你知道我们每天在网上看到和听到的东西有多少是由人工智能产生的吗?

除了“仔细看!这个男人叫小帅”让人头皮发麻,
真正的问题是我们无法判断哪些内容是人工智能生成的。
养育了这些擅长胡言乱语的AI之后,人类面临的麻烦也会随之而来。
(LLM:为什么人类和AI之间连最基本的信任都没有?)
子曰:解铃必先系铃。近日,谷歌 DeepMind 团队发表的一项研究登上了 Nature 杂志的封面:

研究人员开发了一种名为 SynthID-Text 的水印方案,可应用于生产级 LLM 来跟踪 AI 生成的文本内容并使其不可见。

论文地址:
一般来说,文本水印与我们通常看到的图像水印不同。
图片可以有明显的防盗水印,或者只是修改一些像素,以免影响内容的观感,使人眼看不见。
但要让本文添加的水印不可见似乎并不容易。

为了不影响LLM生成的文本质量,SynthID-Text使用了一种新颖的采样算法(锦标赛采样)。
与现有方法相比,检测率更高,并且可以配置为平衡文本质量与水印可检测性。
如何证明文字质量不受影响?直接放到自己的Gemini和Gemini Advanced上就可以实际使用了。
研究人员评估了近 2000 万条实时交互响应,用户反馈正常。
SynthID-Text的实现只是修改了采样程序,并不影响LLM的训练。同时,推理过程中的延迟可以忽略不计。
此外,为了匹配LLM的实际使用场景,研究人员还集成了水印和推测采样,使其真正适用于生产系统。
指纹大模型
我们来看看DeepMind的水印有什么独特之处。
目前有三种方法可以识别人工智能生成的内容。
第一种方法是在生成LLM时留在最后,这在成本和隐私方面存在问题;
第二种方法是后检测,计算文本的统计特征或训练人工智能分类器。运行成本非常高,且仅限于自己的数据域;
第三种是添加水印,可以在文本生成之前(训练阶段,数据驱动的水印)、生成期间和生成之后(基于编辑的水印)添加。
数据驱动的水印需要使用特定的短语来触发,而基于编辑的水印一般是同义词替换或特殊Unicode字符的插入。这两种方法都会在文本中留下明显的伪影。
SynthID-Text生成水印
本文的方法是在生成过程中添加水印。
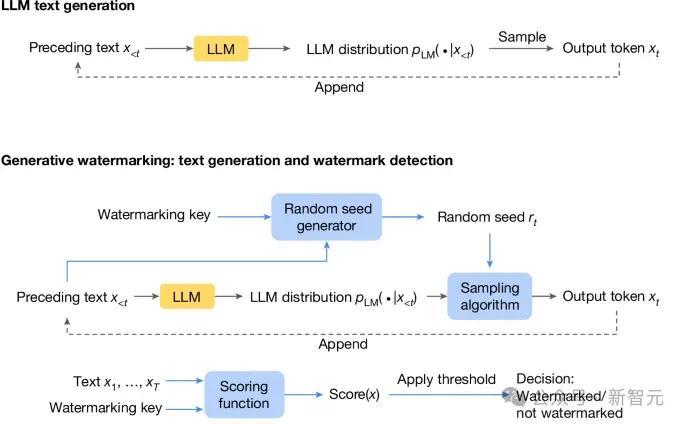
下图是标准的LLM生成流程:根据前一个token计算当前时刻token的概率分布,然后采样并输出下一个token。

