DeepMind 的研究人员开发了一种新的视频分层方法,通过将视频分解为包含对象及其效果(例如阴影和反射)的多个层来提高视频质量,而无需假设背景静止或精确的相机姿势。编辑灵活性和效率。
视频数据通常包含动态世界中的复杂信号,例如摄像机运动、关节运动、复杂场景效果以及对象之间的交互。
如果能够将视频自动分解为一组有语义意义的半透明图层来分离前景物体和背景,类似于PS中的图片,那么可以大大提高视频编辑的效率和直观性。
在推断物体及其效果之间复杂的时空相关性时,现有方法只能处理具有精确相机和深度估计数据的静态背景或视频,而无法完成遮挡区域,这极大地限制了应用范围。 。

近日,来自谷歌DeepMind、马里兰大学帕克分校和魏茨曼科学研究所的研究人员联合提出了一种新的分层视频分解框架,可以在不假设背景是静态的情况下生成视频,并且不需要相机姿态或深度信息。图像层次清晰完整,甚至能够完成被遮挡的动态区域。

论文链接:
项目地址:
该框架的核心思想是训练视频扩散模型,并利用其强大的生成先验知识来克服先前方法的局限性。
1.模型的内部特征可以揭示物体和视频效果之间的联系,类似于将视频扩散模型的内部特征应用到分析任务中;
2.该模型可以直接利用先验完成层分解中的遮挡区域,包括动态区域,而之前的方法无法在先验信息有限的情况下实现。
在实验阶段,研究人员验证只需要一个精心策划的小型数据集来处理日常捕获的包含柔和阴影、光泽反射、泼水等各种元素的视频,并最终输出高质量的分解和编辑。结果。

