尽管o3在圣诞节最后一天,即12日刷新了ARC-AGI测试,但AGI的未来仍然渺茫。而就在近日,外媒曝出GPT-5并没有达到预期,因训练数据问题而屡屡受挫。对手已经迎头赶上,OpenAI的未来并不乐观。
OpenAI大张旗鼓地推出了为期12天的圣诞特别活动,而期间发布最轰动成果的居然是谷歌。
谷歌的密集核弹让OpenAI的12天挤牙膏黯然失色,让其毫无还手之力。
原生多模态 Gemini 2.0 Flash、令人惊叹的 Project Astra demo、成团亮相的 AI 代理、击败 Sora 并掀起全网热潮的 Veo 2……看来 OpenAI 的圣诞节事件就是一个笑话。
最后一天,OpenAI终于蓄势待发,发布了重磅消息。
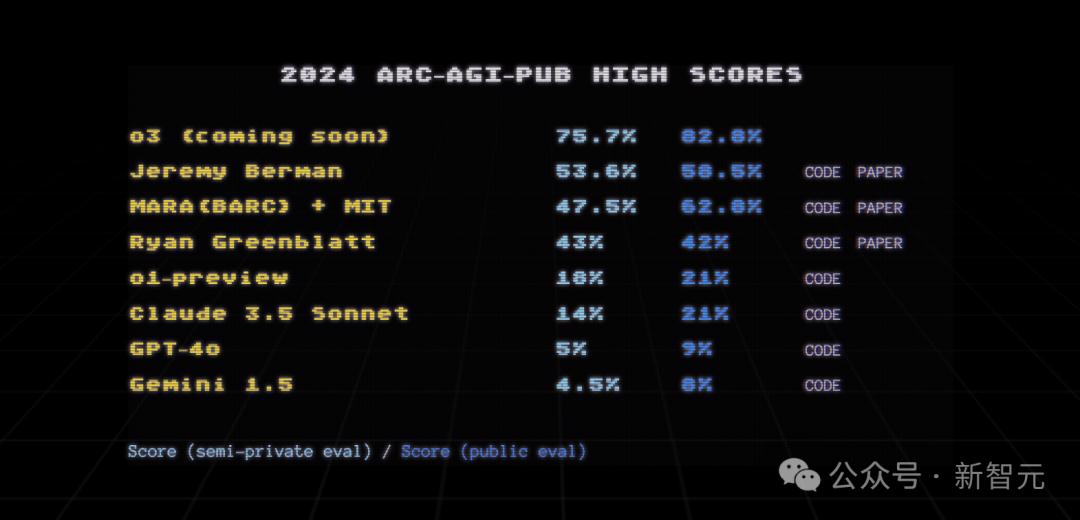
Altman亲自亮相,并在直播中揭晓了OpenAI的下一代推理模型o3。最令人印象深刻的是,它在难度极高的ARC-AGI基准测试中遥遥领先。
