【新智元简介】强化学习(RL)对于提高大型模型的复杂推理能力起着关键作用。然而,强化学习复杂的计算过程和现有系统的局限性也给训练和部署带来了挑战。近日,字节跳动豆宝模型团队与香港大学联合提出了灵活高效的RL/RLHF框架HybridFlow(开源项目名称:veRL)。该框架采用混合编程模型,结合了单控制器(Single-Controller)的灵活性和多控制器(Multi-Controller)的效率。它可以更好地实现和执行多种强化学习算法,显着提高训练吞吐量,降低开发和维护复杂度。实验结果表明,HybridFlow运行各种RL(HF)算法时,吞吐量较SOTA基线提高了1.5-20倍。
从ChatGPT[1]到o1等各种大型语言模型,强化学习(RL)算法在提高模型性能和适应性方面发挥着至关重要的作用。在大型模型的后训练阶段引入强化学习方法已成为提高模型质量和符合人类偏好的重要手段[2, 3]。
然而,随着模型规模的不断扩大,强化学习算法在大型模型训练中面临着灵活性和性能的双重挑战。
传统的RL/RLHF系统在灵活性和效率方面存在缺陷,难以适应新算法不断出现的需求,无法充分发挥大模型的潜力。
因此,开发一个高效、灵活的大模型强化学习训练框架就显得尤为重要。这不仅需要高效执行复杂的分布式计算过程,还需要能够灵活地适应不同的强化学习算法,以满足不断变化的研究需求。
字节跳动豆宝大模型团队与香港大学近日发布联合研究成果——灵活高效的大模型强化学习训练框架HybridFlow,兼容多种训练和推理框架,支持灵活的模型部署和多种强化学习算法实现。
HybridFlow采用混合编程模型,将单个控制器的灵活性与多个控制器的效率结合起来,实现控制流和计算流的解耦。基于Ray的分布式编程、动态计算图和异构调度能力,HybridFlow通过封装单个模型的分布式计算、统一模型之间的数据分割以及支持异步RL控制流,可以高效地实现和执行各种RL。算法、计算模块复用以及支持不同模型部署方式,大大提高了系统的灵活性和开发效率。
实验结果表明,在各种模型大小和强化学习算法下,HybridFlow 的训练吞吐量比其他框架提高了 1.5 至 20 倍。
目前,该论文已被EuroSys 2025接收,代码库也向公众开放。

论文题目:HybridFlow:灵活高效的 RLHF 框架
论文地址:
代码链接:
RL(Post-Training)复杂的计算过程给LLM训练带来新的挑战
在深度学习中,数据流(DataFlow)是一种重要的计算模型抽象,用于表示数据经过一系列复杂计算后实现特定功能。神经网络的计算是典型的DataFlow,可以用计算图(Computational Graph)来描述,其中节点代表计算操作,边代表数据依赖关系。
大模型RL的计算过程比传统神经网络更加复杂。在RLHF中,需要同时训练多个模型,例如Actor、Critic、Reference Policy和Reward Model,并且需要在它们之间传输大量数据。这些模型涉及不同类型的计算(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行化策略。
