【新智元简介】研究人员对基于 Transformer 的 Re-ID 研究进行了全面回顾和深入分析,将现有工作分类为图像/视频 Re-ID、数据/注释限制 Re-ID 和跨模态 For Re-ID ID和特殊Re-ID场景,提出Transformer基线UntransReID,为动物Re-ID设计标准化基准测试,并为未来Re-ID研究提供新的手册。
对象重新识别(Re-ID)旨在跨不同时间和场景识别特定对象。
近年来,基于Transformer的Re-ID改变了长期以来由卷积神经网络(CNN)主导的领域,不断刷新性能记录并取得重大突破。
与以往基于CNN和有限目标类型的Re-ID综述不同,来自武汉大学、中山大学、印第安纳大学的研究人员全面回顾了近年来Transformer在Re-ID中日益增长的应用研究,并深入分析了Re-ID在Re-ID中的应用研究。变压器的优点。本文总结了 Transformer 在四个广泛研究的 Re-ID 方向上的应用,并将动物添加到 Re-ID 目标类型中,揭示了 Transformer 架构在动物 Re-ID 应用中的巨大潜力。

论文地址:
项目地址:
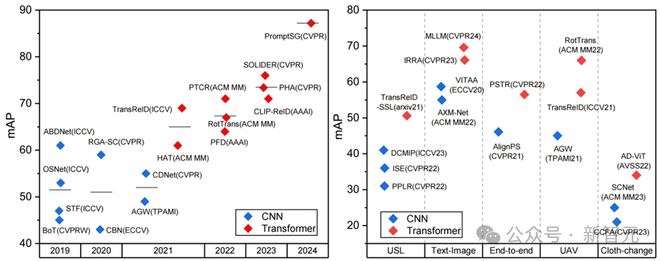
Transformer架构方法打破了CNN架构性能记录
研究背景
Transformer以优异的性能满足各种Re-ID任务的需求,提供强大、灵活、统一的解决方案。
研究人员将现有的工作分为基于图像/视频的Re-ID、数据/注释限制的Re-ID、跨模态的Re-ID和特殊的Re-ID场景,并详细阐述了Transformer处理这些领域中各种问题的能力。字段。面对挑战时,优势就会显现出来。
考虑到无监督 Re-ID 的流行趋势,研究人员提出了一种新的 Transformer 基线——UntransReID,它在单模态/跨模态任务中实现了最先进的性能。
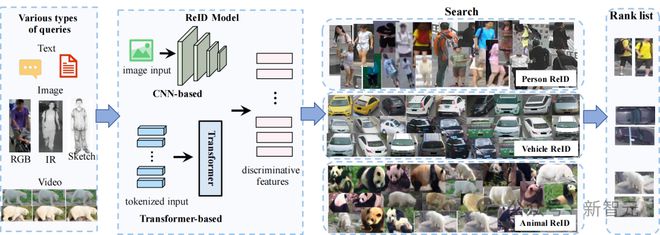
一般 Re-ID 流程
针对尚待探索的动物Re-ID领域,研究人员还设计了标准化基准并进行了广泛的实验,以探索Transformer在此任务中的适用性并推动未来的研究。
最后,讨论了大模型时代一些重要但尚未深入研究的开放问题。
Transformer在图像/视频重识别中的应用
Transformer 依赖于主干层的注意力机制,具有全局、局部和时空关系的通用建模能力,有助于在图像/视频 Re-ID 任务中轻松提取全局、细粒度和时空信息。
Transformer在图像Re-ID中的应用
1.架构优化:设计特殊的Transformer架构,如金字塔结构、层次聚合等,或者完善注意力机制。
2. Re-ID具体设计:利用视觉Transformer的注意力机制和图像块嵌入特性来捕获局部判别信息。某些关键信息的解耦是通过Transformer中的encoder-decoder结构来实现的。 Transformer架构是根据不同目标类型的结构先验和任务特征而设计的。

为图像 Re-ID 方法设计的不同 Transformer 架构
Transformer在视频Re-ID中的应用
1.应用Transformer进行后处理:许多应用Transformer的视频Re-ID方法都是混合架构。他们首先使用CNN模型提取特征,然后使用Transformer模型进行进一步处理。通过 Transformer 的 self-attention 机制捕获序列中的长期依赖关系和上下文信息。
2.纯Transformer架构:为了克服混合架构中CNN带来的长距离信息获取的限制,一些研究尝试探索纯Transformer架构在视频Re-ID中的应用。
数据/注释受限重识别
Transformer 为无监督学习提供了更多可能性。 Transformer 可以对数据或标签约束的 Re-ID 任务的更强大和更通用的模型进行广泛的自监督预训练。无监督Re-ID通常用于标记受限场景,而数据约束主要通过领域泛化Re-ID来解决。
