
机器之心发布
机器之心编辑部
虽然视频生成模型可以生成一些看似符合常识的视频,但事实证明它仍然无法理解物理定律!
自从Sora出现以来,业界一直存在关于视频生成模型是否理解物理定律的争论。图灵奖得主Yann LeCun明确表示,基于文本提示生成的真实视频并不意味着模型真正理解了物理世界。后来他甚至直言,像Sora那样通过生成像素来建模世界是注定要失败的。
Keras之父François Chollet认为,像Sora这样的视频生成模型确实嵌入了“物理模型”,但问题是:这个物理模型准确吗?它可以推广到新的情况,即那些不仅仅是训练数据插值的情况吗?这些问题对于确定生成图像的应用范围至关重要——无论它们是否仅限于媒体制作,或者是否可以用作现实世界的可靠模拟。最后,他指出,不能简单地拟合大量数据并期望得到一个可以泛化到现实世界中所有可能情况的模型。

此后,对于视频生成模型是否在学习和理解物理定律,业界尚未得出结论。直到最近,字节豆宝大模型团队发布的一项系统研究,才对两者的关系“画上了不平等的符号”。
通过大规模实验,团队发现,即使按照Scaling Law扩大模型参数和训练数据量,模型仍然无法抽象出一般的物理规则,甚至无法理解牛顿第一定律和抛物线运动。
“视频生成模型目前就像一个只能‘抄作业’的学生,可以背案例,但无法真正理解物理定律、‘举一反三’。因此,模型会变得‘糊涂’”当遇到它没有学过的场景时,“生成的结果与物理规则不一致,”研究作者说。
相关推文发布后
此外,CV大师谢赛宁和常年活跃的Gary Marcus等人也纷纷跟进。

视频链接:
索拉的世界里存在物理吗?
此前Sora发布时,OpenAI在其宣传页面上写道:我们的结果表明,改进视频生成模型的参数和数据量为构建物理世界的通用模拟器提供了可行的方法。

在给人们带来希望的同时,业内也存在不少质疑。很多人并不相信基于DiT架构的视频生成模型能够真正理解物理定律。其中,尤以LeCun为代表。这个人工智能巨头一直坚称基于概率的大型语言模型无法理解常识,包括真实的物理定律。
虽然大家都有不同的看法,但市场上针对这个问题的系统研究却很少。出于对这个课题的好奇,字节豆宝大模型相关团队于2024年初启动了这个研究项目,并最终在8个月后完成了系统实验。
原理与实验设计
在这项工作中,如何定量分析视频生成模型对物理定律的理解是一个重大挑战。
豆宝大模型团队采用专门开发的物理引擎,合成匀速直线运动、球体碰撞、抛物线运动等经典物理场景的运动视频,并用其训练基于主流DiT架构的视频生成模型。然后,通过检查模型后续生成的视频在运动、碰撞等方面是否符合力学定律,判断该模型是否真正理解了物理定律,是否具备“世界模型”的潜力。
针对视频生成模型在学习物理定律方面的泛化能力,团队探索了以下三个场景的表现:
在基于视频的观察中,每一帧代表一个时间点,根据物理定律的预测对应于从过去和当前的帧生成未来的帧。因此,团队在每个实验中训练了一个帧条件视频生成模型来模拟和预测物理现象的演变。