传统的分布式强化学习通常假设模型可以在单个GPU上进行训练,或者使用数据并行性[4,5]将控制流和计算流合并在同一进程中。这在处理小规模模型时效果很好,但面对大型模型时,训练需要复杂的多维并行,并涉及大量的分布式计算,传统方法很难处理。
HybridFlow 将控制流和计算流解耦,实现灵活性和效率。
大型模型RL本质上是一个二维DataFlow问题:高层控制流(描述RL算法的过程)+底层计算流(描述分布式神经网络计算)。
最近的开源RLHF框架,如DeepSpeed-Chat [6]、OpenRLHF [7]和NeMo-Aligner [8],都采用统一的多控制器(Multi-Controller)架构。每个计算节点独立管理计算和通信,降低控制和调度成本。然而,控制流和计算流是高度耦合的。当设计新的强化学习算法,将相同的计算流程和不同的控制流程结合起来时,需要重写计算流程代码并修改所有相关模型,这增加了开发难度。
与以往的框架不同,HybridFlow 采用混合编程模型。控制流由单个控制器(Single-Controller)管理并具有全局视图。实现新的控制流程既简单又快速。计算流程由多控制器(Multi-Controller)处理。这确保了计算的高效执行,并且可以在不同的控制流中重用。
虽然与纯多控制器架构相比,这可能会带来一定的控制调度开销,但HybridFlow通过优化数据传输,减少控制流和计算流之间的传输量,兼顾灵活性和效率。
系统设计一:混合编程模型(编程模型创新)
- 封装单一模型分布式计算
在HybridFlow中,各个模型(如Actor、Critic、参考策略、奖励模型等)的分布式计算被封装成独立的模块,称为模型类。
这些模型类继承自基本的并行Worker类(如3DParallelWorker、FSDPWorker等),并通过抽象的API接口封装了模型的正向和反向计算、优化器更新和自回归生成操作。这种封装方式提高了代码的复用性,方便模型的维护和扩展。
对于不同的RL控制流,用户可以直接复用封装好的模型类,同时定制一些算法所需的数值计算,以实现不同的算法。目前,HybridFlow可以使用Megatron-LM[13]和PyTorch FSDP[14]作为训练后端,同时使用vLLM[15]作为自回归生成后端,支持用户使用其他框架的训练和推理脚本进行自定义扩展。
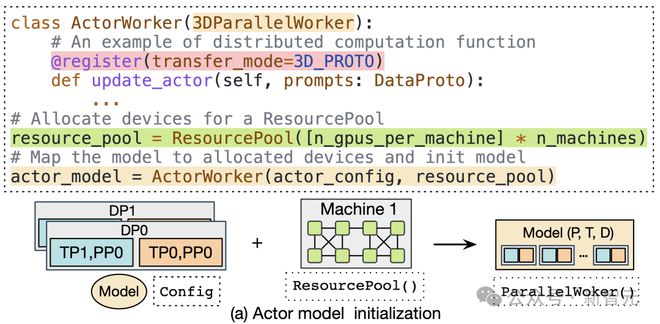
- 灵活的模型部署
HybridFlow提供了资源池(ResourcePool)概念,可以虚拟出一组GPU资源,将计算资源分配给各个模型。不同的资源池实例可以对应不同的设备集合,支持不同的模型部署在同组或不同组的GPU上。这种灵活的模型部署方式满足了不同算法、模型和硬件环境的资源和性能需求。
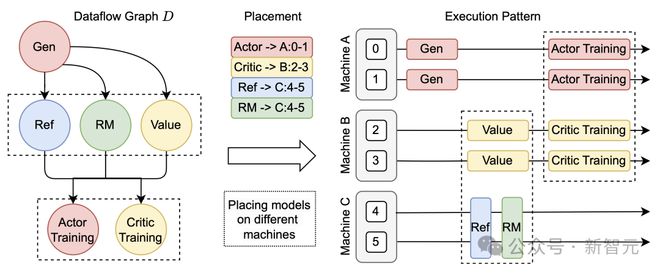
- 统一模型之间的数据分割
在大模型强化学习计算过程中,不同模型之间的数据传输涉及复杂的多对多广播和数据重新分片。
为了解决这个问题,HybridFlow设计了一套通用的数据传输协议(Transfer Protocol),包括收集和分发两部分。
