140亿参数,40%合成数据,年度SLM王者诞生!
近日,微软新一代小机型Phi-4正式亮相。在GPQA和MATH基准上,其数学性能直接超越GPT-4o和Gemini Pro 1.5。
此外,Phi-4 碾压了其他小型型号,并与 Llama-3.3-70B-Instruct 的性能相匹配。
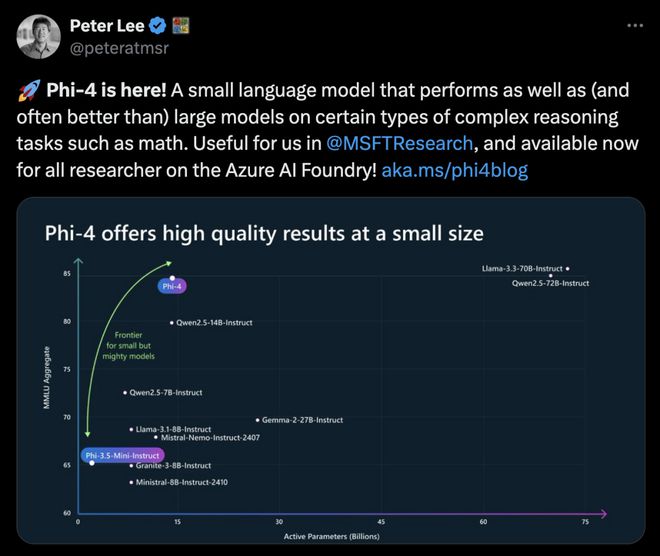
甚至,在2024年ACM数学竞赛题上,Phi-4的准确率达到了91.8%。
Phi系列前任负责人塞巴斯蒂安·布贝克(Sebastien Bubeck)看到这个结果时感到非常惊讶。
下面的例子展示了Phi-4的数学推理能力,不仅快速而且准确。

深入挖掘,Phi-4继承了前几代Phi系列的传统,也完成了教科书级“合成数据”的训练。
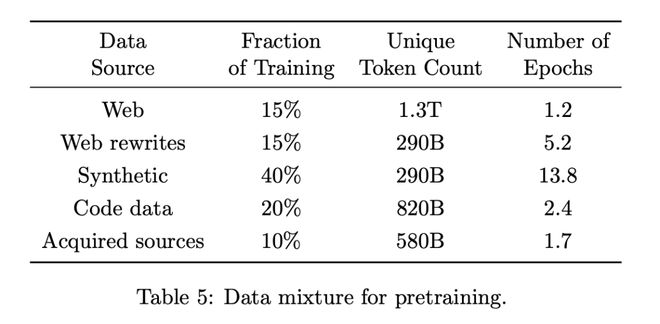
合成数据占比高达40%
除了合成数据外,它还实现了三项核心技术突破,包括精选的原生数据和领先的后训练技术,例如DPO中的Pivotal Tokens Search。
Phi-4的成功颠覆了Ilya、Alexander Wang等大佬所宣称的“数据墙”观点。

目前,新模型已在 Microsoft Azure AI Foundry 上提供,并将于下周在 HuggingFace 上提供。
数学战胜GPT-4o,36页技术报告发布
与大多数语言模型不同,Phi-4 是在自然发生的数据源(例如网页内容或代码)上进行预训练的,Phi-4 在整个训练过程中策略性地整合了合成数据。
虽然之前Phi系列中的模型性能主要来源于蒸馏教师模型(尤其是GPT-4)的能力,但Phi-4在STEM领域的问答能力上显着超越了其教师模型,展示了数据生成和后期训练技术。它可以带来比模型蒸馏更多的能力。

论文地址:
Phi-4主要由三大核心技术组成:
- 训练前和训练中的综合数据
- 高质量有机数据的筛选和过滤
- 培训后
得益于这些创新,Phi-4 在推理相关任务上的性能与更大的模型相当,甚至超越。
例如,其性能在许多广泛使用的推理相关基准测试中达到或超过 Llama-3.1-405B。
从表1可以看出,Phi-4在GPQA(研究生水平STEM问答)和MATH(数学竞赛)基准测试中都显着超过了其教师模型GPT-4o。
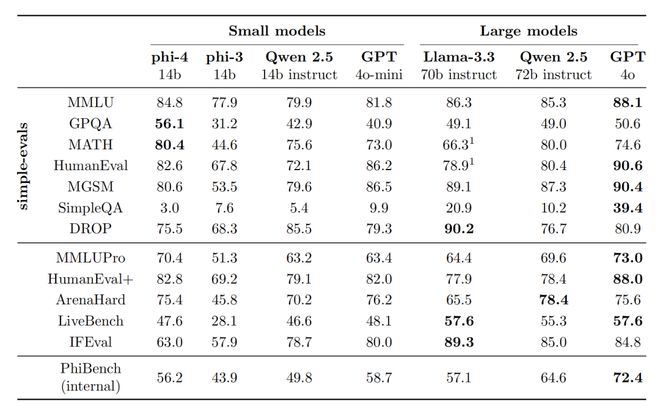
表1 Phi-4在经典基准测试上的表现
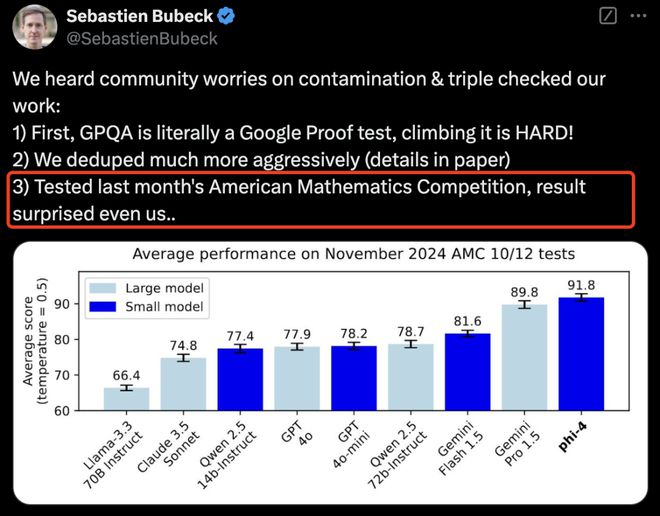
为了验证 Phi-4 是否存在过拟合和数据污染问题,研究人员在 2024 年 11 月的 AMC-10 和 AMC-12 数学竞赛上对该模型进行了测试。
