
12月9日晚间,国家市场监管总局发布公告称,近日,英伟达涉嫌违反《中华人民共和国反垄断法》,国家市场监管总局批准英伟达收购股权Mellanox 科技有限公司的附加限制性条件。 《关于反垄断审查决定的公告》(国家市场监督管理总局公告2020年第16号),国家市场监督管理总局依法对英伟达发起调查。
英伟达今天在回应调查时表示,“我们努力在每个地区提供最好的产品,并在我们开展业务的任何地方履行我们的承诺。我们很乐意回答监管机构对我们业务提出的任何问题。”
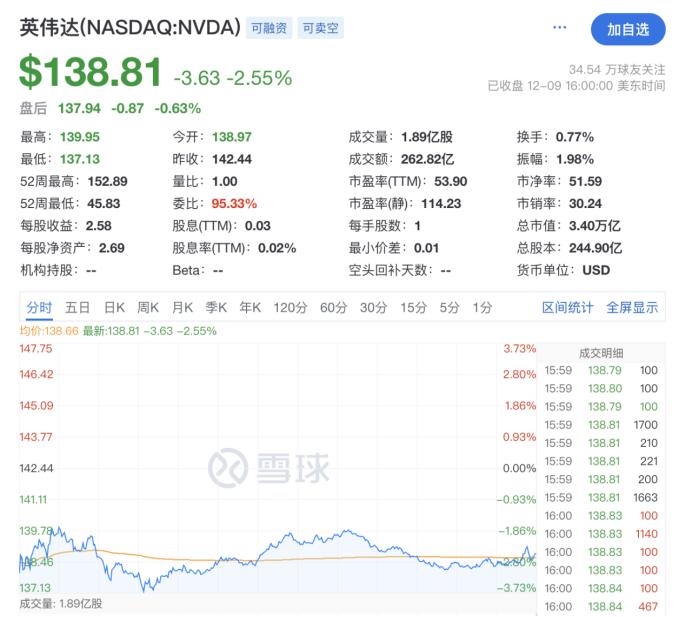
受此事件影响,英伟达股价当天(9日)下跌2.55%,市值一夜蒸发889亿美元(约合人民币6460亿元),超过英特尔市值(897.54亿美元)。
美国和英国先后调查,发现英伟达并非中国针对的目标。
NVIDIA作为全球GPU算力的绝对领导者,在AI大模型时代占据着不可替代的地位。在大型AI模型成为业界关注焦点的过去几年,其产品作为重要的大型模型训练和推理硬件设施,一直处于“供不应求”的状态。
富国银行数据显示,2023年英伟达在全球数据中心GPU市场的份额将高达98%,遥遥领先第二名AMD的1.2%和第三名英特尔的不足1%。
其中,英伟达在中国市场的收入占其全球总收入的12.7%。 2024年前三季度,英伟达在中国大陆和香港的营收达到115.7亿美元。
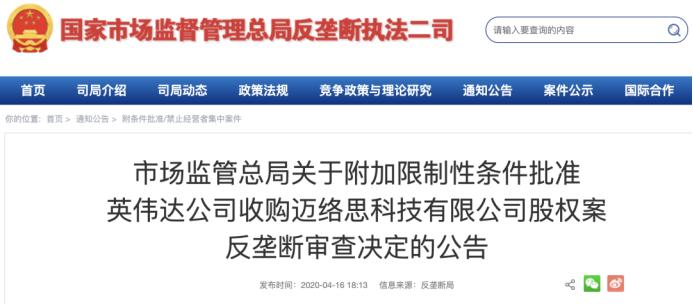
此次对NVIDIA的调查主要是基于公告中的另一则公告,即《国家市场监督管理总局关于批准英伟达收购Mellanox科技有限公司股权反垄断审查决定的公告》。带有限制性条件的 NVIDIA”(国家市场监督管理总局)。公告(2020)第16号)。
2019年,英伟达宣布以69亿美元高调收购以色列网络设备供应商Mellanox。收购完成后,Mellanx成为NVIDIA的全资子公司。由于Nvidia和Mellanox在全球都拥有垄断地位,此次合并对全球市场具有潜在影响。因此,本次交易随后获得了美国、欧盟、中国等国家和地区市场监管机构的批准。
2020年4月16日,中国国家市场监督管理总局有条件批准本次收购。它是最后批准交易的国家,也是决定收购是否成功的关键。国家市场监管总局要求英伟达在交易完成后六年内按照公平、合理、非歧视的原则继续向中国市场供应相关产品,不得强行搭售或附加不合理交易状况。
然而,自2022年以来,英伟达多次切断对中国市场的GPU产品供应,涉嫌违反这些承诺,从而引发中国反垄断执法机构的调查。
中国的反垄断调查并非孤例。今年8月,美国司法部对英伟达发起反垄断调查,重点调查其在人工智能芯片销售方面的市场主导地位。 12月7日,欧盟也对英伟达发起反垄断审查,进一步加强对其在全球市场影响力的监管。
美国司法部反垄断部门负责人乔纳森·坎特指出,英伟达主导了最先进GPU的销售,使得这一资源变得稀缺,影响了市场竞争格局。为了打破垄断,美国政府还通过《芯片法案》促进国内芯片生产,并提供390亿美元的激励措施。
英伟达不仅面临反垄断监管,还面临美国对华出口管制的诸多限制。 2022年以来,美国不断升级半导体出口限制,禁止英伟达A100、H100等高性能GPU芯片及其替代品向中国出口。这些措施不仅阻碍了英伟达对中国市场的供货,也与其在中国的业务承诺相冲突。
尽管Nvidia试图推出其A800和H800芯片的特别版本,但这些产品仍然受到严格的出口管制。还有消息称,其计划于2024年推出的H20等AI芯片的量产计划也已暂停。
华为、必仁、摩尔线程谁是赢家?
对于英伟达本身来说,完全放弃中国市场意味着其营收和利润将减少至少15%-20%。随着英伟达因“反垄断”调查而在中国市场面临不确定性,国内GPU厂商的崛起成为人们关注的焦点。这不仅关系到你我用来玩游戏的PC级GPU产品,更重要的是为toB市场提供AI加速芯片。
大样板屋注意到,华为、必人科技、摩尔线程等公司正在以不同的方式填补这一空白。他们在硬件性能、开发生态、产业链支持等方面展开了激烈的竞争。
华为Ascend系列:算力领先,但生态有待完善

华为Ascend A910系列芯片峰值算力高达256-280 TFLOPS(FP16),性能接近NVIDIA A100的312 TFLOPS。实际使用中,NPU算子优化后的算力达到A100的80%左右,表现比较突出。但华为在高速互联网和开发者生态方面的短板还是比较明显的。例如,其HCCS互连技术仅支持不到100GB/s的带宽,与NVIDIA NVlink的1800GB/s有显着差异。
在软件支持方面,华为受限于资源投入,短期内仍需追赶NVIDIA多年来打造的CUDA开发生态。
必人科技:定位AI算力强、灵活但通用性存疑
必人科技的BR100芯片以其强大的AI算力而闻名。其16位浮点运算能力超过1000 TFLOPS,峰值运算能力达到PFLOPS级别。必人与浪潮科技合作,推出基于BR100的“海选”服务器集群,针对高能效AI计算场景。然而,其牺牲 FP16 通用计算能力并专注于矩阵运算的策略可能会限制其在多种场景中的适用性。
比人在硬件算力方面拥有显着领先优势,但在开发生态和市场应用支撑方面仍需努力。与华为相比,Biren更适合特定的AI任务而不是大规模的通用计算需求。
摩尔之脉:从游戏到人工智能的飞跃

Moore Threads以游戏GPU起家,逐步推进在AI加速领域的探索。其最新发布的MTT S4000智能计算加速卡支持多卡互联,拥有48GB显存和240GB/s片间互联带宽,主打分布式计算能力。通过自研的MUSIFY工具,Moore Thread实现了CUDA代码的迁移,试图打破NVIDIA生态系统的壁垒。
此外,国内目前也有寒武纪、绥远、木希、景嘉威等多家企业,但在规模、技术、产业链成熟度等方面仍落后于前者。
尽管硬件参数接近国际主流产品,但摩尔线程在超算集群搭建和软件优化方面仍面临挑战。从市场定位来看,更偏向中小型AI场景,与华为、必人互补,但整体技术深度不足以支撑大型企业的需求。
虽然纸面上的参数看起来很接近,但AI卡的性能是由四个方面决定的:库、计算能力、显存和高速互连。不仅要具备基本的单卡算力,更重要的是需要支持万卡、十万卡,甚至更大的算力集群。内存、并行传输能力将受到极大考验。
这是 NVIDIA 具有优势的领域。 NVIDIA在高速互连技术NVlink上也拥有压倒性的优势。其1800GB/s带宽远超国内竞争对手,已成为超大规模AI计算集群的关键技术。
在单卡计算能力和互联网带宽方面,虽然国内厂商不断缩小与NVIDIA的差距,但后者的优势主要集中在开发者生态和软件支持上。早在2006年,NVIDIA就开始构建CUDA生态系统,通过高效的汇编代码和丰富的工具链为AI计算提供强有力的支持。
为了稳定自己的生态系统,2024年3月,NVIDIA在CUDA 11.6的用户许可中明确表示,禁止在其他硬件平台上通过翻译层运行CUDA。 NVIDIA 禁止第三方使用 CUDA。适用于ZLUDA及其他涉及Intel、AMD的第三方项目,以及登林科技、木希科技等中国厂商的兼容解决方案。
考虑到To B行业,只有华为拥有稳定的供应能力和强大的综合实力,未来可能成为中国市场的最大受益者。不过,有服务器经销商告诉笔者,目前910B服务器的价格已经超过170万元,价格甚至一度超过了NVIDIA服务器。
在大车型发展的道路上,我们必须正视差距,这样才能赶超。未来,中国要在人工智能大模型的竞争中保持全球领先,不仅要实现GPU等硬件技术的自主创新,还要推动数据治理、应用落地和生态系统的全面发展。这不仅是一场技术竞争,更是一场产业竞争的整体之战。
本文来自微信公众号“大样板房”,作者:乔志斌,36氪经授权发布。