最牛逼的“视频分层”模型
由于真正的分层视频数据很少,并且预训练模型已经在生成任务中学习了对象之间的关联及其效果,因此我们希望通过使用小型分层视频数据集微调模型来利用这种能力。微调。
基本视频扩散模型
研究人员开发了 Casper,这是一种基于文本到视频生成器 Lumiere 的模型,用于移除物体及其影响。
基本模型Lumiere首先根据文本提示生成分辨率为128×128像素的80帧视频,然后使用空间超分辨率(SSR)模型将基本模型的输出上采样到分辨率为1024× 1024 像素。
Lumiere修复模型对原始模型进行微调,输入条件为“蒙版RGB视频”和“二进制蒙版视频”,然后使用相同的SSR来实现高分辨率质量。
Casper基于修复模型进行了微调,去除了物体和视频效果,同时保持了相同的模型架构。
使用三元蒙版去除对象和效果
原始的 Lumiere 修复模型需要输入二进制掩码来指示需要修复(修复)的区域和需要保留的区域。
Casper还引入了额外的不确定性,即所谓的“保留”区域并未完全保留,目标区域可能会被修改以消除阴影。
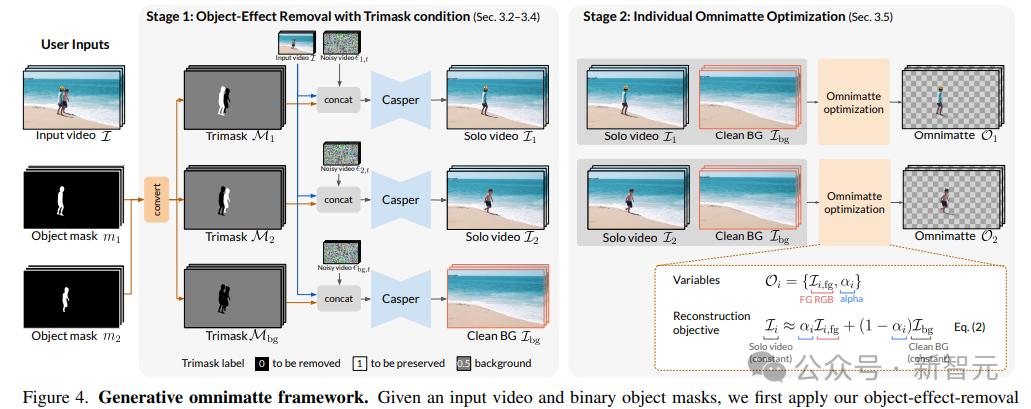
研究人员提出了三元掩模(Trimask)条件M来区分需要去除的物体(M=0)、需要保留的物体(M=1)以及可能包含需要去除或去除效果的背景区域。保留(M = 0.5)。
为了获得干净的背景视频,使用背景三元掩模将所有对象标记为需要去除的区域,将背景标记为可能需要修改的区域。
使用 SegmentAnything2 获取二进制对象掩码,然后将单个对象标记为保留区域,将其余对象标记为删除区域。
在推理过程中,Casper 的输入包括描述目标移除场景的文本提示、输入视频、三元掩码以及 128 像素分辨率的噪声视频串联。
该模型在没有分类器自由指导的情况下执行 256 个 DDPM 采样步骤进行推理(80 帧视频大约需要 12 分钟),采用时间多重扩散技术来处理较长的视频。
影响视频生成器中的相关先验
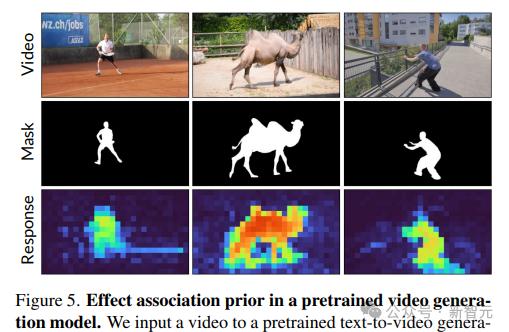
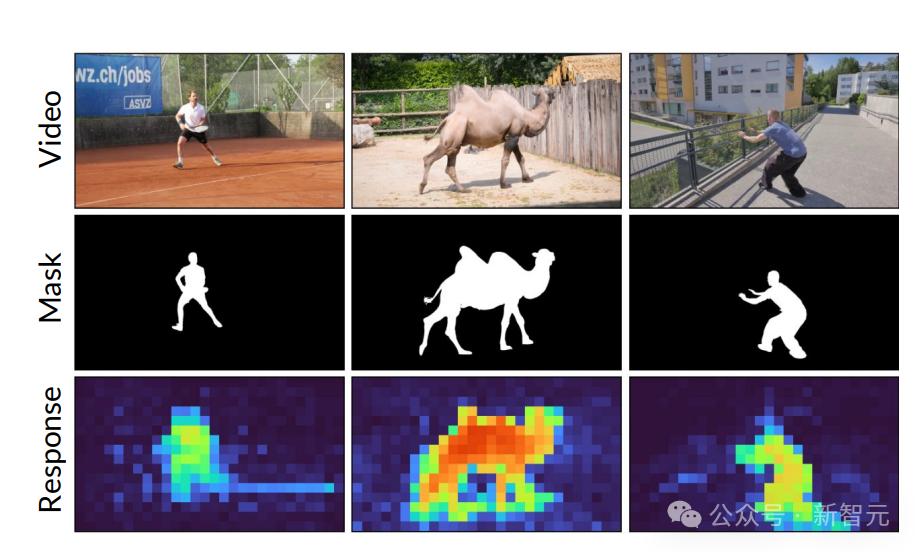
为了探索 Lumiere 对对象效果关联的内在理解,研究人员使用 SDEdit 分析了给定视频去噪期间的自注意力模式,测量与感兴趣对象相关的查询标记和关键标记之间的自注意力。重量。
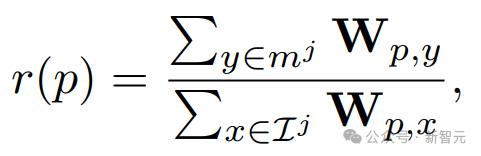
可以看出,阴影区域中的查询标记对对象区域表现出更高的关注值,表明预训练模型可以有效地将对象及其效果关联起来。
训练数据结构
研究人员构建了一个训练数据集,其中包含来自四个类别的真实和合成视频示例。

Omnimatte,从现有方法的结果中收集31个场景,形成输入视频、输入三元、掩模和目标背景视频的训练元组。场景主要来自 DAVIS 数据集,具有静态背景和单个对象,包含来自真实世界视频的阴影和反射。
三脚架通过互联网补充了 15 个视频,由固定摄像机拍摄,包含进入和退出场景的物体、水效果(例如反射、飞溅、涟漪)和环境背景运动。然后使用 Ken Burns 效果增强视频以模拟摄像机运动。
Kubric 包含 569 个复合视频,在 Blender 中渲染多对象场景并使对象透明。此外,研究人员观察到,许多现实世界的场景在一个场景中会显示同一类型物体的多个实例,例如狗、行人或车辆,因此他们还故意生成包含重复物体的场景来训练模型处理多个物体类似的物体。 。
Object-Paste,从 YouTube-VOS 数据集中的真实视频合成 1024 个视频元组,使用 SegmentAnything2 从随机视频中裁剪对象,并将其粘贴到目标视频上。训练输入和目标分别是合成视频和原始视频,可以增强模型的修复和背景保留能力。
训练数据的文本线索由BLIP-2描述,描述物体效果去除模型应该学习生成的目标视频;该数据集通过空间水平翻转、时间翻转和随机裁剪增强至 128 × 128 像素分辨率。
实验结果定性分析
在下面的“船”示例中,现有方法无法将船的尾流与背景层分开,而本文提出的方法可以将其正确放置在船层中。