这两项比赛的数据在训练时并未收集,因此它们的比赛表现可以有效地作为测试模型泛化性能的指标。
从下图可以看出,Phi-4虽然只有14B,但其平均分甚至大幅超过其老师模型GPT-4o。
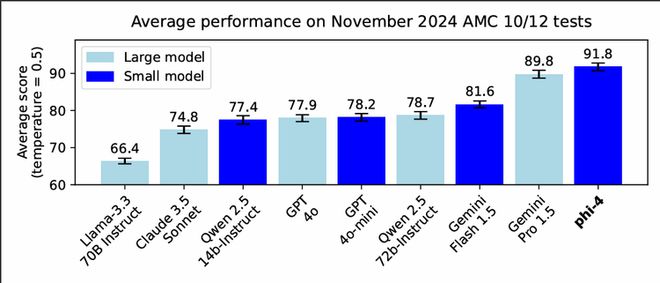
在数学竞赛问题上,Phi-4 的表现优于许多较大的模型,包括 Gemini Pro 1.5
合成数据的优点
合成数据构成了 Phi-4 训练数据的大部分,并通过多种技术生成,包括多代理提示、自我修订工作流程和指令反转。 。
这些技术方法可以构建数据集,使模型具有更强的推理和解决问题的能力,解决传统无监督数据集的一些弱点。
合成数据并不是有机数据的廉价替代品,但与有机数据相比有几个直接的优势。
数据结构化和支持增量学习
在有机数据集中,标记之间的关系通常是复杂且间接的。可能需要许多推理步骤来将当前标记连接到下一个标记,这使得模型很难从预测下一个标记的目标任务中有效地学习。
相比之下,由于语言模型生成的每个标记都是根据前一个标记进行预测的,因此这种结构化标记也可以使模型训练更加高效。
使训练与推理上下文保持一致
合成数据可以防止模型从有机数据集中学习一些不适合后续训练的数据特征。
例如,网络论坛往往有自己特定的沟通方式、使用习惯等,而人们在与大模型交谈时,语言风格和交互逻辑完全不同。
这时候,如果直接使用在线论坛的数据进行训练,假设某些内容具有独特的风格,模型就会认为这个内容出现在对话中的概率会很低。因此,当模型在后续对话中进行推理时,无法准确地将对话内容与对应的论坛内容进行匹配。
合成数据会将在线论坛中的内容重写为与LLM交互时的语言风格,从而更容易在LLM聊天推理的上下文中进行匹配。
合成数据在 Phi-4 的后期训练中也发挥着关键作用,其中采用拒绝采样和直接偏好优化 (DPO) 等新方法来优化模型的输出。
合成数据的来源
预训练和训练数据
为此,研究团队创建了 50 个广泛的合成数据集类型,每个类型依赖于不同的种子和不同的多阶段提示程序,涵盖各种主题、技能和交互属性,累计约 4000 亿个未加权代币。
他们通过以下方法确保合成数据不被一些低质量的网络数据污染,从而成为高质量的训练数据集。
种子数据集的构建
1. 网页和代码种子:从网页、书籍、代码库中提取摘录和代码片段,重点关注复杂度高、推理深度和教育价值的内容。为了确保质量,该团队采用了两阶段筛选流程:首先,确定需要关注的关键高价值页面,其次,将所选页面分成段落,并对每个段落的客观和合理内容进行评分。
2.问题数据集:从网站、论坛、问答平台收集大量问题。然后使用投票技术筛选问题以平衡难度。具体来说,团队为每个问题生成多个独立答案,并应用多数投票来评估答案的一致性。然后丢弃所有答案一致(表明问题太简单)或答案完全不一致(表明问题太难或太模糊)的问题。
