
AIxiv专栏是机器之心发布学术和技术内容的专栏。几年来,机器之心AIxiv专栏已收到2000余篇报道,覆盖全球各大高校和企业的顶级实验室,有效促进了学术交流和传播。如果您有优秀的作品想要分享,请随时投稿或联系我们进行举报。投稿邮箱:liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
D-FINE的作者均来自中国科学技术大学。第一作者为中国科学技术大学博士生彭岩松()。他的研究重点是实时目标检测和神经形态视觉。在AAAI、ICCV、CVPR等国际顶级会议上以第一作者发表多篇论文。本文由吴峰教授、孙晓燕教授和张悦副研究员共同指导。其他作者包括中国科学技术大学博士生李河北和硕士生吴培熙。
介绍
在当前严重内卷化的实时物体检测(Real-time ObjectDetection)领域,性能和效率始终是难以平衡的核心问题。现有的SOTA方法绝大多数仅依赖于更高级的模块替换或训练策略,导致性能逐渐饱和。
为了打破这一瓶颈,中国科学技术大学的研究团队提出了D-FINE,重新定义了边界框回归任务。与传统的固定坐标预测不同,D-FINE创新了两种方法:细粒度分布优化(FDR)和全局最优定位自蒸馏(GO-LSD)。通过将回归任务转变为细粒度的分布式优化任务,D-FINE不仅显着简化了优化难度,而且可以更准确地对每个边界的不确定性进行建模。此外,D-FINE将定位知识集成到模型输出中,并通过高效的自蒸馏策略在每一层共享这些知识,从而在不增加额外训练成本的情况下实现进一步显着的性能提升。

凭借这些创新,D-FINE 在 COCO 数据集上在 78 FPS 下实现了 59.3% 的平均精度(AP),远远超过 YOLOv10、YOLO11、RT-DETR v1/v2/v3 和 LW-DETR 等竞争对手。成为实时目标检测领域新的领导者。目前,D-FINE的所有代码、权重和工具都是开源的,包括详细的预训练教程和自定义数据集处理指南。

视频链接:
研究团队使用 D-FINE 和 YOLO11 对 YouTube 上的复杂街景视频进行目标检测。尽管存在逆光、模糊、密集遮挡等不利因素,D-FINE-X仍然成功检测到几乎所有目标,包括背包、自行车、红绿灯等微小且难以察觉的目标,置信度准确,模糊边缘定位准确。度明显高于YOLO11x。
细粒度分布优化 (FDR)
FDR(Fine-grained Distribution Refinement)将检测框生成过程分解为:
1.初始框预测:与传统的DETR方法类似,D-FINE解码器将对象查询转换为第一层中的几个初始边界框。这些边界框仅用于初始化,不需要特别精确。
2.细粒度分布优化:与传统方法不同,D-FINE的解码层并不直接预测新的边界框,而是根据初始边界框生成四组概率分布,并通过逐层优化进行调整。这些概率分布本质上是检测帧的“细粒度中间表示”。 D-FINE 可以微调这些表示,在不同程度上独立调整每个边缘。