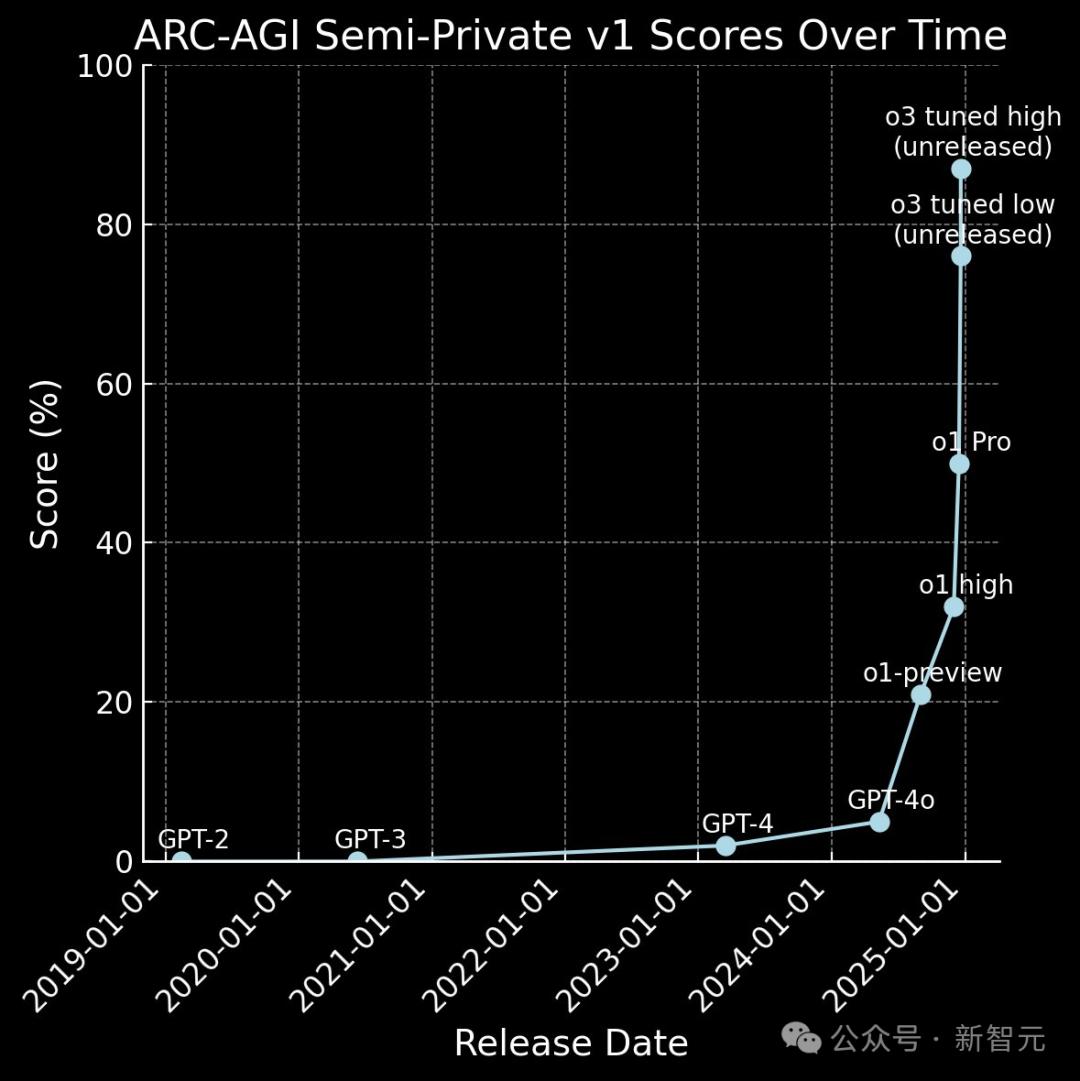
OpenAI模型历年在ARC-AGI评分中的表现
“从o1到o3需要3个月,从o1 Pro到o3只需要1个月。”
这样的对比,算是给前段时间非常流行的“缩放定律碰壁”理论打了一记耳光。 OpenAI终于自豪并自豪了。

目前,o3只对安全研究人员开放,而大家最关心的是:我们的GPT-5在哪里?
无独有偶,直播刚结束几个小时,OpenAI就被外媒直接踢出,并曝出负面消息:GPT-5持续出现问题,且看不到尽头!
《华尔街日报》发文揭露OpenAI新一代AI模型GPT-5的内部开发项目“Orion”问题重重。
文章标题明确指出“项目延期”、“成本高昂”,直接让奥特曼着急了!
他暗暗讽刺道:o3发布不久,他们就说AI的下一次大飞跃进展缓慢。这合理吗?

尽管o3的表现令人眼花缭乱,但GPT-5何时发布仍是未知数。
要知道,距离2023年3月GPT-4发布已经过去了18个多月,市场和投资者的耐心都快被磨灭了。
领先机构Menlo Ventures的数据显示,OpenAI今年在企业AI领域的市场份额从50%暴跌至34%,但其老对手Anthropic的市场份额却翻了一番,从12%升至24%。
今天甚至有消息称:由于OpenAI模型性价比太高,微软正计划将非OpenAI模型集成到365 Copilot中。
谷歌和 Anthropic 的压力更大,而微软则在背后捅刀子。 OpenAI的处境显然已经不再是曾经的“赢家通吃”的局面了。
OpenAI 在 GPT-5 训练方面一直存在问题
据《华尔街日报》报道,微软原本计划在年中看到 GPT-5,但 Altman 在 11 月表示无论如何今年都不会发布。
当然,这并不是说OpenAI什么都不做。
据知情人士透露,OpenAI已经进行了至少两次大规模培训,每次都需要几个月的时间来处理和分析海量数据。
但每次训练都会出现新的问题,模型的性能无法达到研究人员的预期——性能的提升不足以证明维护新模型的高运营成本是合理的。
不仅如此,为期六个月的培训课程的成本也非常高——仅计算部分就约5亿美元。
大语言模型培训日
OpenAI的ChatGPT模型参数规模巨大,在测试过程中,可以向模型输入数万亿代币。
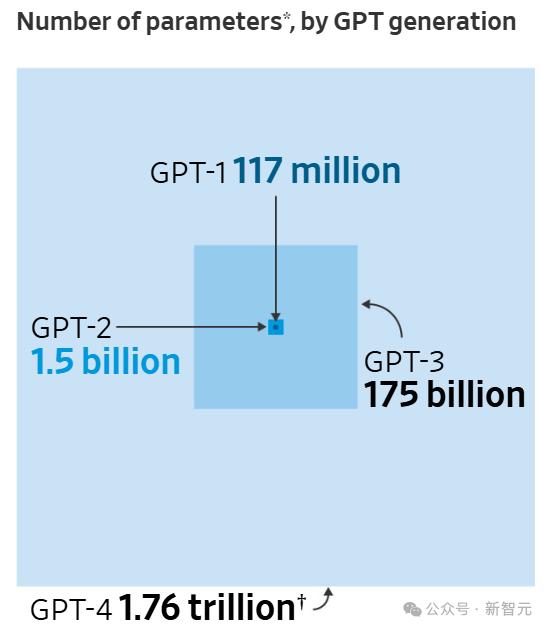
ChatGPT系列不同参数尺度对比
一次大规模的训练可能需要在数据中心花费数月的时间,并使用数万个顶级计算芯片。
每一次训练,研究人员都需要在电脑前连续工作数周甚至数月,试图将世界上大部分知识输入到AI系统中。
Altman 曾表示,训练 GPT-4 的成本超过 1 亿美元。未来训练AI模型的成本预计将超过10亿美元。
训练失败是痛苦且代价高昂的,就像火箭在太空发射任务中爆炸一样。
为此,研究人员试图通过在正式训练之前进行小规模实验——试运行来降低这种失败的风险。
但没想到的是,GPT-5在预测试中暴露了很多问题。
2023 年中,OpenAI 启动了代号 Arrakis 的项目,作为 Orion 新设计的预测试。
然而,这个过程进展非常缓慢——这意味着更大规模的训练将需要极长的时间,成本将是天文数字。
项目结果表明,开发GPT-5的道路将远比预想的更加曲折。
OpenAI 研究人员决定优化 Orion 的技术,着手解决训练数据多样性和高质量不足的问题。

从头开始构建数据
为了让Orion变得更聪明,OpenAI需要扩大模型的规模,这需要更多的训练数据。
但众所周知,目前可用的质量数据十分有限。
OpenAI 针对这个问题的解决方案是从头开始创建数据集。
他们正在组建一个团队,为 Orion 提供学习材料,比如聘请软件工程师编写新的软件代码,聘请数学家设计数学问题。这些专家还将向系统详细讲解他们的解决问题思路和工作流程。
许多研究人员认为,编程代码作为一种严格的计算机语言,可以帮助法学硕士学会处理他们以前从未遇到过的问题。

要求人们解释他们的思维过程可以加深新创建数据的价值。
这不仅为LLM提供了更多可学习的语言数据,也为模型今后解决类似问题提供了系统的解决方案。
图灵是一家与 OpenAI 和 meta 等科技巨头合作的 AI 基础设施公司,将要求软件工程师编写程序来高效解决复杂的逻辑问题,或者要求数学家计算由 100 万个篮球组成的金字塔的最大高度。 。
然后,这些答案,以及更重要的解题思路和步骤,都会被融入到AI训练数据中。
此外,OpenAI 还与理论物理等领域的专家合作,要求他们详细介绍如何解决该领域最具挑战性的问题。这些专业知识也将有助于提高猎户座的智力水平。
这个过程也很慢...
据估计,GPT-4 的训练大约使用 1.3×10^3 个令牌。即使我们组织一个1000人的团队,每个人每天写5000字,产生10亿代币也需要几个月的时间。
同时,OpenAI还利用“合成数据”来辅助训练Orion。然而,研究表明,人工智能创建数据然后用它来训练人工智能的这种反馈循环经常会导致系统故障或产生毫无意义的答案。
据知情人士透露,OpenAI 科学家认为,使用另一个 AI 模型 o1 生成的数据可以避免这些问题。
人才流失
训练大型模型具有挑战性。随着公司内部风波不断,竞争对手不断以数百万美元年薪挖走其顶尖研究人员,OpenAI 的大模型训练变得更加复杂。
去年,Altman 突然被 OpenAI 董事会解雇,这一事件让许多研究人员对公司的未来感到好奇。然而,Altman 很快被重新任命为首席执行官,并立即开始改革 OpenAI 的治理结构。
仅今年一年,就有超过两打核心高管、研究人员和高级员工离开了 OpenAI,其中包括联合创始人兼首席科学家 Ilya Sutskever 和首席技术官 Mira Murati。
在最近的一次人事变动中,著名研究员亚历克·雷德福也宣布辞职。他在公司服务近八年,是多篇重要科研论文的主要作者。
重启猎户座项目
到 2024 年初,OpenAI 高管开始感受到越来越大的压力。
GPT-4 推出已经一年了,竞争对手正在迅速追赶。
Anthropic推出的新一代大型模型受到了业界的广泛好评,不少专家认为其性能已经超越了GPT-4。
2024年第二季度,谷歌推出智能笔记应用NotebookLM。这款AI辅助写作工具迅速成为当年最流行的人工智能应用。

面对Orion项目的研发瓶颈,OpenAI开始将资源分配给其他项目和应用程序的开发。新项目包括开发轻量级版本的GPT-4,以及名为Sora的AI视频生成产品。
据知情人士透露,负责新产品开发的团队与Orion研究人员之间为了争夺有限的计算资源而产生了冲突。
人工智能实验室之间的竞争远远超出了科学界的常态,各大科技公司发表的最新研究成果和技术突破性论文数量大幅减少。
自2022年大量资金涌入市场以来,科技公司开始将这些研究成果视为核心商业机密。一些研究人员对于保守他们的工作秘密非常谨慎,以至于他们拒绝在飞机上、咖啡店或任何其他人可能窥视他们工作的地方工作。
这种过度保密引起了许多资深人工智能研究人员的不满,其中包括 meta 首席人工智能科学家 Yann LeCun。他直言,OpenAI和Anthropic的工作本质上已经不能被视为研究,而应该被视为“先进产品开发”。
在一次 OpenAI 几乎缺席的 AI 会议上,LeCun 表示:“如果是在商业开发周期的压力下完成的,那就不能称为研究;如果完全保密,就不能称为研究。用于研究。”

再次踏上陷阱
2024年初,OpenAI准备借助改进的数据再次启动Orion项目。研究团队一季度进行了多次小规模模型训练,积累经验、树立信心。
到了5月,OpenAI研究人员认为时机成熟,决定再次尝试Orion的大规模模型训练,整个过程预计将持续到11月。
然而,训练开始后,研究人员发现了数据集的一个问题:数据的多样性远低于预期,这可能会严重限制Orion的学习能力。
这个问题在小规模测试中并没有出现,直到开展大规模训练。考虑到已经投入的时间和财务成本,OpenAI 已经不能再从头开始了。
为此,研究团队不得不在训练过程中迫切寻找更加多样化的数据输入模型。这种补救策略的有效性仍然未知。
数据即将耗尽
Orion项目遇到的这些问题向OpenAI内部发出了一个信号:过去推动公司成功的“规模优先”战略可能即将结束。
担心发展瓶颈的不仅仅是OpenAI。整个人工智能行业都在激烈讨论一个问题:人工智能的技术进步是否已经开始进入平台期。
OpenAI前首席科学家Ilya Sutskever近日在NeurIPS 2024上明确表示,依靠海量数据推动AI发展的时代已经结束。
“由于我们只有一个互联网,数据增长已经结束。数据就像AI领域的化石能源,即将耗尽。”
而这种宝贵的“数字燃料”正变得日益枯竭。

新策略:增加推理时间
在 Orion 项目的开发过程中,OpenAI 研究人员发现了一种提高大语言模型智能的新方法:加强推理能力。
研究人员表示,通过延长模型在推理过程中的“思考”时间,可以解决一些尚未训练过的难题。
从技术实现角度来看,OpenAI o1采用了多答案生成机制,针对每个问题生成多个候选答案,并通过分析选择最优解。
这使得模型能够处理更复杂的任务,例如制定商业计划或设计填字游戏,同时提供推理过程的详细解释——一种允许模型从每个答案中不断学习和优化的机制。
然而,苹果研究人员在论文中对此提出质疑,认为包括 o1 在内的推理模型很可能只是重现训练数据中的模式,而不是真正具备解决新问题的能力。

论文链接:
研究人员发现,当向问题中添加不相关的信息时,模型性能会显着下降,例如,在有关猕猴桃的数学问题中简单地添加水果大小差异的描述会导致模型性能显着下降。
在最近的 TED 演讲中,OpenAI 的高级研究科学家 Noam Brown 强调了推理能力的重要性。
诺姆·布朗说:“我们的研究发现,要求人工智能在扑克游戏中推理大约 20 秒,可以实现相当于将模型大小增加 10 万倍、将训练时间延长 10 万倍的性能提升。”

更先进、更高效的推理模型可能成为Orion项目的核心基础。
OpenAI的研究团队正在深入探索这个方向,并计划将其与传统的数据增强方法结合起来,部分训练数据将来自OpenAI的其他AI模型。
然后,他们将使用人工生成的内容来进一步优化模型性能。
o3杀死了基准测试,但距离AGI还有多远?
随着o3的“发布”,该机型在多项基准测试中也较o1 pro取得了显着的提升,而时间也仅仅只有一个月。
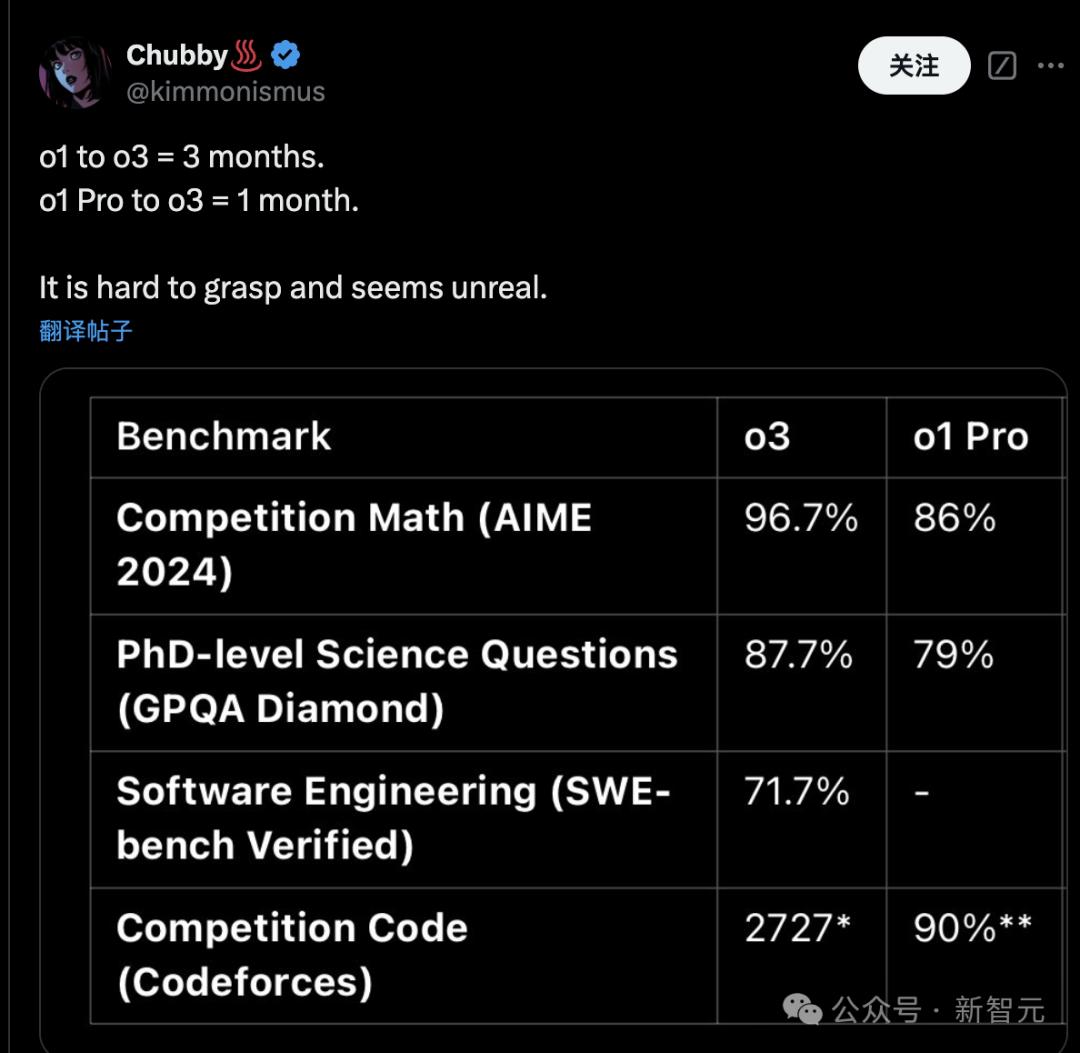
而且,在被誉为通用人工智能“唯一官方进度基准”的ARC-AGI测试中,o3以20%+的优势远超第二名。
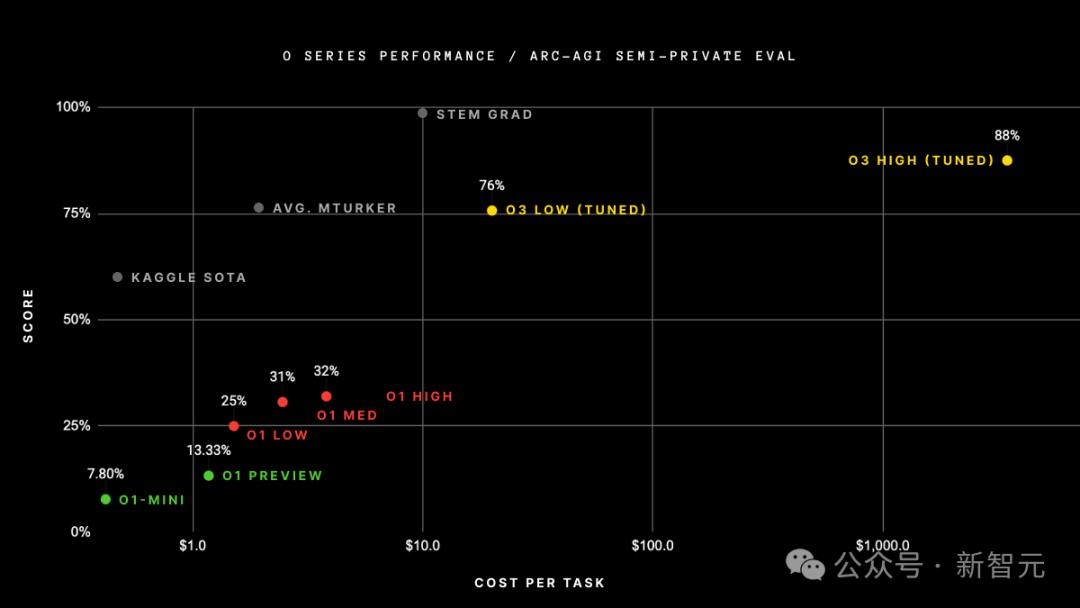
具体来说,o3在半私密评估集上取得了突破性的75.7%的高分,在高计算模式(172次计算)上取得了87.5%的成绩。
相比之下,ARC-AGI 的准确率在过去四年中只提高了 5%——从 2020 年 GPT-3 的 0% 到 2024 年 GPT-4o 的 5%。
o3颠覆了人们对AI能力的所有直观感受。
毕竟无论GPT-4投入多少计算,都无法得到这样的结果。
但问题在于,提高准确性的成本巨大:人类每项任务只需支付约 5 美元,完成 ARC-AGI 基准测试时仅消耗几美分的能源;而o3在低计算模式下,每个任务的成本为17-20美元。
虽然87.5%的较高分数排名非常划算,但可以证明,随着计算量的增加,模型的性能确实有所提高。
还没有AGI
在ARC-AGI“公共评估”(Public eval)中,即使o3增加计算量,仍有约9%的任务无法解决。但这对人类来说非常简单。
擦擦眼睛,看看你能不能打败目前最强的o3模型。
尝试之前请注意:下面的例子中,箭头之前的图片(上图)代表输入,箭头之后的图片(下图)代表输出,灰色部分代表数据集中的例子,绿色部分为o3。两次错误的尝试,最后一部分就是答案。
在第一个例子中,o3首先给出了一个可笑的错误答案,然后在第二个输出中生成了大面积的黑色像素......
这似乎是迄今为止最糟糕的结果,而且很难解释原因。
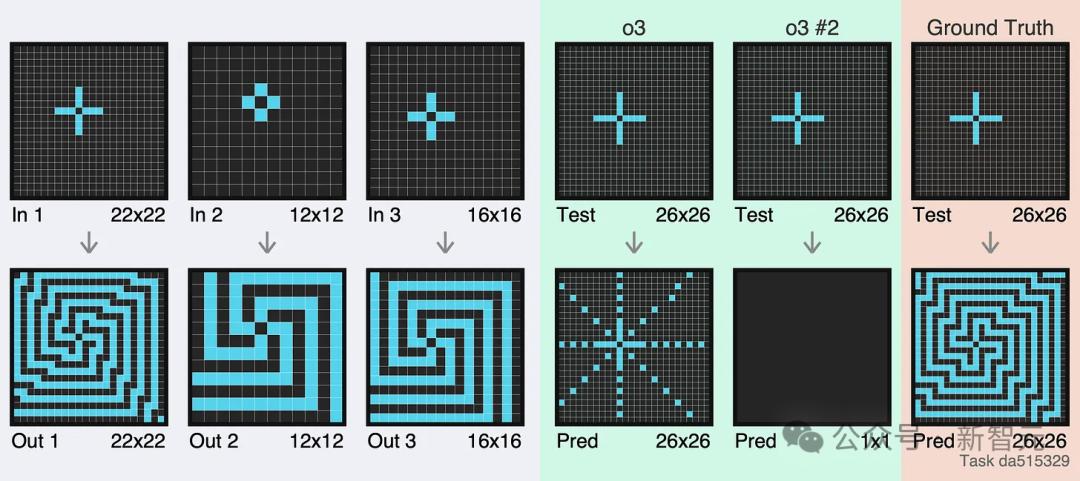
第二个例子有点考验眼力。尽管每一行都是正确的,但网格并未对齐。
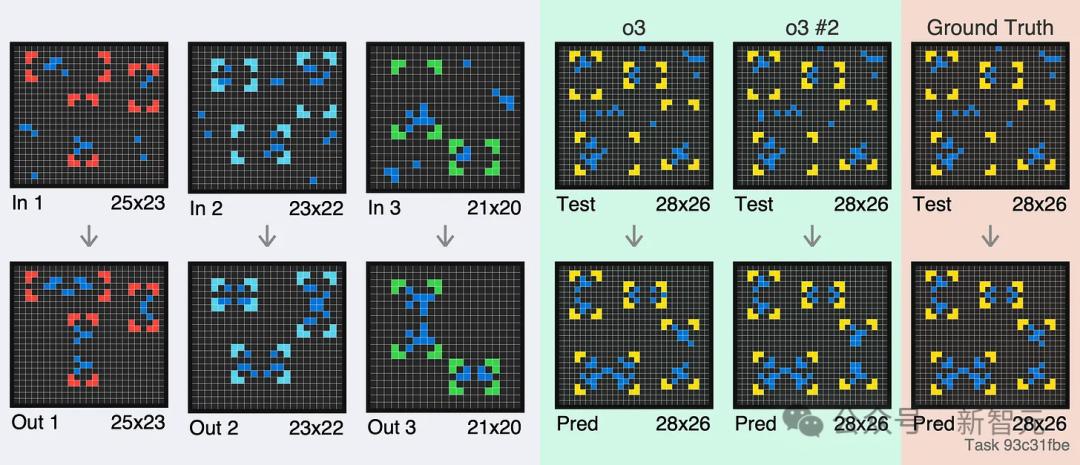
第三个例子,o3 没有将蓝色图块拉到左侧边栏。
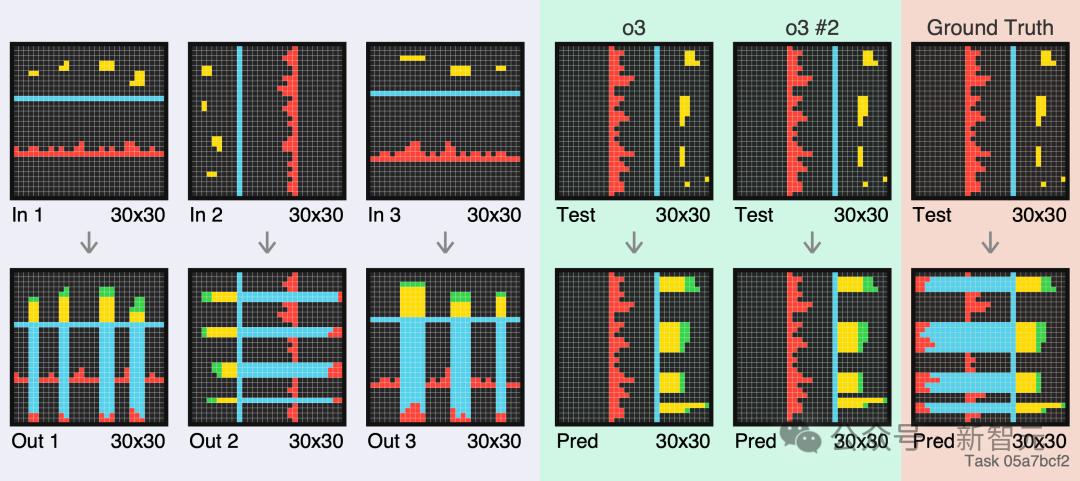
最后一个例子,在两次尝试中,o3 错过了预测中的几行。似乎很难记住有多少相同的重复行要输出。
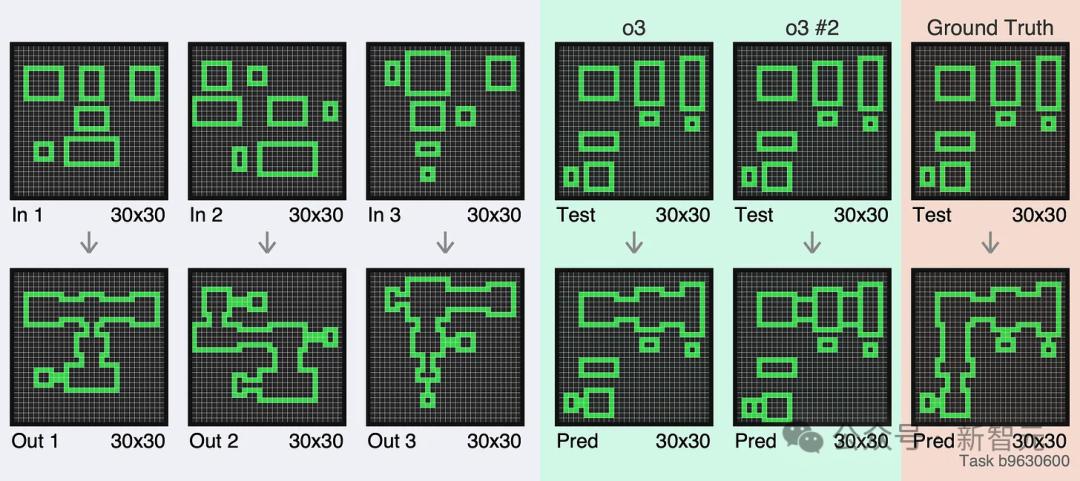
GPT-5会带来“重大飞跃”吗?
10 月份,投资者给 OpenAI 的估值为 1570 亿美元,很大程度上基于 Altman 的预测,即 GPT-5 将在多个学科和任务上实现“重大飞跃”。
目前还没有固定的标准来判断一个模型是否足够智能,可以被称为 GPT-5。
人们普遍认为,GPT-5 可以在完成日常任务(例如预约诊所或预订航班)的同时解锁新的科学发现。
研究人员希望它能少犯一些错误,或者至少在犯错误时承认它对答案有怀疑,减少所谓的“人工智能幻觉”。
一位 OpenAI 前高管表示,如果 GPT-4 表现得像聪明的高中生,那么未来的 GPT-5 在某些任务上将相当于博士水平。
今年早些时候,Altman 在斯坦福大学的一次演讲中告诉学生,OpenAI 可以“以高度的科学确定性”说 GPT-5 将比当前模型更智能。
公司高管决定模型是否达到GPT-5级别主要基于经验判断和技术评估,或者很多技术专家所说的“整体性能”。
不过,到目前为止,这个“整体表现”并不理想。
参考:
本文来自微信公众号“新智元”,作者:JHZ,36氪经授权发布。