3. 从多个来源创建问答对:使用语言模型从书籍、科学论文和代码等有机来源中提取问答对。这种方法不仅仅依赖于识别文本中明确的问答对。相反,它涉及一个旨在检测文本中的推理链或逻辑进程的管道。语言模型识别推理或解决问题过程中的关键步骤,并将其重新表述为问题和相应的答案。实验表明,如果做得正确,对生成内容的培训可能比对原始内容的培训更有效(在学术和内部基准的改进方面)。
重写和增强:种子通过多步骤提示工作流程转换为合成数据。这涉及将给定段落中的大部分有用内容重写为练习、讨论或结构化推理任务。
自我修正:通过反馈循环迭代地完善初始响应,其中模型根据侧重于推理和事实准确性的标准来判断自身,并随后改进其输出。
代码和其他任务的指令反转:为了提高模型从指令生成输出的能力,团队采用了指令反转技术。例如,他们从代码数据集中获取现有代码片段,并使用它们生成包含问题描述或任务提示的相应指令。仅保留原始代码与从生成的指令重新生成的代码之间相似度较高的指令,以确保指令与输出匹配。
训练后数据
在后训练阶段,数据集主要由两部分组成:
- 监督微调 (SFT) 数据集:使用从公共和合成数据中仔细过滤的用户提示来生成多个模型响应,并使用基于 LLM 的评估流程选择最佳响应。
- 直接偏好优化(DPO):基于拒绝采样和LLM评估生成DPO对,部分基于创建关键字标记对的方法。
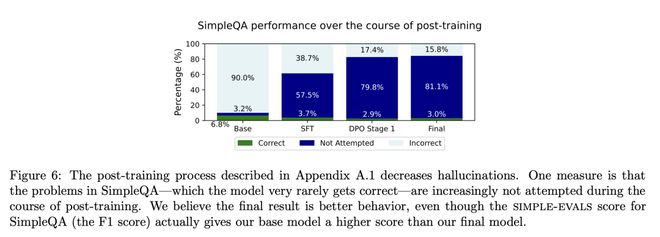
研究人员利用生成的 SFT 数据和 DPO 数据对来缓解模型的虚幻问题。
如下图6所示,该方法大大减少了SimpleQA中的幻觉现象。
预训练
Phi-4 也是基于 Transformer 架构构建的,有 14B 个参数,默认上下文长度为 4096。在训练中间,扩展到 16K 上下文。
由于预训练模型不擅长遵循指令,因此使用要求答案采用特定格式(例如简单评估)的零样本评估并不能提供太多信息。
因此,该团队使用内部实施的基准进行了预训练评估,该基准在各种任务上使用了对数似然和少量样本线索的混合。
具体来说,他们对 MMLU (5-shot)、MMLU-pro 和 ARCC (1-shot) 使用对数似然评估,而对 TriviaQA (TQA)、MBPP、MATH 和 GSM8k 分别使用 1、3、4 和 1。 8 个小样本示例可帮助模型遵循答案格式。
表2 预训练后在基准测试评估中phi-4相对于phi-3-medium的改进值
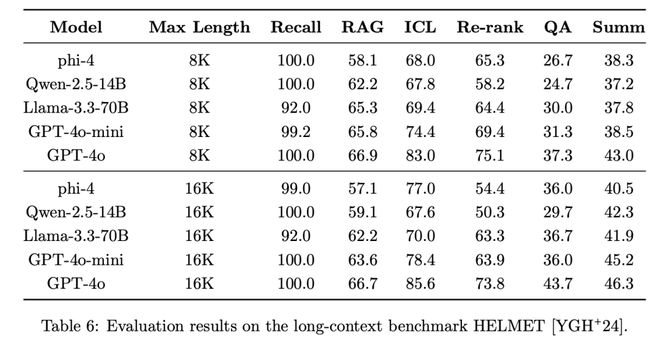
在长上下文基准HELMET测试中,Phi-4在召回率、最大上下文等指标上几乎取得了领先优势。
后期培训
如前所述,训练后阶段最重要的技术是关键令牌搜索(PTS),那么这到底是什么呢?