Transformer在无监督Re-ID中的应用
1. 自监督预训练:Transformer 在无监督 Re-ID 中应用的一类研究侧重于自监督预训练。 Transformer模型对于大规模无标签数据具有高度的可扩展性,其结构灵活性提供了更加多样化的自监督范式。
2.无监督域适应:Transformer在无监督域适应(UDA)问题上受到的关注有限。对于行人重新识别,Wang 等人。使用 Transformer 实现不同身体部位之间的细粒度域对齐。对于车辆重新识别,一项工作使用联合训练策略,使 Transformer 自适应地关注车辆在每个域中的判别部分。
Transformer在跨模态Re-ID中的应用
Transformer 提供了一个统一的架构来有效处理不同模态的数据。多头注意力机制聚合了各种特征空间和全局上下文中的特征。高度适应性的编码器-解码器架构可容纳不同类型的输入和输出。因此,Transformer特别适合在跨模态Re-ID中建立跨模态关联,促进多模态信息的融合。
可见光-红外 Re-ID 旨在将白天的可见光图像与夜间的红外图像进行匹配。由于红外图像缺乏颜色和光照条件,视觉 Transformer 可以更好地捕捉模态不变特征,并且更加鲁棒。视觉 Transformer 的结构及其注意力机制可以轻松地在 patch 级别建立局部跨模态关联。现有的可见光-红外Re-ID方法侧重于学习模态共享特征,将特征分解为模态特定特征和共享模态特征,并在特征级别进行模态对齐。
文本图像重识别是一种跨模态检索任务,根据文本描述识别图像库中的目标。作为 Transformer 架构多模态应用的里程碑,对比语言-图像预训练(CLIP)等大规模多模态预训练模型在该领域取得了重大进展。最近,CLIP 已成为下游文本图像 Re-ID 任务的强大工具。
草图图像 Re-ID 和骨架 Re-ID 都是跨模态匹配任务。前者基于艺术家或业余爱好者绘制的草图,后者基于姿势估计生成的骨架图。 Transformer 擅长提取全局特征,在草图图像 Re-ID 方面表现出色。对于骨架Re-ID,可以使用Transformer来建模由骨架点组成的图结构的完整关系。
Transformer在特种Re-ID中的应用
在实际应用需求的驱动下,Re-ID领域出现了一系列特殊的应用场景。 Transformer 已初步应用于这些复杂的挑战,表现出出色的可扩展性和适应性。
Occlusion Re-ID:在遮挡Re-ID场景中,图片中的识别目标被部分遮挡,导致难以完整提取身份信息。近年来,基于Transformer的方法在该场景中取得了显着的效果,其核心策略包括提取局部区域特征。
换衣服Re-ID:在长期的Re-ID场景中,行人可能会以未知的方式换衣服,以服装外观为主的判别性特征表示将失效。李等人。评估了装扮Re-ID场景中的不同特征提取骨干网络。与 CNN 相比,Transformer 架构显示出显着的性能优势。
以人为中心的任务:通用的以人为中心的模型旨在将包括行人检测、姿态估计、属性识别和人体解析在内的多个与人类相关的任务集成到同一框架中,从而相互促进并提高Re-ID等任务的性能此类下游任务。
行人检索:行人检索是一种端到端的方法,通过多任务学习同时解决行人检测和Re-ID目标冲突的问题。将多尺度Transformer架构引入行人检索解决方案中,可以实现查询级别的实例级匹配。
Group Re-ID:Group Re-ID 利用群组中的上下文信息来匹配同一群组中的个体,面临群组成员变更、布局变更等挑战。传统方法在位置建模方面存在缺陷,而Transformer的位置嵌入机制可以更好地处理组级布局特性。
无人机Re-ID:与固定摄像机相比,无人机的高度和视角变化很快,导致图像更加复杂。在分析鸟瞰图像中的车辆和行人时,显着的边界框尺寸差异和物体方向不确定性是关键挑战。除了纯粹的无人机视角Re-ID之外,还有关注空中和地面视角跨域匹配的研究。