通过在模型类的操作上注册相应的传输协议,如:@register(transfer_mode=3D_PROTO),HybridFlow可以在控制器层(Single-Controller)统一管理数据的收集和分发,实现数据的自动重新分区模型之间。切片支持不同并行度下的模型通信。
HybridFlow框架已经支持多种数据传输协议,覆盖大部分数据重切分场景。同时,用户可以灵活定制采集和分发功能,将其扩展到更复杂的数据传输场景。
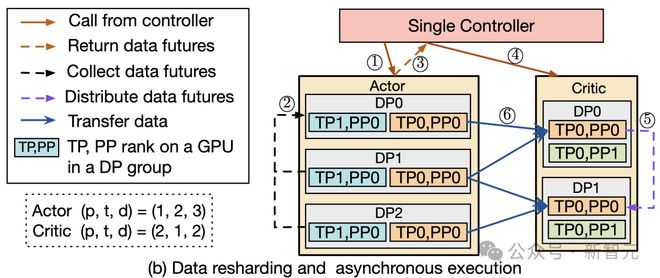
- 支持异步RL控制流
在HybridFlow中,控制流部分采用单控制器架构,可以灵活实现异步RL控制流。
当模型部署在不同的设备集上时,可以并行执行不同的模型计算,提高了系统的并行性和效率。对于部署在同一组设备上的模型,HybridFlow 通过调度机制实现顺序执行,避免资源争用和冲突。
- 用少量代码灵活实现各种RL控制流算法
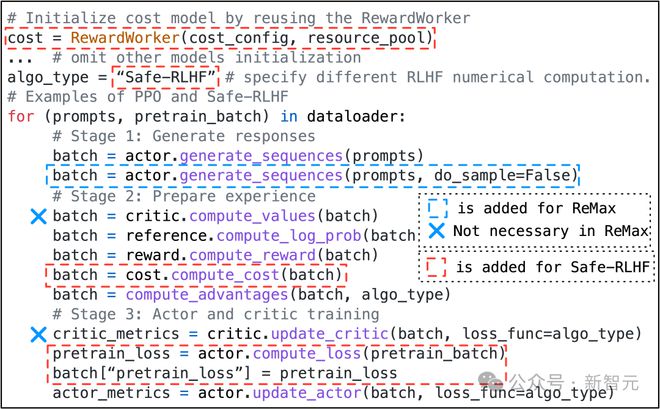
得益于混合编程模型的设计,HybridFlow可以轻松实现各种RLHF算法,例如PPO[9]、ReMax[10]、Safe-RLHF[11]、GRPO[12]等。用户只需调用模型类的API接口,根据算法逻辑编写控制流代码,无需关心底层的分布式计算和数据传输细节。
例如,实现PPO算法只需要少量代码,通过调用actor.generate_sequences、critic.compute_values等函数即可完成。同时,用户只需修改少量代码即可迁移到Safe-RLHF、ReMax和GRPO算法。
系统设计2:3D-HybridEngine(训练和推理混合技术)减少通信内存开销
在online RL算法中,Actor模型需要在训练和生成(Rollout)阶段之间频繁切换,并且两个阶段可能采用不同的并行策略。
具体来说,在训练阶段,需要存储梯度和优化器状态,并且可以相应增加模型并行度(Model Parallel Size,MP)。然而,在生成阶段,模型不需要存储梯度和优化器状态,并且不需要MP和数据并行大小(Data Parallel Size)。尺寸 (DP) 可能更小。因此,模型参数需要在两个阶段之间重新分片和分配,并且依赖传统的通信组构建方法会产生额外的通信和内存开销。
此外,为了在新的并行配置下使用模型参数,通常需要在所有GPU之间进行All-Gather操作,这带来了巨大的通信开销并增加了转换时间。
为了解决这个问题,HybridFlow设计了3D-HybridEngine来提高训练和生成过程的效率。
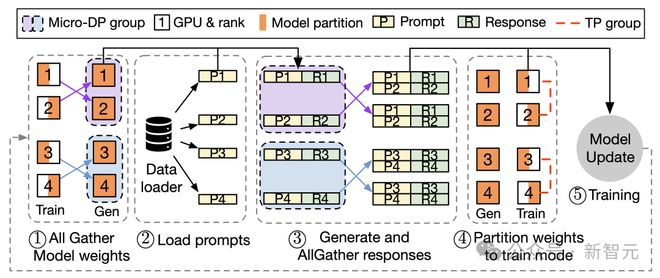
3D-HybridEngine 一次迭代过程
3D-HybridEngine通过优化并行分组方法实现零冗余模型参数重组,包括以下步骤:
- 定义不同的并行组
在训练和生成阶段,3D-HybridEngine使用不同的三维并行配置,包括:管道并行(PP)、张量并行(TP)和数据并行(DP)大小。训练阶段的并行配置是 - 。在生成阶段,我们添加了一个新的微数据并行组(Micro DP Group)来处理Actor模型参数和数据的重组。构建阶段的并行配置是 --- 。
- 重组模型参数的过程