关键代币搜索
当模型逐个令牌生成对提示令牌的响应时,每个令牌对应于模型答案的前缀。
对于每个这样的前缀,可以考虑两个关键标记:一是模型在改变的前缀下正确回答的条件概率;二是模型在改变后的前缀下正确回答的条件概率。另一个是该token带来的概率增量,即生成该token前后准确率的差异。
事实上,当人工智能模型生成答案时,通常只有几个关键标记来决定整个答案是否正确。
研究过程中,团队观察到一个有趣的现象:模型在解决数学问题时,只生成负密钥标记,将可能失败的解决方案变成了成功。
然后,它生成(一个token),这可能会导致准确率急剧下降。

现在,结合DPO训练方法来思考这个方法,发现了几个值得注意的问题。
如上图3所示,实验中有很多token的概率远低于关键token“负”0.31。这些令牌会在训练中产生噪声,并稀释密钥令牌的有效信号。
更糟糕的是,像 (a) 这样导致问题解决不稳定的标记由于概率较低(0.12)而会收到强烈的正向学习信号。
此外,直觉表明,当两个文本的内容存在重大偏差时,比较它们各自的下一个标记概率(DPO 所做的)可能会失去意义。
简而言之,当文本开始偏离时,更有意义的信号应该来自第一个标记。
为了缓解之前的问题,微软团队提出了一种创新的方法——密钥令牌搜索(PTS)。
该方法专门生成单个关键令牌的偏好数据,然后使用DPO优化来准确地作用于特定令牌。
PTS的核心任务是在完整的令牌序列(T_full = t1,t2,...)中找到那些关键令牌。
具体来说,需要找到对成功率有显着影响的token位置,即p(success | t1, ..., ti)。
PTS 将发现的关键 token 转换为训练数据,首先使用 Q + t1, ..., ti-1 作为查询基准,然后选择可以提高/降低成功率的个体 token 作为“接受”和“拒绝”分别。样本。
虽然PTS使用的二分搜索算法不能保证找到所有关键令牌,但它有两个重要的特征。
- 你找到的一定是钥匙令牌
- 如果在问题解决过程中成功概率几乎单调变化,则可以找到所有关键令牌
下面的图 5 显示了使用 PTS 生成的偏好数据的示例。

在数学问答的例子中,研究发现了一个有趣的现象。关键令牌往往不是一个明显的错误,而是一个引导模型走向不同问题解决路径的选择点。
例如方法A——分别乘以分母;方法B - 直接叉乘。
虽然这两种方法在数学上都是正确的,但后者通常对模型更稳健。
PTS 生成的训练数据可以帮助 Phi-4 在这些关键决策点做出更好的选择。
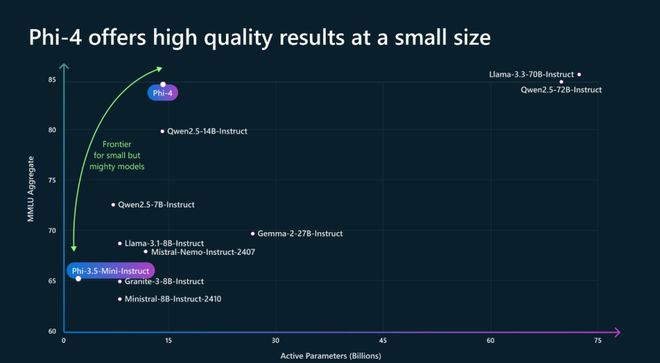
凭借小知识和大技能,Phi-4 获胜。
基于以上技术的创新,Phi-4在各种基准测试中都能展现出惊人的表现。
在上表1中,与同级别的Qwen-2.5-14B-Instruct模型相比,在12项基准测试中,Phi-4在9项测试中取得了优势。
此外,研究人员认为 Phi-4 在 SimpleQA 上实际上比 Qwen 表现更好。
事实上,他们的基础模型在 SimpleQA 上取得了比 Qwen-2.5-14B-Instruct 更高的基准分数,但团队在训练后有意修改模型的行为以优化用户体验,而不是追求更高的结果。基准分数。
此外,Phi-4 在 STEM 问答任务上表现出了出色的表现。
例如,它甚至在 GPQA(研究生水平 STEM 问题)和 MATH(数学竞赛)上超越了其教师模型 GPT-4。
在 Humaneval 和 Humaneval+ 衡量的编码能力方面,它的得分也高于任何其他开源模型,包括更大的 Llama 模型。
Phi-4 表现较差的领域分别是 SimpleQA、DROP 和 IFeval。
对于前两个,研究人员认为 simple-eval 报告的数字过于简单化,不能准确反映模型在基准问题上的表现。
然而,IFeval 揭示了 Phi-4 的一个真正弱点——它难以严格遵循指令。
在下一步的研究中,研究人员认为,通过有针对性的合成数据,可以显着提高Phi系列模型的指令跟随性能。
接下来,我真的很期待接下来的Phi系列小型号的发布。
参考:
