怪月来自奥飞寺量子比特|公众号QbitAI
快8倍!
速度更快、效果更好的混元视频模型——FastHunyuan来了!
新模型只需1 分钟即可生成5 秒长视频,比之前快了8 倍。步骤从50个减少到6个,甚至画面细节也更加真实。

与普通速度混元相比,以前需要50步才能生成一个视频,但现在新模型可以同时生成8个视频。

我们来看一下和Sora的图片对比。我们可以看到,Fast-混元和空的效果更加真实,衣服、水果和山峰的细节也非常清晰。




Fast-Hunyuan在一些物理细节的理解上什至比Sora还要好,比如下面的吃柠檬的视频:

更重要的是,Fast-Hunyuan的代码也是开源的,所以你不用担心Sora的订阅费用和限制。
该研究团队来自加州大学圣地亚哥分校(UCSD)的Hao AI实验室。他们主要专注于机器学习算法和分布式系统的研究。


混源公众号还专门发博感谢他们:
有网友看完后表示,混元是最好的开源视频模型。
开创性的视频DiT 蒸馏配方
团队如何在提高视频清晰度的同时实现8 倍的加速?
我们来看看Fast-Hunyuan的技术原理——
首先,他们开发了全新的视频DiT 蒸馏配方
具体来说,他们的蒸馏配方基于阶段一致性模型(PCM)
在尝试多级蒸馏并发现没有显着改进后,他们最终选择保留单级设置,类似于原始PCM 模型。
其次,团队使用OpenSoraPlan中的MixKit数据集进行蒸馏。
为了避免在训练期间运行文本编码器和VAE,该团队还预处理了所有数据以生成文本嵌入和VAE 潜在变量。
在推理阶段,用户可以通过FSDP、顺序并行性和选择性激活检查点进行可扩展训练,模型可以近乎线性地扩展到64 个GPU。测试代码在Python 3.10.0、CUDA 12.1和H100上运行。
官方建议使用80GB显存的GPU。不同的模型有对应的下载权重和推理命令。
最低硬件要求如下:
在模型微调方面,Fast-Hunyuan提供了两种方法:全量微调(必须准备符合格式的数据,并提供一些可下载的预处理数据和相应的命令)和LoRA微调(即将上线) )。
此外,它们还将预先计算的潜在变量与预先计算的文本嵌入相结合。用户可以根据自己的硬件情况选择不同的微调方式来执行命令,还支持图像和视频的混合微调。

该模型已于2024年12月17日发布v0.1版本。
未来的发展计划还包括添加更多的蒸馏方法(例如分布匹配蒸馏)、支持更多的模型(例如CogvideoX模型)以及代码更新(例如fp8支持、更快的加载和保存模型支持)等。

还有一件事
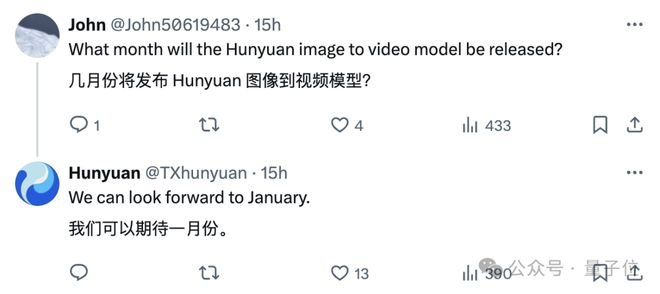
除了模型加速之外,混元还预览了大家期待的图像转视频生成功能。
最快一月,也就是下个月就可以看到了!期待它。

GitHub:
拥抱脸:
[1]