在此基础上,水印生成方案由三个新增组件(下图中蓝色框)组成:随机种子生成器、采样算法和评分函数。
随机种子生成器在每个生成步骤 (t) 提供随机种子 r(t)(基于先前的文本标记和水印密钥),采样算法使用 r(t) 从生成的分布中采样下一个标记法学硕士。
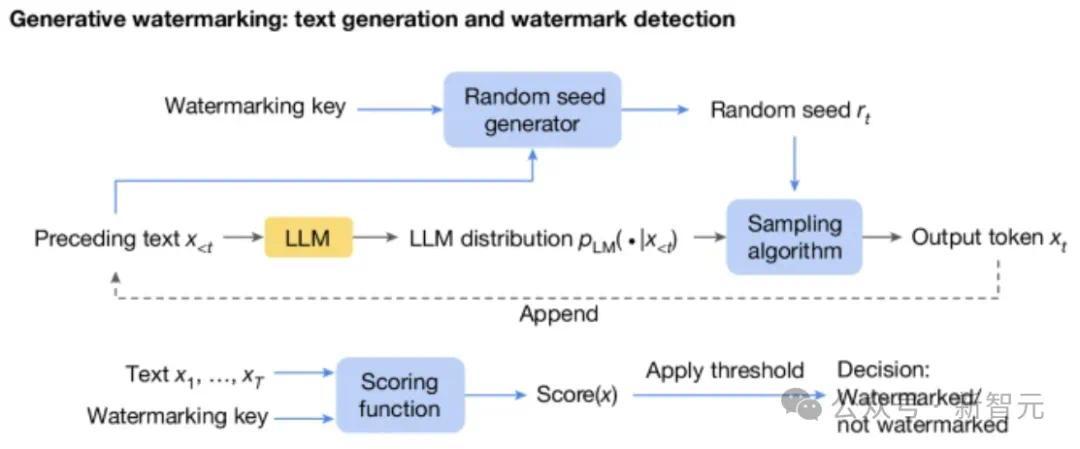
这样,采样算法将水印引入到下一个标记中(即r(t)和x(t)之间的相关性)。当检测水印时,评分函数用于测量这种相关性。
这是一个具体的例子:简单来说,将水印密钥和前几个令牌(这里是4),通过哈希函数传递,并生成m个向量。向量中的每个值对应于一个可选的下一个标记。

然后,通过参加比赛,选择这些令牌之一,这是 SynthID-Text 使用的锦标赛采样算法。
如下图所示,取2^m个代币参加m轮(这里是8个代币3轮,代币可以重复),
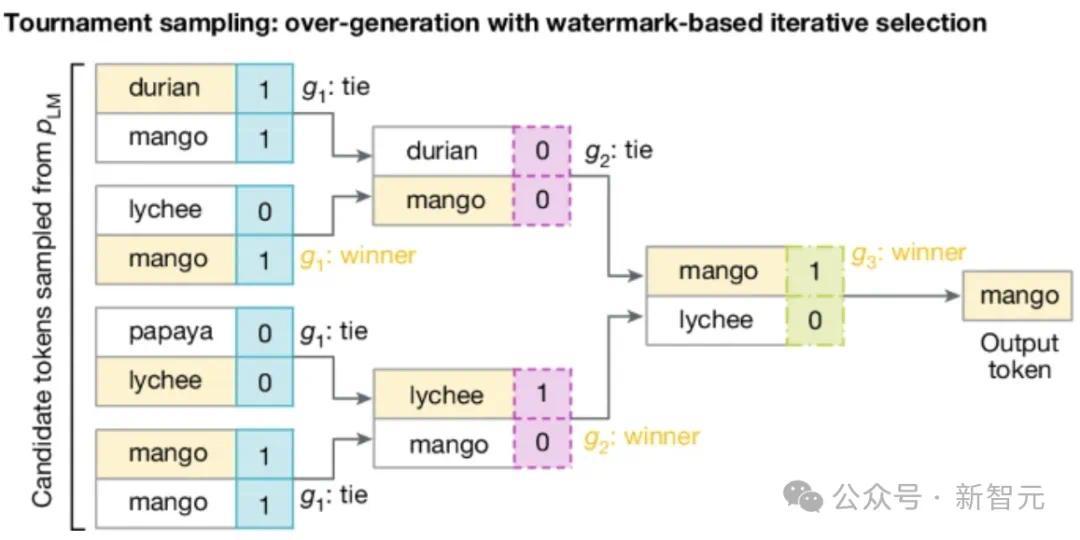
每轮中的令牌根据当前轮对应的向量进行配对。获胜者进入下一轮。如果平局,则随机选择获胜者。
下面是该算法的伪代码:

水印检测
根据上述竞赛系统,最终获胜的令牌更有可能在所有随机水印函数(g1,g2,...,gm)中具有较高的值。
因此,您可以使用以下评分函数来检测文本:
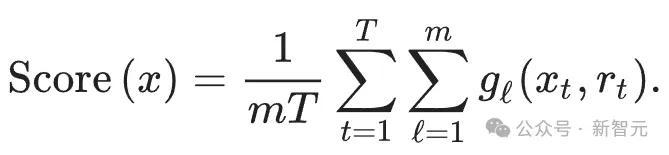
将所有标记放入所有水印函数中,最后计算平均值,那么带水印的文本通常应该比无水印的文本得分更高。
可见,水印检测是一个程度的问题。影响评分函数检测性能的因素主要有两个。
第一个是文本的长度:较长的文本包含更多的水印证据,从而在检测中提供更多的统计确定性。
第二个因素是LLM本身的情况。如果 LLM 输出分布的熵非常低(意味着同一提示几乎总是返回完全相同的响应),则锦标赛抽样无法选择在 g 函数下得分较高的标记。
此时,与其他生成水印的方案类似,对于熵较小的LLM,水印的效果会很差。
LLM本身的熵取决于以下因素:
模型(更大或更先进的模型往往更具确定性,因此熵更低);
根据人类反馈进行强化学习可减少熵(也称为模式崩溃);
LLM提示、温度和其他解码设置(例如top-k采样设置)。
一般来说,增加游戏的轮数(m)可以提高方法的检测性能并减少Scoring函数的方差。
然而,可检测性并不会随着层数的增加而无限增加。匹配的每一层都使用一些可用的熵来嵌入水印,随着层的深入,水印强度逐渐减弱。本文通过实验确定m=30。
文字质量
作者对于不失真从弱到强给出了明确的定义:
最弱的版本是单token不失真,即水印采样算法生成的token的平均分布等于LLM原始输出的分布;
更强的版本将此定义扩展到一个或多个文本序列,确保平均而言,水印方案生成特定文本或文本序列的概率与原始输出的分布相同。
当锦标赛采样为每场比赛恰好配置两名参赛者时,它是单令牌不失真的。并且如果应用重复的上下文掩码,则可以使一个或多个序列的方案不失真。
在本文的实验中,作者将SynthID-Text配置为单序列不失真,这样可以保持文本质量并提供良好的可检测性,同时在一定程度上减少响应之间的多样性。
计算可扩展性
生成水印方案的计算成本通常较低,因为文本生成过程仅涉及对采样层的修改。
对于锦标赛采样,在某些情况下也可以使用矢量化来实现更高的效率。实际上,SynthID-Text 造成的额外延迟可以忽略不计。
在大规模生产系统中,文本生成过程通常比前面描述的简单循环更复杂。
生产系统通常使用推测采样来加速大型模型的文本生成。
小编曾经在关于将Llama训练成Mamba的文章中介绍过大模型的推测解码过程。
简单来说,小模型是从原来的大模型中蒸馏出来的。小模型运行速度更快,首先生成一个序列。然后大模型验证序列。由于kv缓存的特性,不符合要求的token是可以找到的。精准回滚。
这种方式既保证了输出的质量,又充分利用了显卡的计算能力。当然,主要目的是加速。
因此,在实践中,水印生成解决方案需要与推测采样相结合,然后才能真正应用于生产系统。
对此,研究人员提出了两种具有推测采样算法的生成水印。
一种是高可检测性水印推测采样,它保留了水印的可检测性,但可能会降低推测采样的效率(从而增加总体延迟)。
第二种是快速水印推测采样,它(当水印是未失真的单个令牌时)保留了推测采样的效率,但可能会降低水印的可检测性。
作者还提出了一种可学习的贝叶斯评分函数来提高后一种方法的可检测性。当生产环境中速度很重要时,快速加水印推测采样最有用。
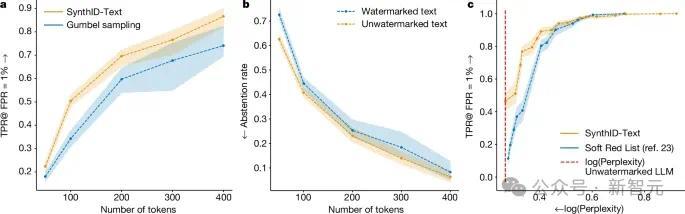
上图显示,在未失真类别中,对于相同长度的文本,未失真的SynthID-Text提供了比Gumbel采样更好的可检测性。在较低熵设置(例如较低温度)下,SynthID-Text 相对于 Gumbel 采样的改进更大。
