所以还是十分关键的。
假设是公司须要启动大数据剖析,那么还要钻研以下几个疑问:为什么须要搭建大数据剖析平台?要处置什么业务疑问?须要什么样的剖析?数据量有多少?能否有实时剖析的需求?能否有BI报表的需求?——这里举一个典型的场景:公司之前驳回Oracle或MySQL搭建的业务数据库,而且有繁难的数据剖析,或许或许洽购了BI系统,就是间接用业务系统数据库启动允许的,如今随着数据量越来越大,那么就须要驳回大数据技术启动扩容。
搞分明需求之后,依照以下的步骤启动:1、全体打算设计;全体打算设计时须要思考的起因:数据量有多少:几百GB?几十TB?数据存储在哪里:存储在MySQL中?Oracle中?或其余数据库中?数据如何从如今的存储系统进入到大数据平台中?如何将结果数据写出到其余存储系统中?剖析主题是什么:只要几个繁难目的?还是说有很多统计目的,须要专门的人员去梳理,分组,并启动产品设计;能否须要搭建全体数仓?能否须要BI报表:业务人员有无操作BI的才干,或团队组成比拟繁难,不须要前后端人员投入,经常使用BI比拟繁难;能否须要实时计算?2、组件选型;架构设计成功后就须要组件选型了,这时刻最好是比拟资深的架构师介入设计,选型包含:离线计算引擎:Hadoop、Spark、Tez……实时计算引擎:Storm、Flink、Samza、Spark Streaming……BI软件:Tableau、QlikView、帆软……3、装置部署;选型成功后,就可以启动装置部署了,这局部其实是最繁难的,间接依照每个组件的部署要求装置即可。
4、另一种选用:驳回商用软件假设是企业须要搭建大数据平台,那么还有一种选用是间接驳回商用的数据平台。
市面上有很多成熟的商用大数据平台,Cloudera、星环、华为、亚信等等,都有对应的产品线,业内数据大咖袋鼠云就有一款十分低劣的大数据平台产品:数栈。
关键有以下几个特点:1.一站式。
一站式数据开发产品体系,满足企业树立数据中台环节中的多样复杂需求。
2.兼容性强。
允许对接多种计算引擎,使更多企业“半路上车”。
3.开箱即用。
基于Web的图形化操作界面,开箱即用,极速上手。
4.性价比高。
满足中小企业数据中台树立需求,降落企业投入老本。
设计一个大数据实时剖析平台要怎样做呢?
Petabase-V作为Vertica基于亿信剖析产品的定制版,提供面向大数据的实时剖析服务,驳回无共享大规模并行架构(MPP),可线性裁减集群的计算才干和数据处置容量,基于列式数据库技术,使 Petabase-V 领有高性能、高裁减性、高紧缩率、高强健性等特点,可完美处置报表计算慢和明细数据查问等性能疑问。
大数据实时剖析平台(以下简称PB-S),旨在提供数据端到端实时处置才干(毫秒级/秒级/分钟级提前),可以对接少数据源启动实时数据抽取,可认为少数据运行场景提供实时数据生产。
作为现代数仓的一局部,PB-S可以允许实时化、虚构化、平民化、协作化等才干,让实时数据运行开发门槛更低、迭代更快、品质更好、运转更稳、运维更简、才干更强。
全体设计思维咱们针对用户需求的四个层面启动了一致化形象:一致数据采集平台一致流式处置平台一致计算服务平台一致数据可视化平台同时,也对存储层坚持了开明的准则,象征着用户可以选用不同的存储层以满足详细名目的须要,而又不破坏全体架构设计,用户甚至可以在Pipeline中同时选用多个异构存储提供允许。
上方区分对四个形象层启动解读。
1)一致数据采集平台一致数据采集平台,既可以允许不同数据源的全量抽取,也可以允许增强抽取。
其中关于业务数据库的增量抽取会选用读取数据库日志,以缩小对业务库的读取压力。
平台还可以对抽取的数据启动一致处置,而后以一致格局颁布到数据总线上。
这里咱们选用一种自定义的规范化一致信息格局UMS(Unified Message Schema)做为 一致数据采集平台和一致流式处置平台之间的数据层面协定。
UMS自带Namespace信息和Schema信息,这是一种自定位自解释信息协定格局,这样做的好处是:整个架构无需依赖外部元数据治理平台;信息和物理媒介解耦(这里物理媒介指如Kafka的Topic, Spark Streaming的Stream等),因此可以经过物理媒介允许多信息流并行,和信息流的自在漂移。
平台也允许多租户体系,和性能化繁难处置荡涤才干。
2)一致流式处置平台一致流式处置平台,会生产来自数据总线上的信息,可以允许UMS协定信息,也可以允许个别JSON格局信息。
同时,平台还允许以下才干:允许可视化/性能化/SQL化方式降落流式逻辑开发/部署/治理门槛允许性能化方式幂等落入多个异构目的库以确保数据的最终分歧性允许多租户体系,做到名目级的计算资源/表资源/用户资源等隔离3)一致计算服务平台一致计算服务平台,是一种数据虚构化/数据联邦的成功。
平台对内允许多异构数据源的下推计算和拉取混算,也允许对外的一致服务接口(JDBC/REST)和一致查问言语(SQL)。
由于平台可以一致收口服务,因此可以基于平台打造一致元数据治理/数据品质治理/数据安保审计/数据安保战略等模块。
平台也允许多租户体系。
4)一致数据可视化平台一致数据可视化平台,加上多租户和完善的用户体系/权限体系,可以允许跨部门数据从业人员的分工协作才干,让用户在可视化环境下,经过严密协作的方式,更能施展各自所长来成功数据平台最后十公里的运行。
以上是基于全体模块架构之上,启动了一致形象设计,并开明存储选项以提高灵敏性和需求适配性。
这样的RTDP平台设计,表现了现代数仓的实时化/虚构化/平民化/协作化等才干,并且笼罩了端到端的OLPP数据流转链路。
详细疑问和处置思绪上方咱们会基于PB-S的全体架构设计,区分从不同维度讨论这个设计须要面对的疑问考量和处置思绪。
性能考量关键讨论这样一个疑问:实时Pipeline能否处置一切ETL复杂逻辑?咱们知道,关于Storm/Flink这样的流式计算引擎,是按每条处置的;关于Spark Streaming流式计算引擎,按每个mini-batch处置;而关于离线跑批义务来说,是按每天数据启动处置的。
因此处置范围是数据的一个维度(范围维度)。
另外,流式处置面向的是增量数据,假设数据源来自相关型数据库,那么增量数据往往指的是增质变卦数据(增删改,revision);相对的批量处置面向的则是快照数据(snapshot)。
因此展现方式是数据的另一个维度(变卦维度)。
单条数据的变卦维度,是可以投射收敛成单条快照的,因此变卦维度可以收敛成范围维度。
所以流式处置和批量处置的实质区别在于,面对的数据范围维度的不同,流式处置单位为“有限范围”,批量处置单位为“全表范围”。
“全表范围”数据是可以允许各种SQL算子的,而“有限范围”数据只能允许局部SQL算子。
复杂的ETL并不是繁多算子,经常会是由多个算子组合而成,由上可以看出单纯的流式处置并不能很好的允许一切ETL复杂逻辑。
那么如何在实时Pipeline中允许更多复杂的ETL算子,并且坚持时效性?这就须要“有限范围”和“全表范围”处置的相互转换才干。
想象一下:流式处置平台可以允许流上适宜的处置,而后实时落不同的异构库,计算服务平台可以定时批量混算多源异构库(期间设定可以是每隔几分钟或更短),并将每批计算结果发送到数据总线上继续流转,这样流式处置平台和计算服务平台就构成了计算闭环,各自做长于的算子处置,数据在不同频率触发流转环节中启动各种算子转换,这样的架构形式切实上即可允许一切ETL复杂逻辑。
2)品质考量上方的引见也引出了两个干流实时数据处置架构:Lambda架构和Kappa架构,详细两个架构的引见网上有很多资料,这里不再赘述。
Lambda架构和Kappa架构各有其优劣势,但都允许数据的最终分歧性,从某种水平上确保了数据品质,如何在Lambda架构和Kappa架构中扬长避短,构成某种融合架构,这个话题会在其余文章中详细讨论。
当然数据品质也是个十分大的话题,只允许重跑和回灌并不能齐全处置一切数据品质疑问,只是从技术架构层面给出了补数据的工程打算。
关于大数据数据品质疑问,咱们也会起一个新的话题讨论。
3)稳固考量这个话题触及但不限于以下几点,这里繁难给出应答的思绪:高可用HA整个实时Pipeline链路都应该选取高可用组件,确保切实上全体高可用;在数据关键链路上允许数据备份和重演机制;在业务关键链路上允许双跑融合机制SLA保证在确保集群和实时Pipeline高可用的前提下,允许灵活扩容和数据处置流程智能漂移弹性反软弱? 基于规定和算法的资源弹性伸缩? 允许事情触发起作引擎的失效处置监控预警集群设备层面,物理管道层面,数据逻辑层面的多方面监控预警才干智能运维能够捕捉并存档缺失数据和处置意外,并具有活期智能重试机制修复疑问数据抢先元数据变卦抗性?抢先业务库要求兼容性元数据变卦? 实时Pipeline处置显式字段4)老本考量这个话题触及但不限于以下几点,这里繁难给出应答的思绪:人力老本经过允许数据运行平民化降落人才人力老本资源老本经过允许灵活资源应用降落静态资源占用形成的资源糜费运维老本经过允许智能运维/高可用/弹性反软弱等机制降落运维老本试错老本经过允许矫捷开发/极速迭代降落试错老本5)矫捷考量矫捷大数据是一整套切实体系和方法学,在前文已有所形容,从数据经常使用角度来看,矫捷考量象征着:性能化,SQL化,平民化。
6)治理考量数据治理也是一个十分大的话题,这里咱们会重点关注两个方面:元数据治理和数据安保治理。
假设在现代数仓少数据存储选型的环境下一致治理元数据和数据安保,是一个十分有应战的话题,咱们会在实时Pipeline上各个环节平台区分思考这两个方面疑问并给出内置允许,同时也可以允许对接外部一致的元数据治理平台和一致数据安保战略。
以上是咱们讨论的大数据实时剖析平台PB-S的设计打算。
