由 OmniSearch 团队贡献
量子比特 |公众号QbitAI
多模态检索增强生成(mRAG)也像o1思考和推理!
阿里巴巴统一实验室新研究推出自适应规划多模态检索代理。
名为OmniSearch,它可以模拟人类思考解决问题的方式,逐步拆解复杂问题进行智能检索规划。
直接看效果:
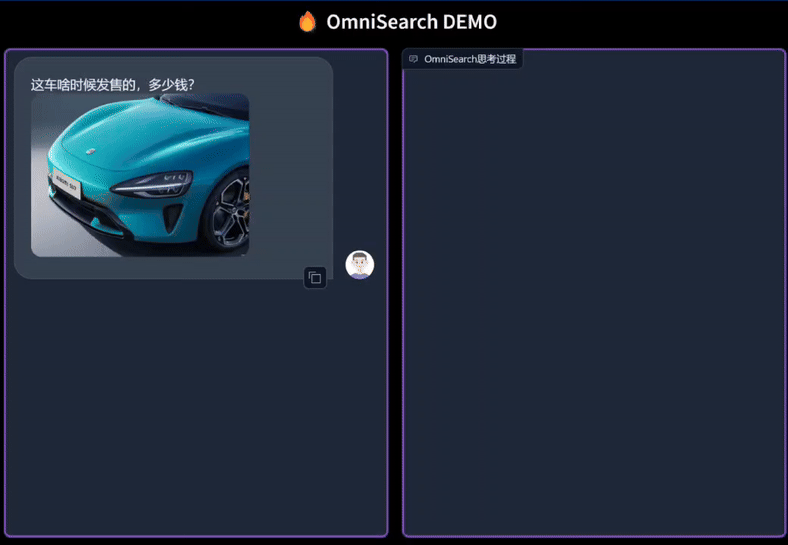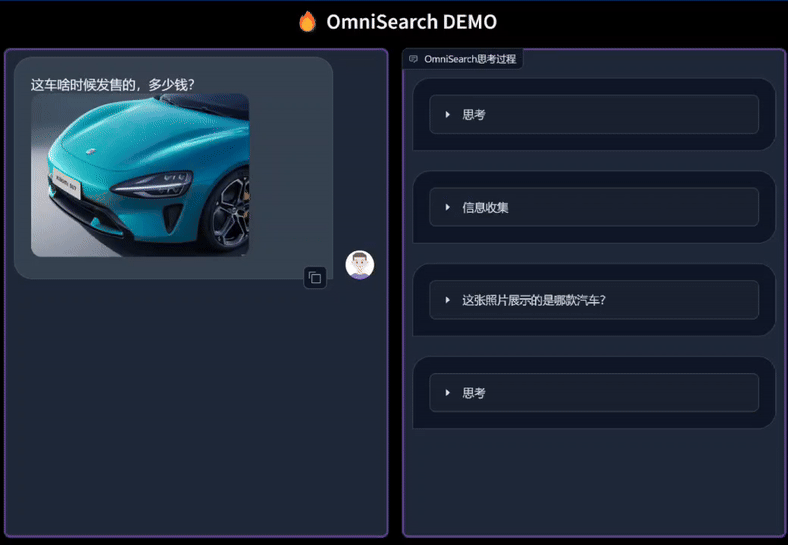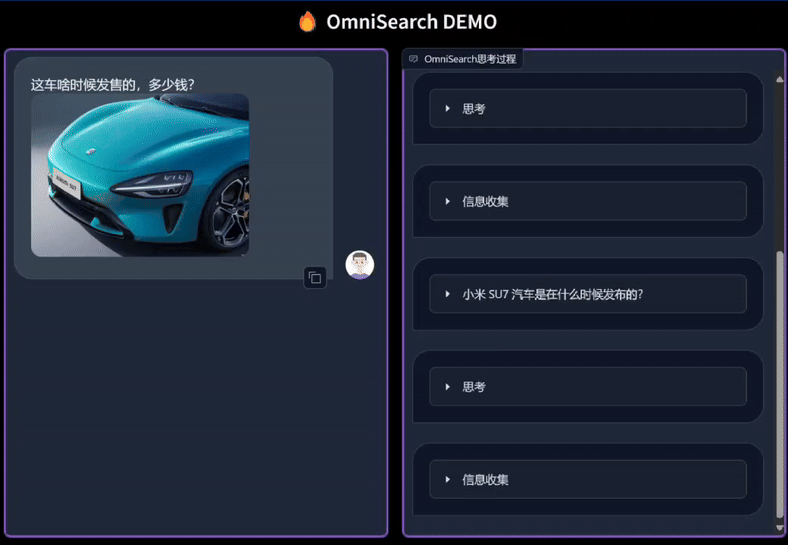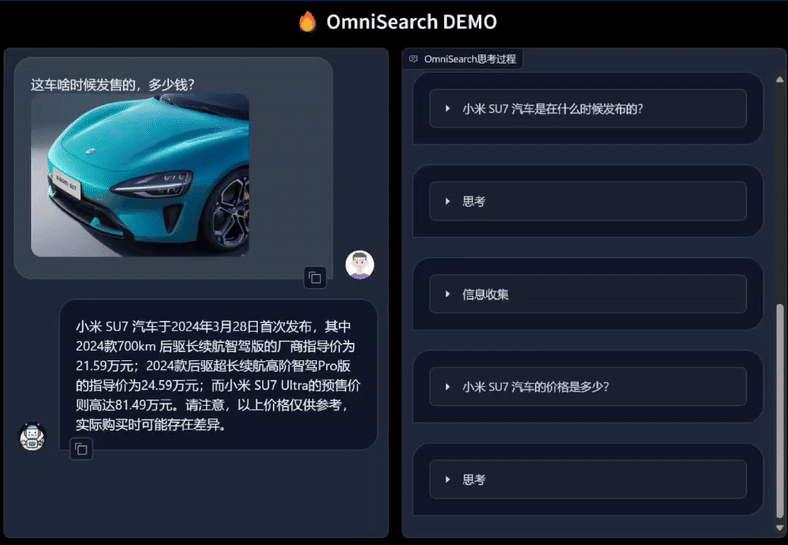
只需上传图片并提出任何问题,OmniSearch 就会经历一个“思考过程”。它不仅会分解复杂的问题进行检索,还会根据当前的搜索结果和问题上下文动态调整下一步的搜索策略。