在“马”的示例中,Omnimatte3D 和 OmnimatteRF 无法恢复最后一行中被遮挡的马,因为 3D 感知背景表示对相机姿态估计的质量非常敏感,因此背景层非常模糊。
在对象去除方面,视频修复模型无法去除输入蒙版之外的软阴影和反射; ObjectDrop 可以消除卡通和跑酷中的阴影,但独立处理每个帧并修复没有全局上下文的区域。可能导致不一致的幻觉。
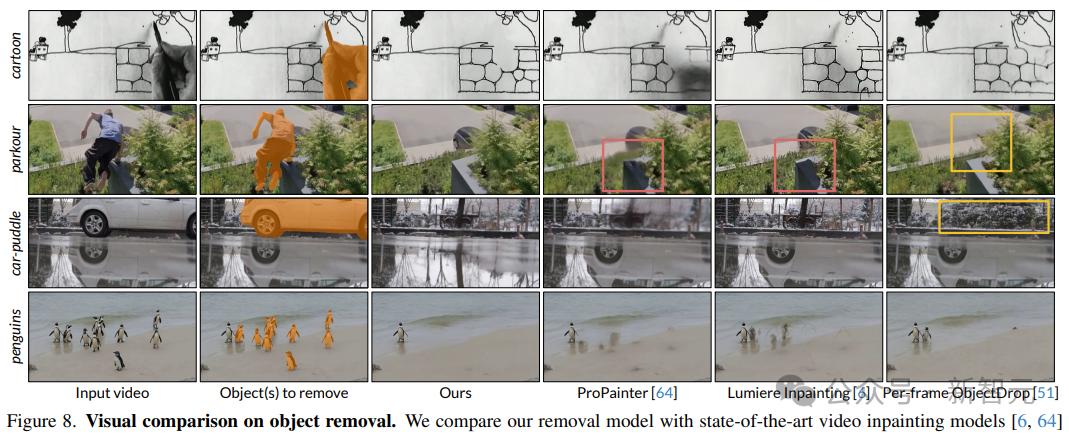
定量分析
研究人员使用 OmnimatteRF 评估协议评估了 10 个合成场景的背景层重建效果,其中包括 5 个电影场景和 5 个 Kubric 生成的场景。每个场景都有相应的真实背景,不包含前景物体和效果。
峰值信噪比 (PSNR) 和学习感知图像块相似度 (LPIPS) 用作评估指标。
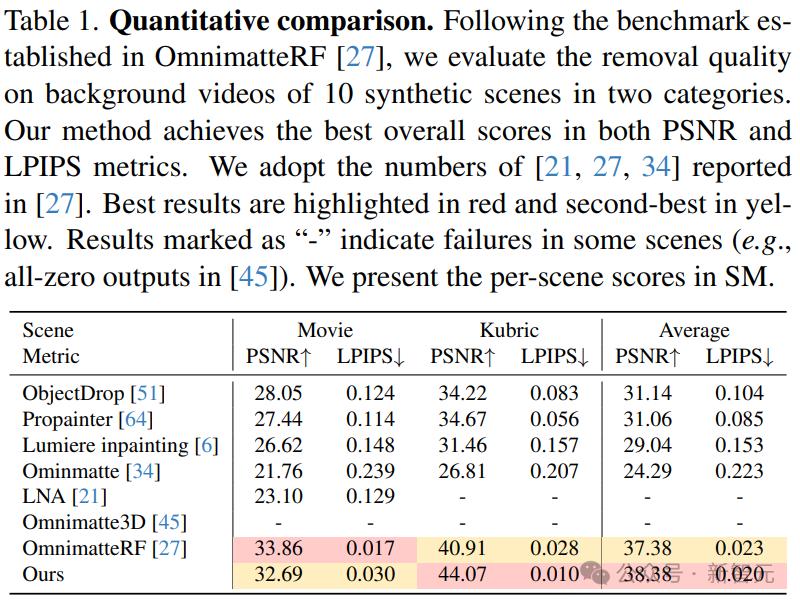
结果表明,Omnimatte 和 Layered Neural Atlas 使用 2D 运动模型,因此难以处理视差; Omnimatte3D 在两种情况下未能构建背景场景模型,并且难以处理电影场景中的静止前景对象。
总的来说,我们的方法在这两个指标上都实现了最佳性能。
参考:
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