通过测量生成视频的每一帧(时间点)物体的位置变化,可以判断其运动状态,然后与真实模拟视频数据进行比较,以确定生成的内容是否符合经典物理的方程表达。
在实验设计方面,该团队专注于由基本运动学方程控制的确定性任务。这些任务可以实现明确定义的分布内 (ID) 和分布外 (OOD) 泛化,并实现对错误的直观定量评估。
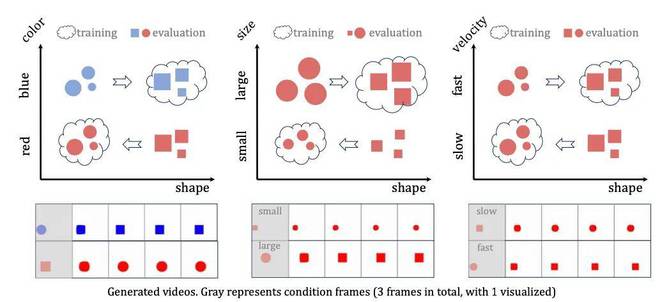
该团队选择了以下三个物理场景进行评估,每个运动都由其初始框架决定:
匀速直线运动:球以恒定速度水平运动,用于说明惯性定律。完美弹性碰撞:两个大小不同、速度不同的球水平向彼此运动并发生碰撞,体现能量和动量守恒定律。抛物线运动:具有初始水平速度的球由于重力而下落,符合牛顿第二定律。
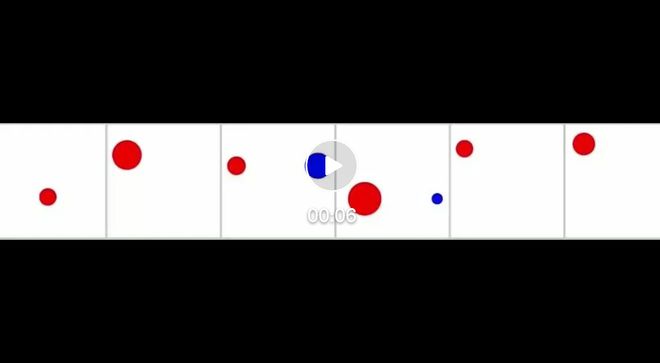
视频链接:
针对组合泛化场景,团队使用PHYRE模拟器来评估模型的组合泛化能力。 PHYRE 是一个二维模拟环境,包括球、罐子、杆子和墙壁等多个对象。它们可以是固定的,也可以是动态的,并且可以执行复杂的物理相互作用,例如碰撞、抛物线轨迹、旋转等,但环境中的底层物理定律是确定性的。
在视频数据构建方面,每个视频考虑八种对象,包括两个动态灰球、一组固定黑球、一个固定黑条、一个动态条、一组动态竖条和一个动态罐子和一个动态的站立棒。
每个任务包含一个红球和从这八种类型中随机选择的四个物体,总共形成

独特的模板。数据示例如下:
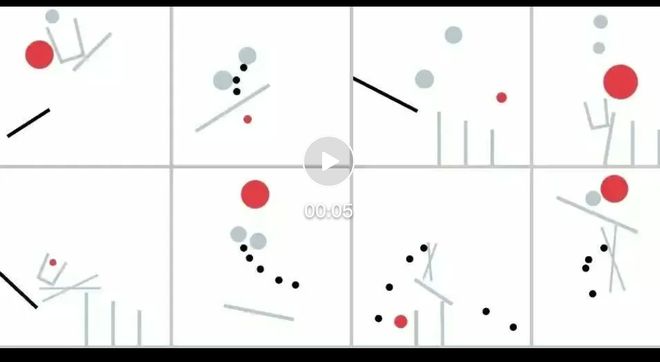
视频链接:
对于每个训练模板,团队保留了一小部分视频来创建模板内评估集,并保留 10 个未使用的模板用于模板外评估。集)来评估模型泛化到训练期间未见过的新组合的能力。
实验结果与分析
豆宝大模型团队的实验发现,即使按照“缩放定律”增加模型参数规模和数据量,模型仍然无法抽象出通用的物理规则并真正“理解”它们。
以最简单的匀速直线运动为例,模型学习到球在不同速度下保持匀速直线运动的训练数据后,给定初始几帧,要求模型生成球匀速运动的视频训练设定速度范围内的线性运动。 ,随着模型参数和训练数据量的增加,生成的视频逐渐变得更加符合物理规律。
然而,当要求模型生成看不见的速度范围(即训练数据范围之外)的运动视频时,模型突然不再遵循物理定律,生成的结果无论提高多少都不会显着改善添加模型参数或训练数据。这表明视频生成模型无法真正理解物理定律并将这些定律推广到全新的场景。
不过,研究中也有好消息:如果训练视频中的所有概念和物体都是模型熟悉的,那么就增加训练视频的复杂度,比如结合起来增加物体之间的物理交互。通过增加训练数据,模型将越来越符合物理定律。这一结果可以为视频生成模型继续提高性能提供启发。
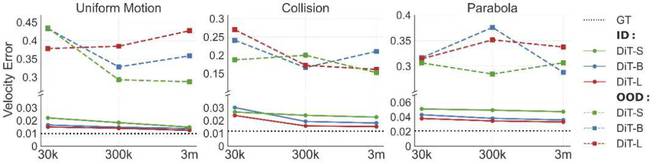
具体来说,在分布内泛化(ID)的测试中,团队观察到,随着模型大小的增加(从 DiT-S 到 DiT-L)或训练数据量的增加(从 30K 到 3M),模型速度所有三项物理任务中的错误都减少了。这表明模型大小和数据量的增加对于分布内泛化至关重要。
然而,分布外泛化 (OOD) 与分布内泛化 (ID) 结果形成鲜明对比:
对于组合泛化场景,从下表中我们可以看到,当模板数量从6个增加到60个时,所有指标(FVD、SSIM、PSNR、LPIPS)在模板外的测试集上都有显着提高。特别是,异常率(生成的违反物理定律的视频比例)从 67% 大幅下降至 10%。这说明当训练集覆盖更多的组合场景时,模型在未见过的组合中能够表现出更强的泛化能力。
然而,对于模板内测试集,该模型在 6 个模板的训练集上的 SSIM、PSNR 和 LPIPS 等指标上表现最佳,因为每个训练示例都会重复显示。
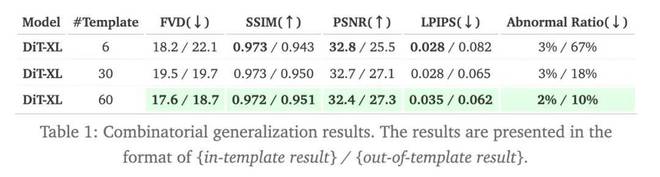
这些结果表明模型容量和组合空间的覆盖范围对于组合泛化至关重要。这意味着视频生成的缩放法则应侧重于增加组合的多样性,而不仅仅是扩大数据量。
视频链接:
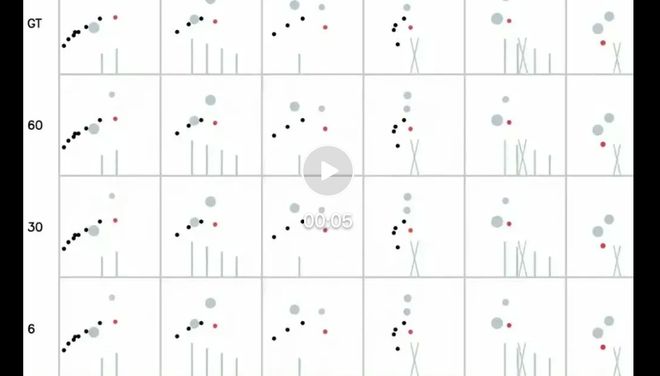
图例:在模板之外的测试集上生成的示例视频。第一行:真实视频。第二行:使用 60 个模板训练的模型生成的视频。第三行:使用 30 个模板训练的模型生成的视频。第四行:使用 6 个模板训练的模型生成的视频。
机制探索:模型如何依赖记忆和案例模仿
如前所述,视频生成模型对于分布外泛化表现不佳,但在组合场景中,数据和模型缩放可以带来一定的改进。这是来自案例学习还是对基本规律的抽象理解?团队着手开展相关实验。
使用匀速运动视频进行训练,速度范围为v∈[2.5, 4.0],并使用前3帧作为输入条件。我们使用两个数据集来训练并比较结果。 Set-1 仅包含从左向右移动的球,而 Set-2 包含从左向右移动的球和从右向左移动的球。
如下图所示,给定低速向前(从左到右)运动的帧条件,Set-1模型生成的视频仅具有正速度,并且偏向于高速范围。相比之下,Set-2 模型偶尔会生成负速度的视频,如图中的绿色圆圈所示。
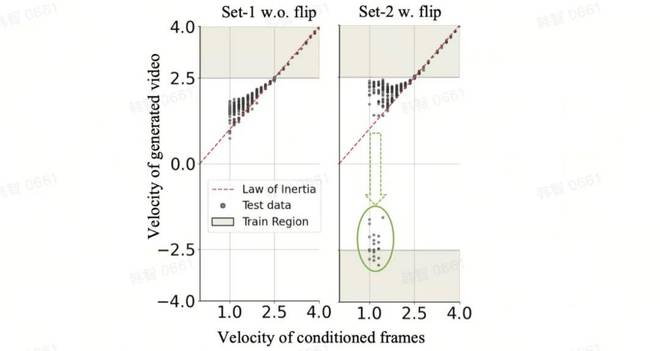
面对两者的差异,团队推测这可能是因为模型认为距离低速球较近的球是训练数据中运动方向相反的球,导致模型受到影响通过训练数据中的“误导性”示例。换句话说,该模型似乎更多地依赖于记忆和案例模仿,而不是抽象通用物理规则来实现分布外泛化(OOD)。
在上一篇文章中,我们探索并了解到模型更多地依赖于记忆和类似案例来模仿和生成视频。此外,还需要分析哪些属性对其模仿影响较大。
在对比颜色、形状、大小和速度这四个属性后,团队发现基于扩散技术的视频生成模型本质上更偏向于其他属性而不是形状,这也可以解释为什么当前的开放集视频生成模型通常会遇到困难保持形状。