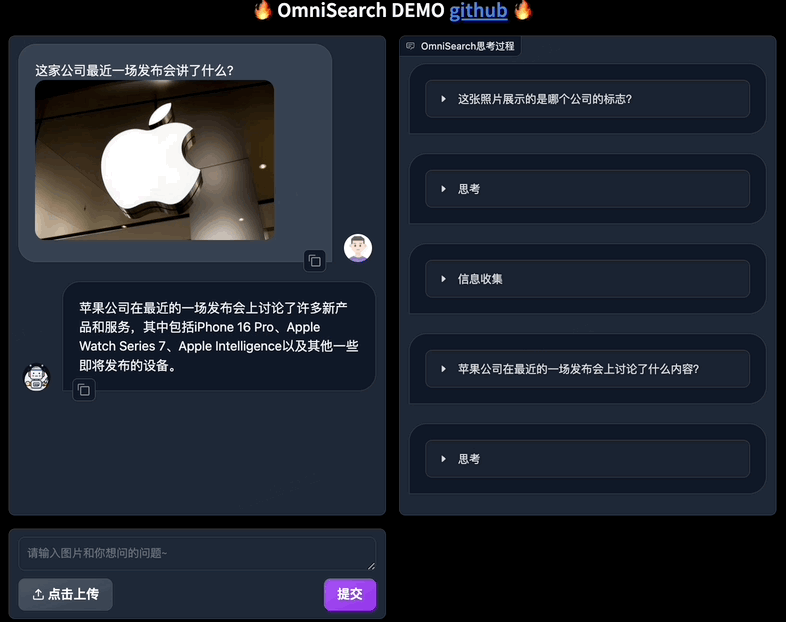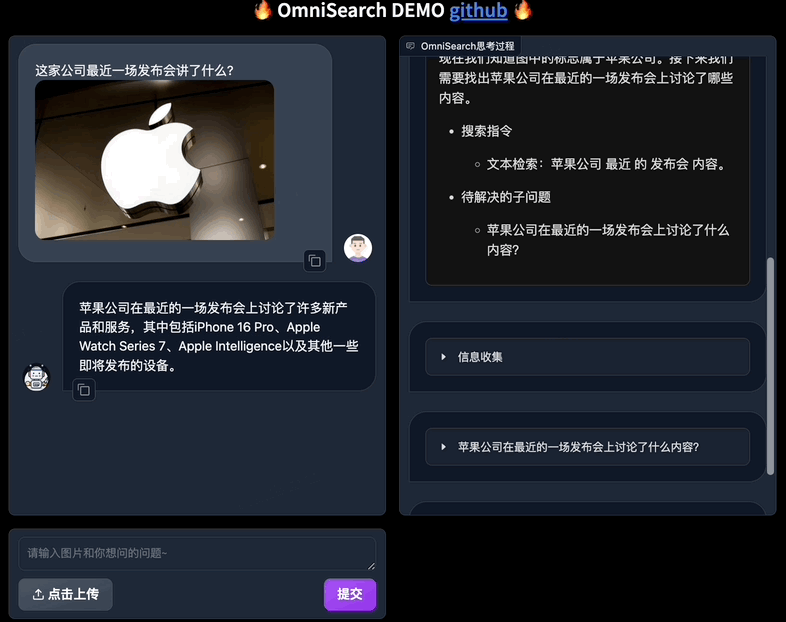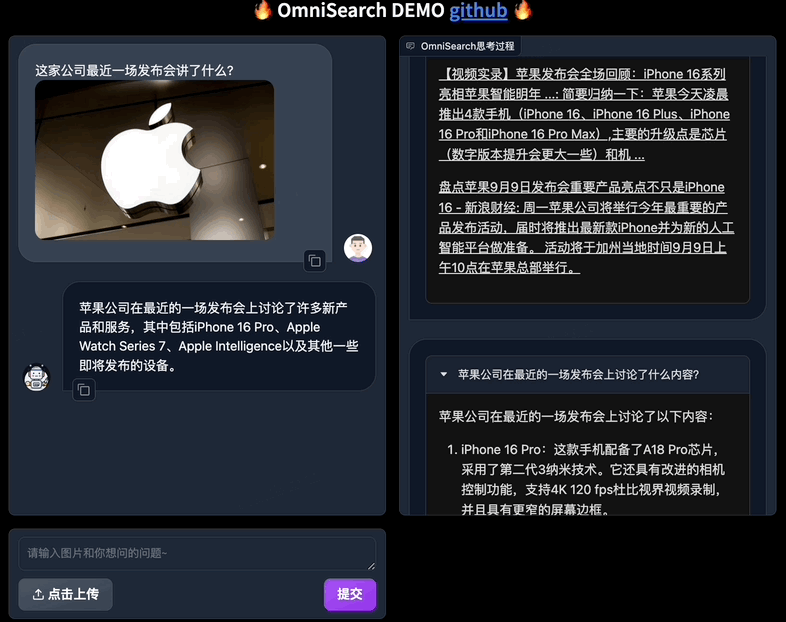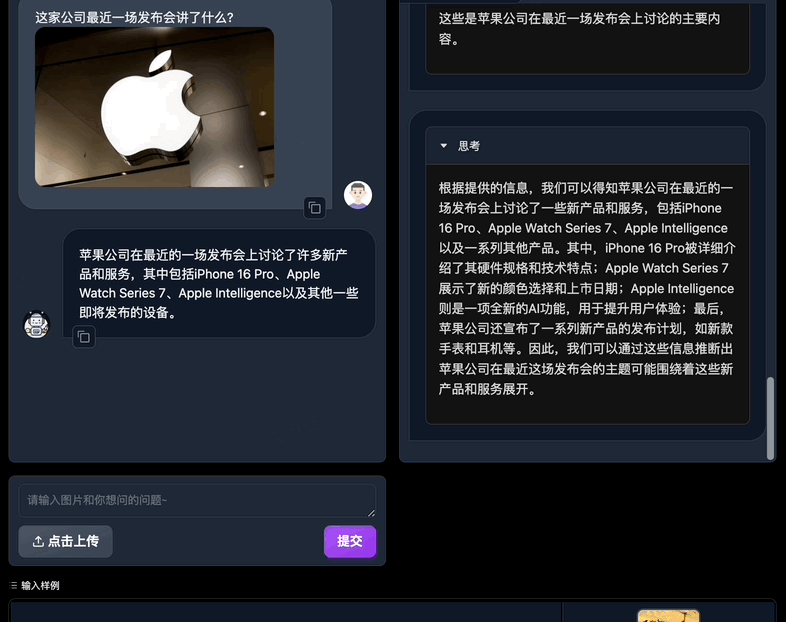
与传统mRAG受限于其静态检索策略相比,这种设计不仅提高了检索效率,而且显着增强了模型生成内容的准确性。
为了评估 OmniSearch,研究团队构建了一个新的 Dyn-VQA 数据集。
在一系列基准数据集的实验中,OmniSearch 展示了显着的性能优势。尤其是在处理需要多步骤推理、多模态知识和快速变化答案的问题时,OmniSearch 的表现比现有的 mRAG 方法更好。
目前,OmniSearch 仍然有一个可以在 Magic Community 中玩的演示版。
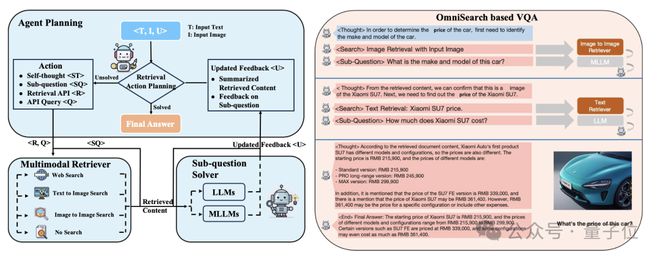
动态检索规划框架打破了传统mRAG的局限性
传统的mRAG方法遵循固定的搜索过程。典型步骤如下:
OmniSearch旨在解决传统mRAG方法的以下痛点:
为了克服上述限制,OmniSearch 引入了动态搜索规划框架。

OmniSearch 的核心架构包括:
构建新的数据集进行实验评估
为了更好地评估 OmniSearch 和其他 mRAG 方法的性能,研究团队构建了新的 Dyn-VQA 数据集。 Dyn-VQA包含1452个动态问题,涵盖以下三种类型:
这类问题需要比传统VQA数据集更复杂的检索过程,考验多模态检索方法规划复杂检索的能力。

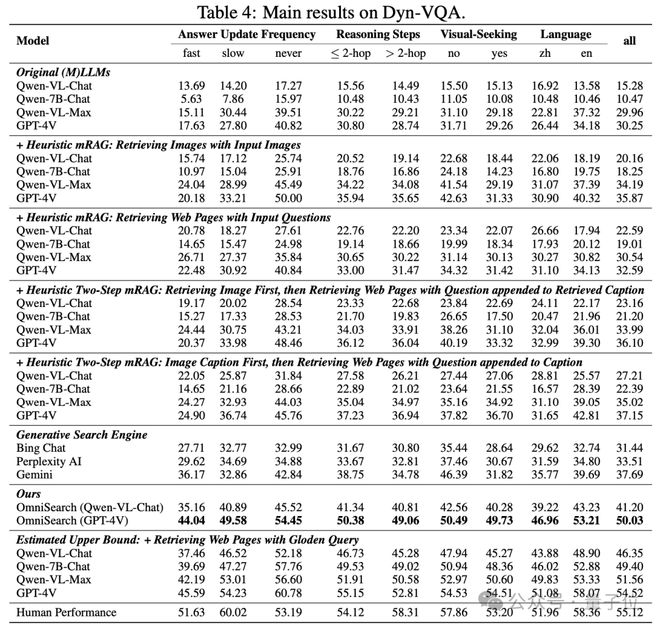
Dyn-VQA 数据集上的性能
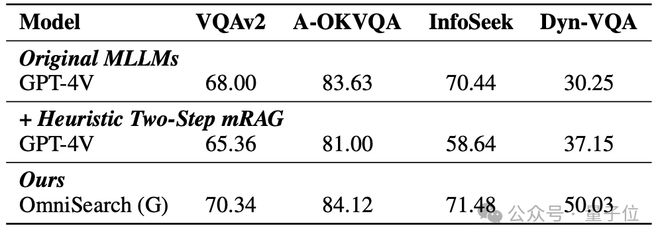
其他数据集上的表现
接近人类水平的性能:
OmniSearch 在大多数 VQA 任务上实现了接近人类水平的性能。例如,在VQAv2和A-OKVQA数据集中,OmniSearch的准确率分别达到70.34和84.12,显着超越传统的mRAG方法。
复杂问题处理能力:
在更具挑战性的 Dyn-VQA 数据集上,OmniSearch 通过多步检索策略显着提高了模型的性能,达到了 50.03 的 F1-Recall 分数,这几乎比基于 GPT 的传统两步检索方法有所提高。 4V。 14分。

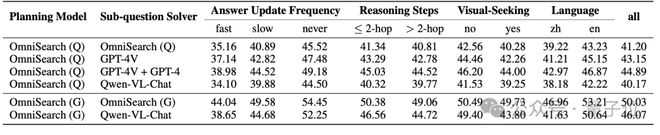
模块化和可扩展性
OmniSearch 可以灵活地集成不同规模和类型的多模态大语言模型(MLLM)作为子问题求解器。
无论是开源模型(如Qwen-VL-Chat)还是闭源模型(如GPT-4V),OmniSearch都可以通过动态编程与这些模型协作来解决复杂问题。
其模块化设计允许根据任务需求选择最合适的模型,甚至可以在不同阶段调用不同规模的MLLM,以实现性能和计算成本之间的灵活平衡。
以下是OmniSearch和不同模型的实验结果:
纸:
GitHub:
模型范围演示:
