PhysVLM 团队的贡献
量子比特 |公众号QbitAI
融合物理知识的大规模视频语言模型PhysVLM开源了!
它不仅在 PhysGame 基准测试中显示出最先进的性能,而且在通用视频理解基准测试(Video-MME、VCG)上也显示出领先的性能。
在这项研究之前,让人工智能像人类孩子一样通过观察世界来理解基础物理是一项重大挑战。

对于现实世界的视频来说,全面覆盖和解释所有正常的物理现象既困难又不必要。
相比之下,游戏视频往往包含违反物理学常识的“小故障”,这有助于简化对物理学常识理解的定义和评估,重点是解释违反物理学常识的行为,而不是试图列举所有正常的物理现象。存在。
为此,PhysVLM 在一组专门策划的数据集上进行训练,包括用于评估的 PhysGame 基准、用于监督微调的 PhysInstruct 数据集以及用于偏好对齐的 PhysDPO 数据集。
PhysGame 基准测试设计
如图所示,PhysGame包含880个包含故障的游戏视频。每个视频都配有高质量的多项选择题,专门注释了故障的性质。
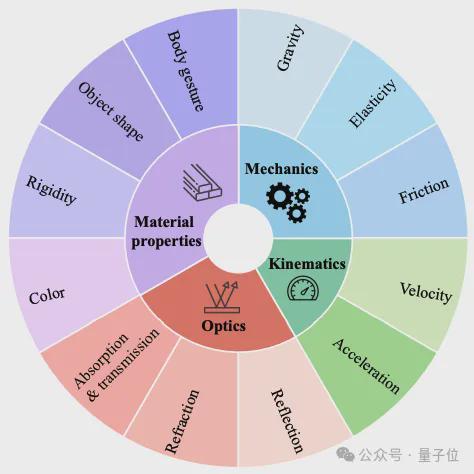
△PhysGame品类分布
PhysGame 涵盖物理学的四个关键领域(即力学、运动学、光学和材料特性),分为 12 个特定类别(即重力和速度)。
PhysGame 基准测试构建
视频采集和过滤:
PhysGame 中的视频主要从 Reddit 页面抓取,其中包含存在异常事件和故障的游戏视频。为了平衡不同类别,团队还通过关键字搜索增强了 YouTube 的视频数据。团队根据以下两个标准进行人工筛选:
选项生成:
本文以多项选择题的形式创建问答对。具体来说,正确选项描述了视频中违反物理常识原理的具体故障现象。为了增强干扰选项的可信度,本文要求干扰选项中的故障现象应与视频中观察到的个人或行为高度相关,这使得视频LLM能够了解故障内容而不仅仅是选择它通过识别所包含的对象或动作来实现。回答。
质量控制:
为了保证数据集的质量,本文进行了包括人工检查和自动LLM辅助检查的双重质量控制流程:

△PhysGame示例
PhysInstruct&PhysDPO数据集构建
物理指导:
为了提高视频LLM的物理知识理解,团队开发了PhysInstruct数据集用于监督微调。视频采集过程与PhysGame中相同。为了防止数据泄露,团队严格排除 PhysGame 中包含的任何视频。该团队遵循自指导范例,通过提示 GPT-4o 来构建 PhysInstruct。
物理DPO:
该团队构建了偏好对齐数据集 PhysDPO,以提供更值得信赖和可靠的答案。如图3所示,团队将PhysInstruct数据集中生成的答案视为首选答案,而不首选答案是通过元信息黑客、时间黑客和空间黑客生成的。 。该团队通过误导性元信息以及减少帧数和帧分辨率的视频帧来推动 GPT-4o。
以下是PhysDPO数据集构建流程图:
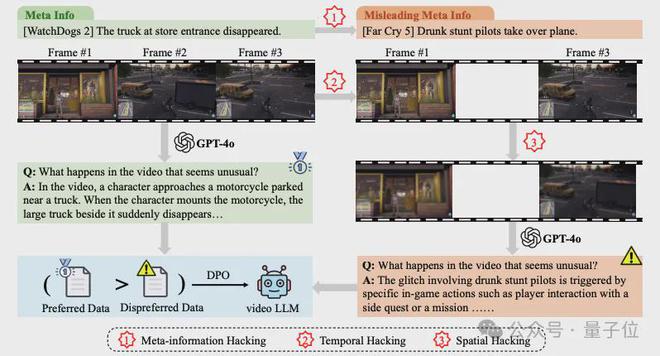
模型评估与分析
PhysGame基准实验结果:
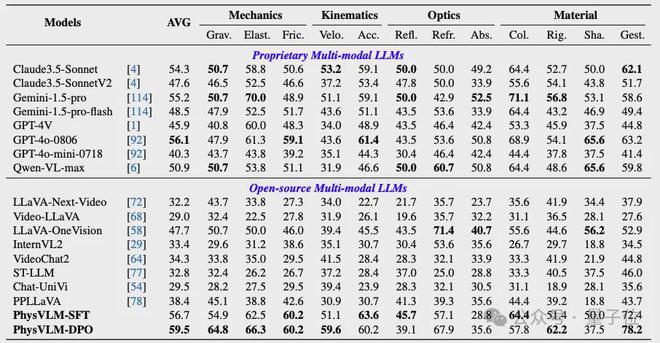
△PhysGame基准实验结果
Video-MME基准测试结果:
本文中的 PhysVLM 模型在所有 7B 模型中表现优越。令人惊讶的是,作为 7B 模型,PhysVLM-SFT 和 PhysVLM-DPO 与 34B 模型 LLaVA-NeXT-Video 相比,整体性能绝对值分别提高了 3.2% 和 3.8%。通过比较 PhysVLM-SFT 和 PhysVLM-DPO,团队发现使用建议的 PhysDPO 数据进行 DPO 训练提高了短视频和长视频的性能,而中等长度视频的性能略有下降。
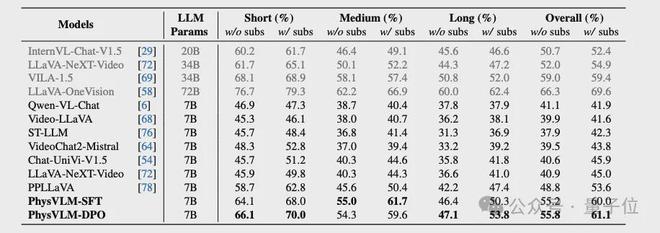
△Video-MME benchmark实验结果
VCG基准实验结果:
在仅使用 SFT 的模型中,我们的 PhysVLM-SFT 在平均得分方面表现最好。在四个子类别评估中,PhysVLM-SFT 在信息正确性和一致性类别中表现尤其出色。与使用DPO或PPO训练的PPLLaVA和LLaVA-Next-Video相比,本文的PhysVLM-DPO也表现出了优异的性能,进一步验证了所提出的PhysVLM模型在一般视频理解方面的优异能力。
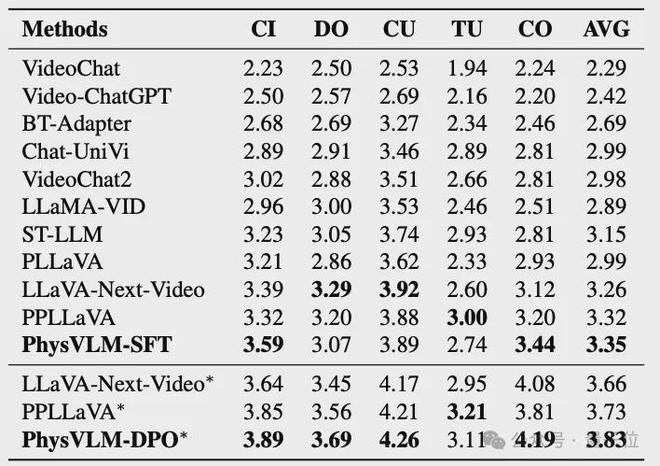
△VCG基准实验结果
PhysVLM相关论文、代码、数据全部开源:
预印本:
代码链接:
排行榜:#leaderboard