通过巧妙地重新定义生成阶段的并行分组,每个GPU都可以在生成阶段重用训练阶段已有的模型参数切片,避免在GPU内存中保存额外的模型参数,消除内存冗余。
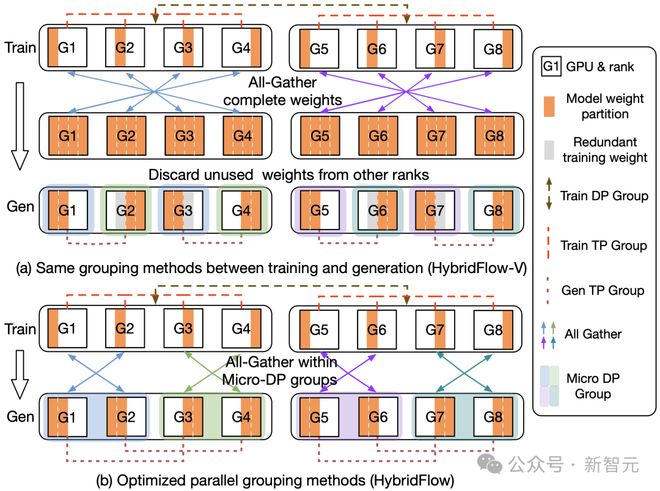
- 减少通信开销
在参数重组过程中,3D-HybridEngine仅在每个微数据并行组(Micro DP Group)内执行All-Gather操作,而不是跨所有GPU执行All-Gather操作。这大大减少了沟通量,减少了过渡时间,提高了整体培训效率。
实验结果:HybridFlow 在加速训练的同时提供灵活性
团队在 16 个 A100 GPU 集群上对 HybridFlow 和主流 RLHF 框架(DeepSpeed-Chat [6] v0.14.0、OpenRLHF [7] v0.2.5 和 NeMo-Aligner [8] v0.2.0)进行了对比实验。实验涵盖不同模型大小(7B、13B、34B、70B)的 LLM 和不同的 RLHF 算法(PPO [9]、ReMax [10]、Safe-RLHF [11])。
在所有实验中,Actor、Critic、参考策略和奖励模型都使用相同的尺度模型。更多实验配置和测试细节请参阅完整论文。
- 更高的端到端训练吞吐量
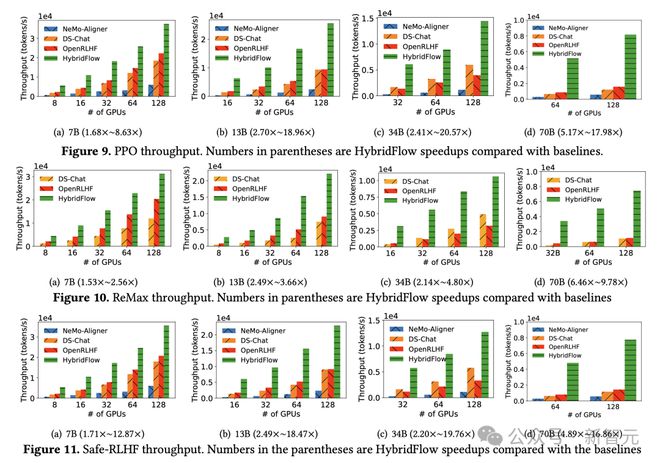
结果表明,HybridFlow 显着优于其他框架,并在各种模型大小和 RLHF 算法下实现了更高的训练吞吐量。
无论是 PPO、ReMax 还是 Safe-RLHF 算法,HybridFlow 的平均训练吞吐量在所有模型大小下都显着领先于其他框架,提升幅度从 1.5 倍到 20 倍不等。
随着 GPU 集群规模的增加,HybridFlow 吞吐量也能很好地扩展。这得益于其灵活的模型部署、充分利用硬件资源以及高效的并行计算。同时,HybridFlow可以支持多种分布式并行框架(Megatron-LM[13]、FSDP[14]、vLLM[15]),以满足不同模型规模的计算需求。
- HybridEngine有效降低开销
通过分析Actor模型在训练和生成阶段的过渡时间,团队发现HybridFlow的3D-HybridEngine的零冗余模型参数重组技术有效减少了两个阶段之间模型参数的重新分片和通信开销。
与其他框架相比,转换时间减少了55.2%,在70B模型上转换时间减少了89.1%。

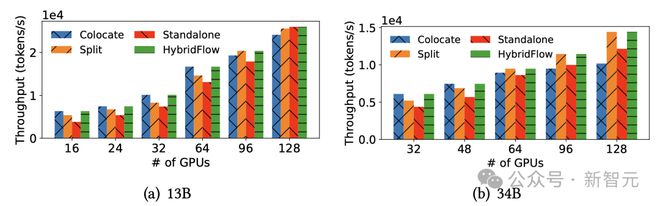
- 不同模型部署方法比较的三点见解
该团队比较了不同的模型部署策略,总结了模型部署和 GPU 分配的三个关键见解:
1. 为Actor模型分配更多的GPU可以缩短关键路径;
2. Colocate模式可以在规模相对较小的集群中最大化GPU利用率;
3. 在大规模集群的不同设备上部署Actor和Critic模型可以提高可扩展性。
值得一提的是,HybridFlow还适用于更广泛的RL训练场景。随着o1模型的诞生,业界对推理能力和RL的关注度也在不断增加,团队将围绕相关场景不断探索和实验。
该成果来自豆宝大模型基金会团队。论文第一作者为团队实习生Ming,目前就读于香港大学。
“我加入公司没多久,就有机会搭建这么重要的系统,机会难得。”他分享了。
Ming进一步补充道:“团队里有很多专家,不管有什么问题,我一定可以找到人倾诉。这次经历不仅让我学到了很多新技术,也充分体验到了完整的解决方案。”一个工业级开源项目从项目立项到发布的周期,大家都愿意帮忙,大家都是我的导师。”
目前,豆宝模型基金会团队正在持续吸引优秀人才加盟。硬核、开放、富有创新精神是团队氛围的关键词。团队希望与具有创新精神和责任感的技术人才一起,推动大模型训练效率的提升,取得更多的进步和成果。
参考:
[1] 汤姆·布朗等人。 “语言模型是小样本学习者。”神经信息处理系统的进展33(2020):1877-1901。
[2] 欧阳龙,等. 2022. 训练语言模型以遵循人类反馈的指令。神经信息处理系统的进展 35 (2022), 27730–27744。
[3]白云涛,等. 2022 年。通过人类反馈的强化学习来训练一个有用且无害的助手。 arXiv 预印本 arXiv:2204.05862 (2022)。
[4] 梁伟, 等. 2018.RLlib:分布式强化学习的抽象。在国际机器学习会议上。 PMLR,3053–3062。
[5] 梁伟, 等. 2021. RLlib Flow:分布式强化学习是一个数据流问题。神经信息处理系统的进展 34 (2021), 5506–5517。
[6] 姚哲伟,等. 2023. DeepSpeed-Chat:简单、快速且经济实惠的所有规模的类似 ChatGPT 模型的 RLHF 训练。 arXiv 预印本 arXiv:2308.01320 (2023)。
[7] 胡建,等。 OpenRLHF:一个易于使用、可扩展且高性能的 RLHF 框架。 arXiv 预印本 arXiv:2405.11143
[8] 英伟达公司。 2024. NeMo-Aligner:用于高效模型对齐的可扩展工具包。
[9] 约翰·舒尔曼、菲利普·沃尔斯基、普拉富拉·达里瓦尔、亚历克·雷德福和奥列格·克里莫夫。 2017。近端策略优化算法。 arXiv 预印本 arXiv:1707.06347 (2017)。
[10] 李子牛,等. 2023.ReMax:一种简单、有效、高效的对齐大型语言模型的强化学习方法。 arXiv 预印本 arXiv:2310.10505 (2023)。
[11] 约瑟夫·戴,等。 2024. Safe RLHF:根据人类反馈进行安全强化学习。在第十二届学习代表国际会议上。 TyFrPOKYXw
[12] 邵志宏,等。 2024. Deepseekmath:突破开放语言模型中数学推理的极限。 arXiv 预印本 arXiv:2402.03300 (2024)。
[13] 穆罕默德·舒伊比等人。 2019.Megatron-lm:使用模型并行性训练数十亿参数语言模型。 arXiv 预印本 arXiv:1909.08053 (2019)。
[14] 亚当·帕斯克等人。 2019. Pytorch:命令式高性能深度学习库。神经信息处理系统的进展 32 (2019)。
[15] 权佑硕,等。 2023. 为 pagedattention 提供服务的大型语言模型的高效内存管理。第 29 届操作系统原理研讨会论文集。 611–626。