如下图所示,第一行是真实视频,第二行是视频模型生成的内容。颜色保持得很好,但形状很难保持。
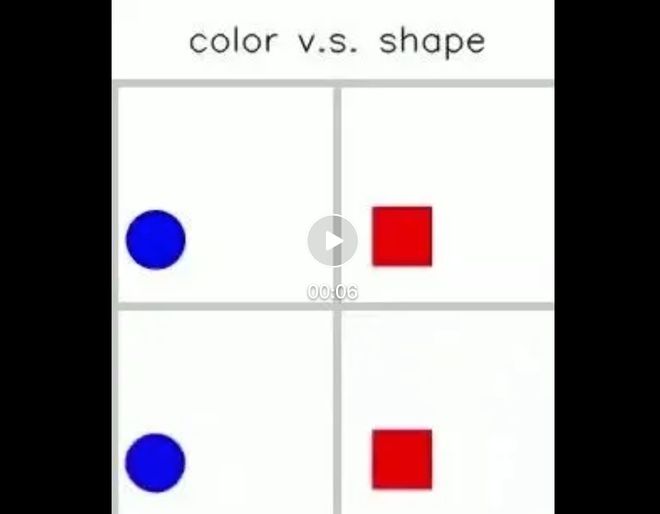
视频链接:
对比两者后,团队发现视频生成模型更习惯于通过“颜色”寻找相似的参考来生成物体运动状态,其次是大小,然后是速度,最后是形状。颜色/大小/速度对形状的影响如下:
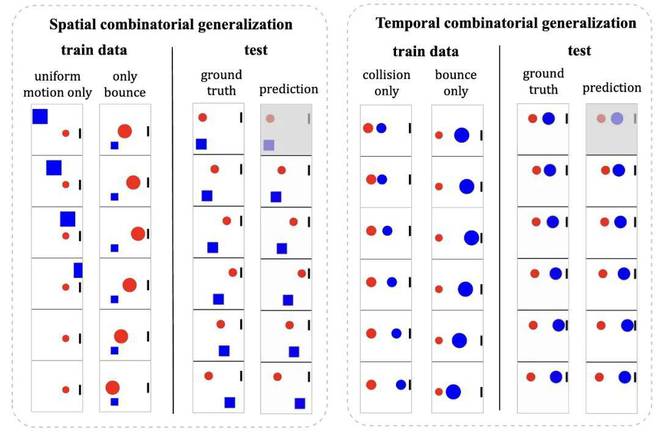
最后,对于为什么会出现复杂的组合泛化,团队提出视频模型具有三种基本的组合模式,分别是:属性组合、空间组合(不同运动状态的多个对象)、时间组合(不同时间点的多个对象) )。物体的不同状态)。
实验结果表明,对于速度与大小或颜色与大小等属性对,模型表现出一定程度的组合泛化能力。同时,如下图所示,模型可以通过重新组合训练数据的局部片段来重新组合时间/空间维度。
然而,值得注意的是,不可能在所有情况下通过组合泛化生成遵循物理定律的视频。该模型对案例匹配的依赖限制了其有效性。在不了解底层规则的情况下,模型会检索并组合片段,可能会产生不切实际的结果。
最后,该团队探讨了视频表示空间中的生成是否足以作为世界模型,并发现视觉模糊性可能会导致细粒度物理建模中出现重大错误。
例如下图,当物体大小差异仅在像素级别时,单纯通过视觉来判断球是否可以通过间隙就变得非常困难,这可能会导致看似合理但实际上错误的结果。

视频链接:
图例:第一行是真实视频,第二行是模型生成的视频。
这些发现表明,仅依靠视频表示不足以进行准确的物理建模。
团队介绍
这篇论文有两位核心作者,其中一位是豆宝大模特团队的95后研究员康丙一。他之前负责的研究项目Depth Anything也获得了业界的广泛关注,并被纳入苹果的CoreML库中。
丙一表示,世界模型的概念很早就被提出了。自AlphaGo诞生以来,业界就流传着“世界模式”一词。 Sora走红后,他决定从视频生成模型能否真正理解物理定律开始,一步步开始。揭示世界模型机制。
项目已经三四个星期没有任何进展了。直到一次实验,大家才注意到一个非常隐蔽且非常规的现象。在设计了对比实验后,他们证实“模型实际上并不是在总结规则,而是将它们与规则进行匹配”。最接近的样本”。
“做研究往往并不意味着你突然有了一个好主意,然后一试就行了。大多数时候你是在排查问题。但经过一段时间的试错后,你可能会突然发现某个方向。”有一个解决方案。”秉义说道。
虽然研究历时8个月,而且他每天都对视频中的虚拟球进行定量实验,但大家更多感受到的并不是无聊,而是“好玩”和“烧脑”。回忆起这段时期,他感叹道:“团队在基础研究方面给予了充足的探索空间。”
另一位00后学生也是核心参与者之一。据他介绍,这项研究是他经历过的最具挑战性、最耗时的项目。涉及物理引擎的搭建、评估体系、实验方法等。非常繁琐,有好几个项目都卡住了。不过,组长和导师都给予了耐心和鼓励,“没有人催促我尽快完成项目”。