具体流程如图所示:
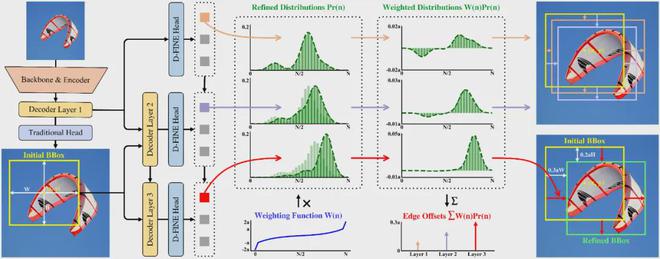
将边界框回归任务重铸为FDR具有以下优点:
1.过程简化:模型在传统L1损失和IoU损失的优化基础上,通过标签与预测结果之间的“残差”进一步约束这些中间状态的概率分布。这使得每个解码层能够更有效地关注当前的定位误差。随着层数的增加,优化目标变得更简单,从而简化了整体优化过程。
2.对复杂场景更加鲁棒:FDR中的概率水平本质上反映了模型对边界微调的置信度。这使得 D-FINE 能够独立地对不同网络深度的每条边的不确定性进行建模,从而使模型能够真正了解定位的效果。在遮挡、运动模糊、弱光等复杂的实际场景中,D-FINE表现出更强的鲁棒性,比四个固定值直接回归的方法鲁棒性更强。
3.灵活的优化机制:D-FINE通过加权求和将概率分布转化为最终的边界框偏移值。指数加权函数W(n)确保在初始框准确的情况下可以进行微调,并在必要时提供较大的修正。
4.可扩展性:FDR将回归任务定义为与分类任务一致的概率分布预测问题,这使得目标检测模型能够更好地受益于知识蒸馏、多任务学习、分布优化等更多领域的创新。从而更有效地适应和整合新技术,突破传统方法的局限性。
全局最优定位自蒸馏机制GO-LSD
GO-LSD(全局最优定位自蒸馏)可以轻松地将知识蒸馏应用于 FDR 框架检测器。
基于FDR框架的目标检测器不仅可以实现知识迁移,而且可以保持一致的优化目标。
新晋诺贝尔物理学奖得主杰弗里·辛顿在《在神经网络中蒸馏知识》一文中提到:概率就是“知识”。 FDR将概率分布转化为网络输出,并配备定位知识。因此,只需计算 KL 散度损失就可以将这种“知识”从深层转移到浅层。因为FDR架构中的每个解码层都有一个共同的目标,那就是减少初始边界框和真实边界框之间的残差。因此,最后一层生成的精确概率分布可以作为前面各层的最终目标,并指导前面的层进行蒸馏。
由于FDR架构中的每个解码层都有一个共同的目标:减少初始边界框和真实边界框之间的残差;因此,最后一层生成的准确概率分布可以作为前面各层的最终目标,并蒸馏引导前几层。
研究团队进一步提出基于FDR框架的全局最优定位自蒸馏GO-LSD,实现了网络层之间的定位知识蒸馏,进一步扩展了D-FINE的能力。具体流程如下:
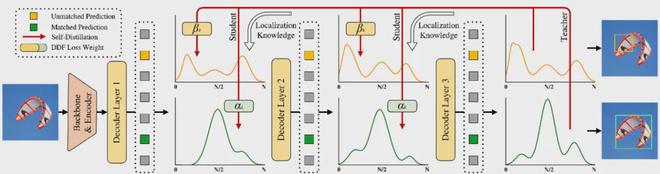
FDR和GO-LSD创造了一个双赢的“合成”:随着训练的进行,最后一层的预测会变得越来越准确,而它生成的软标签也可以更好地帮助前面的层改进预测。准确性。反过来,前几层将更快地定位准确位置。这相当于深度优化任务的简化,进一步提高了整体准确性。
实验结果
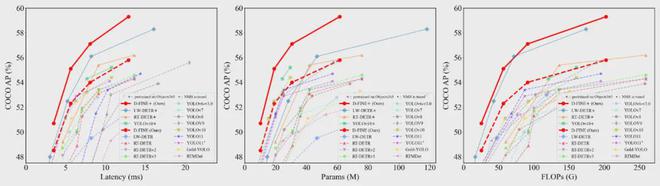
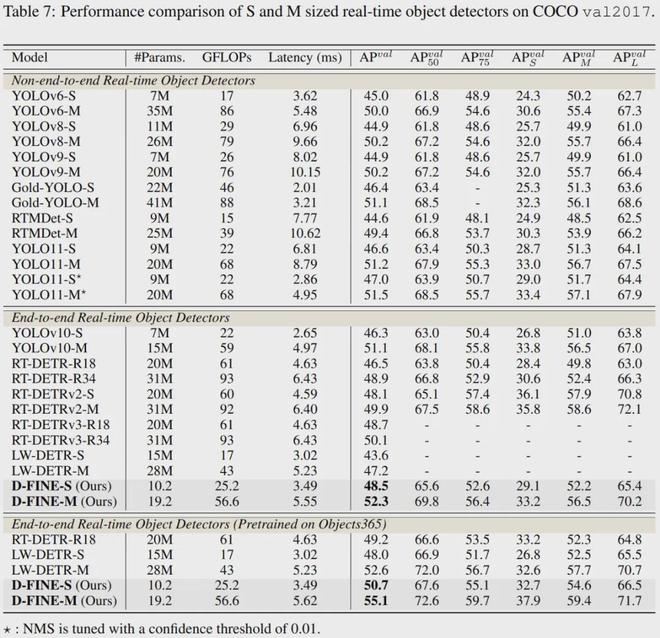
在COCO数据集上,D-FINE-L和D-FINE-X实现了54.0%和55.8%的AP,延迟分别为8.07 ms(124 FPS)和12.89 ms(78 FPS),远远超过所有其他实时Object检测器击败 YOLOv10 (53.2%, 54.4%)、YOLO11 (53.4%, 54.7%) 和 RT-DETRv2 (53.4%, 54.6%)。
在 Objects365 上进行简单的监督预训练后,D-FINE 的准确率达到了 59.3% AP。在paperwithcode网站上的MS COCO基准上的实时物体检测上,D-FINE的速度和性能远远超过其他方法,取得了Top1的成绩。
与基线RT-DETR相比,D-FINE-L和D-FINE-X显着减少了参数数量和计算复杂度。在推理速度显着提高的同时,性能分别实现了 1.8% 和 3.2% 的显着提升。
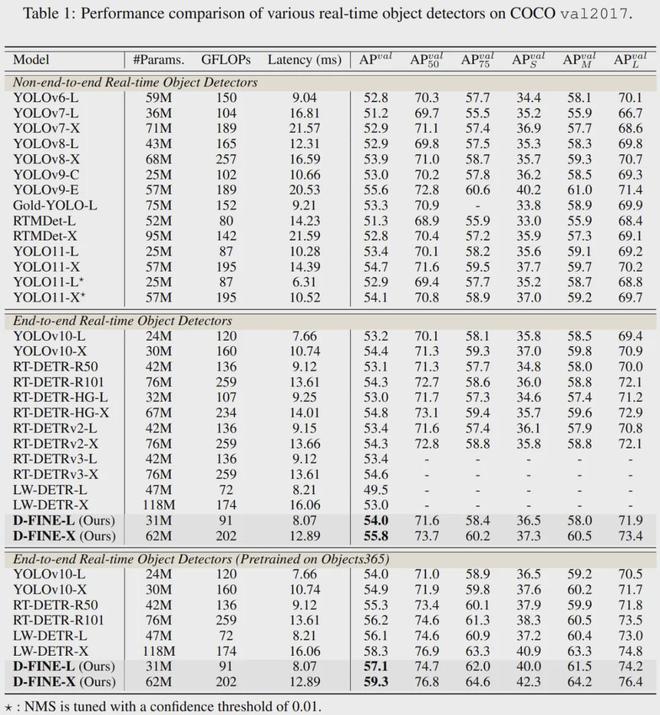
更轻量级的D-FINE-S和D-FINE-M在T4 GPU上实现了48.5%和52.3%的AP,延迟分别为3.49 ms(287 FPS)和5.62 ms(178 FPS),超过YOLOv10(46.3%, 51.1%)、YOLO11(46.6%、51.2%)和 RT-DETRv2(48.1%、49.9%)。预训练后,D-FINE-S和D-FINE-M分别达到了50.7%和55.1%的AP。
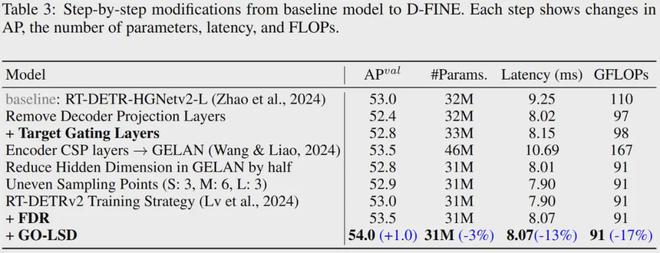
尽管FDR和GO-LSD可以显着提高性能,但它们并不能直接使网络更快或更轻。为了解决这个问题,研究团队对DETR架构进行了轻量化。这些调整不可避免地会导致一些性能下降,但 D-FINE 方法最终实现了速度、参数、计算复杂度和性能之间的平衡。下表显示了从基线到 D-FINE 的逐步修改过程。每一步都显示了模型在 AP、参数数量、延迟和 FLOP 方面的变化。
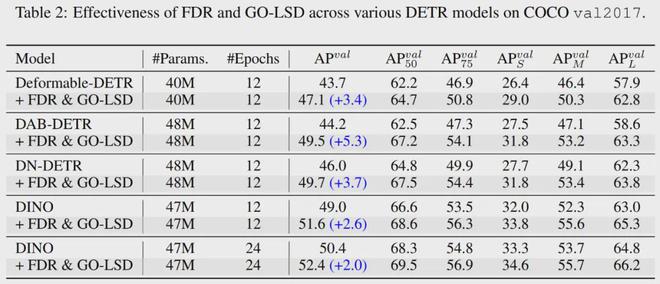
研究团队将FDR和GO-LSD应用于一系列非实时DETR检测模型。实验表明,在几乎不需要额外参数和计算能力的情况下,AP可以提高高达5.3%,证明了该方法的鲁棒性和泛化性。
根据消融实验,包含FDR的检测器与原始检测器在速度、参数量、计算复杂度上几乎没有差异,可以实现无缝替换。
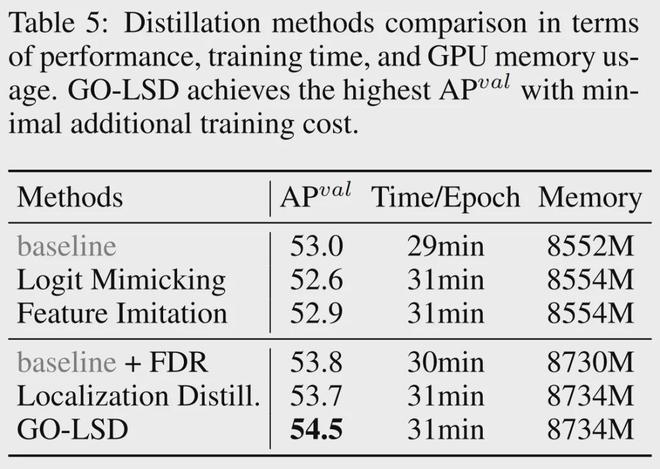
研究团队分析了训练成本,发现额外的时间和视频内存消耗主要来自生成用于监督分布的 FGL Loss 标签。通过D-FINE的进一步优化,这些额外的训练时间和显存占用分别控制在6%和2%以内,总体影响不大。
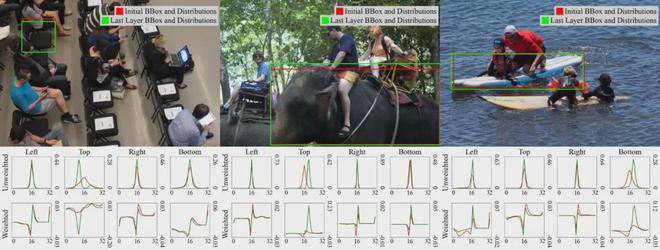
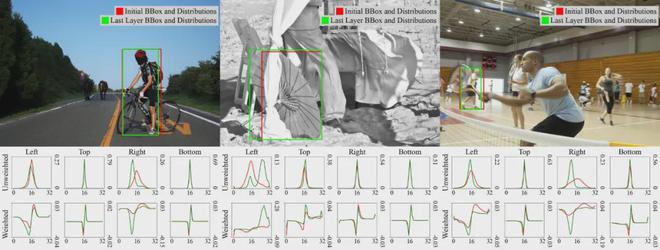
D-FINE 预测的可视化
以下是D-FINE在各种复杂检测场景下的预测结果。这些场景包括遮挡、低光、运动模糊、景深效果和密集场景。可见,面对这些具有挑战性的场景,D-FINE能够产生准确的定位结果。

下图展示了第一层和最后一层的预测结果,以及对应的四个边的分布以及加权分布。可以看到,随着分布的优化,预测框的定位会变得更加准确。
总结和局限性
D-FINE将边界框回归转化为逐层优化的概率分布预测,显着提高了模型在多任务场景下的兼容性。 D-FINE为目标检测模型的设计提供了新的思路。未来可以考虑进一步挖掘D-FINE在跨任务学习和模型轻量化方面的潜力。
D-FINE也有一些局限性:与大型模型相比,轻量版D-FINE的性能提升不太明显。这可能是因为浅层解码器的预测精度不高,无法有效地将定位信息传递到前几层。
未来的研究可以考虑提高轻量级模型的定位能力,同时避免增加推理延迟。一种想法是继续改进架构设计,尝试在训练期间引入额外的异构解码层,并在推理期间丢弃这些层以保持模型的轻量级。如果训练资源充足,也可以直接用大模型来蒸馏小模型,而不是依靠自蒸馏。
思考与展望
2024年,实时目标检测领域经历了多个版本迭代,YOLO系列推出了YOLOv9、YOLOv10、YOLO11。 DETR系列继RT-DETR之后又陆续推出了LW-DETR、RT-DETRv2和RT-DETRv3。
这两类模型的重要突破本质上得益于相互学习和融合。 RT-DETR引入YOLO的RepNCSP模块来替代冗余的多尺度自注意力层,并通过重新设计轻量级混合编码器实现实时DETR;而YOLOv10借鉴了DETR的匹配策略,训练了额外的一对一检测头,自动过滤密集的anchor预测,避免了NMS后处理,显着提高了速度。此外,YOLOv10和YOLO11还引入了self-attention机制,进一步增强大规模目标的检测性能。
尽管这些改进取得了显着的成果,但社区对未来的发展方向存在疑问:在两类模型融合的背景下,实时物体检测的下一步将如何发展?可以预见,在竞争激烈的目标检测领域,持续更换模块带来的效益将逐渐减少,并可能很快遇到瓶颈。
基于传统框架的训练策略的改进对于一些旧的网络(例如常用的Deformable DETR)可能是有效的,但应用于最新的SOTA网络时,往往很难取得明显的改进,甚至可能产生负面影响影响。特别是对于计算资源有限的小团队来说,如果没有大规模的超参数搜索,即使是复杂的训练策略也无法达到预期的结果。
D-FINE的出现给目标检测带来了新的思维方式。通过引入FDR和GO-LSD,D-FINE重新定义了物体检测中的边界框回归任务。这一创新有望突破当前瓶颈,为实时目标检测领域提供新的发展方向。