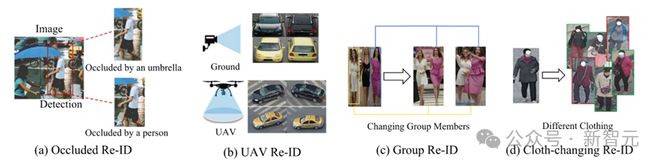
特殊Re-ID场景
新基线 UntransReID
研究人员提出了单模态/跨模态传统无监督Re-ID基线UntransReID。
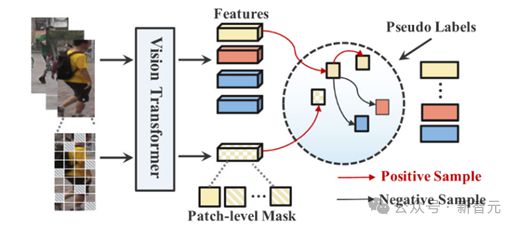
无监督 Re-ID 基线 UntransReID
单模态无监督Re-ID:研究人员在无监督训练过程中设计了补丁级掩模增强策略。在数据增强过程中,使用一系列可学习的标记来屏蔽部分图像块,并在训练过程中建立原始特征和屏蔽特征之间的对应关系,作为监督信号来指导模型学习。
跨模态无监督 Re-ID:对于可见光-红外跨模态行人 Re-ID,研究人员设计了一种双流 Transformer 结构,包括两个用于特定模态的 patch 嵌入层和一个模态共享 Transformer。为了进一步提高模态的泛化能力,在可见光通道中引入随机通道增强作为额外输入,实现联合训练。
实验结果分析:对于单模态无监督 Re-ID,UntransReID 实现了与当前最先进方法相当的性能。现有的先进跨模态 Re-ID 方法大多基于 CNN,需要复杂的跨模态相关性设计。 UntransReID 通过简单的设计在多个可见光-红外 Re-ID 数据集上实现了最先进的性能。
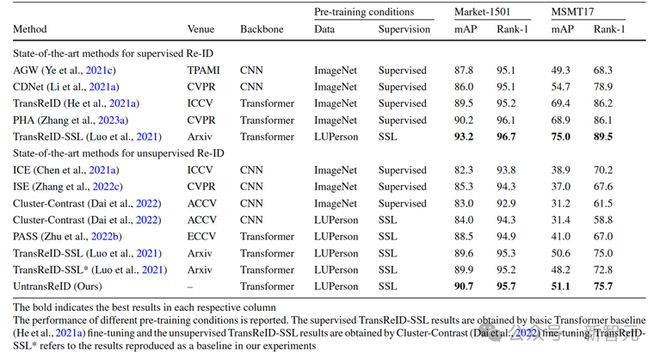
表1 基于CNN/Transformer的有监督/无监督方法的实验结果
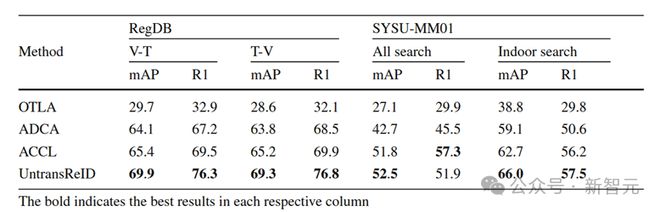
表2 RegDB和SYSU-MM01上可见光-红外跨模态基线的实验结果
动物重新识别
研究人员特别讨论了动物Re-ID领域的研究现状,总结了近年来基于深度学习的动物Re-ID数据集和动物Re-ID方法,制定了统一的动物Re-ID实验标准,并在此背景下评估了结果。了解使用Transformer的可行性,为以后的研究打下坚实的基础。

近年来动物Re-ID数据集
动物重新识别方法
基于全局图像的方法:许多现有研究借鉴行人重新识别的传统方法,将完整的动物图像输入深度神经网络以获得可靠的特征表示。
基于局部区域的方法:一些工作在数据收集和特征提取阶段关注动物的关键部位,例如牛头、象耳、鲸尾和海豚鳍。
基于辅助信息的方法:Zhang 等人。使用简化的牦牛头部左右方向作为辅助监督信号来加强特征表示;李等人。使用姿势关键点估计将老虎图像划分为多个身体部位进行局部特征学习。
动物重新识别的统一基准
研究人员使用各种先进的通用 Re-ID 方法进行了广泛的动物 Re-ID 实验。实验评估了基于CNN架构的BoT方法以及基于Transformer架构的TransReID和RotTrans方法。基于 Transformer 架构的方法在大多数情况下表现更好。该实验证明了Transformer在动物Re-ID应用中的可行性和巨大潜力。
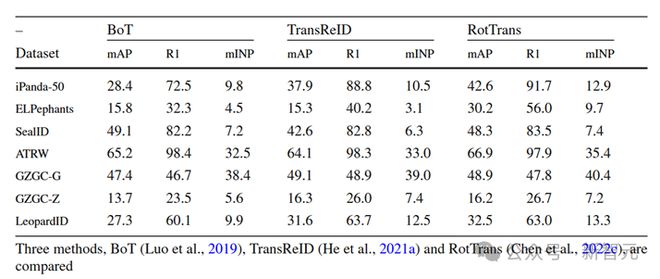
最先进的 Re-ID 方法在多个动物数据集上的评估结果
未来展望
Re-ID与大语言模型的结合
将大语言模型(LLM)与Re-ID任务深度结合正在成为热门的研究方向。通过生成或理解视觉数据的文本描述,LLM可以在细粒度语义提取、无标签数据利用、模型泛化能力提升等方面为Re-ID提供强有力的支持。
通用Re-ID大模型构建
满足多模态、多目标的实际应用场景是未来Re-ID的重要需求。 Transformer在多模态数据融合和大模型训练方面具有突出的能力。它可以用来同时处理视觉、文本甚至更多样化的信息,从而建立模态独立、任务统一的通用Re-ID模型。
变压器优化以实现高效部署
视频监控、智能安防等场景需要实时、轻量级部署。需要在保持Transformer健壮性的同时减少计算开销。将通用预训练模型的知识有效迁移到具体的Re-ID任务中,应对大规模动态更新中的灾难性遗忘问题,也是未来需要解决的问题。
参考:
