2024年底,探索通用人工智能(AGI)本质的公司DeepSeek AI开源了最新的混合专家(MoE)语言模型DeepSeek-V3-base。不过,目前尚未发布详细的模型卡。
具体来说,DeepSeek-V3-base采用685B参数MoE架构,包含256个专家,采用sigmoid路由,每次选择前8名专家(topk=8)。
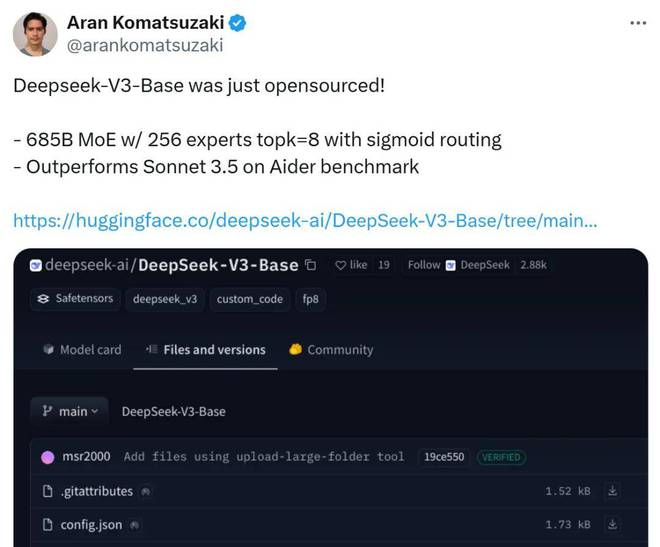
资料来源:X@arankomatsuzaki
该模型利用了大量专家,但对于任何给定的输入,只有少量专家处于活动状态,使得模型高度稀疏。
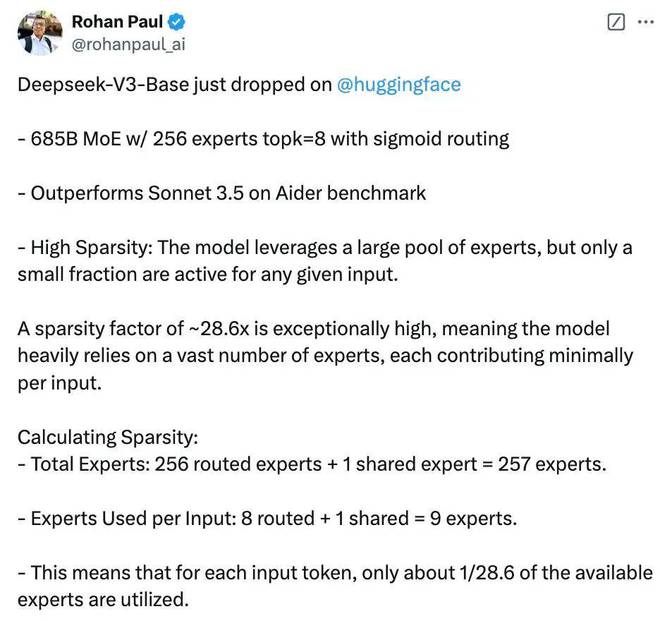
图片来源:X@Rohan Paul
从部分网友的反馈来看,API显示已经是DeepSeek-V3模型了。
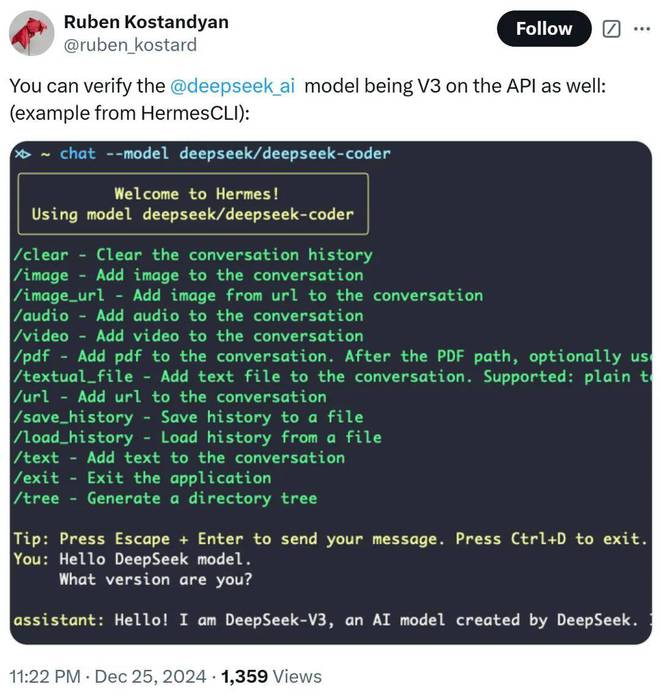
图片来源:X@ruben_kostard
同样,聊天界面也变成了DeepSeek-v3。
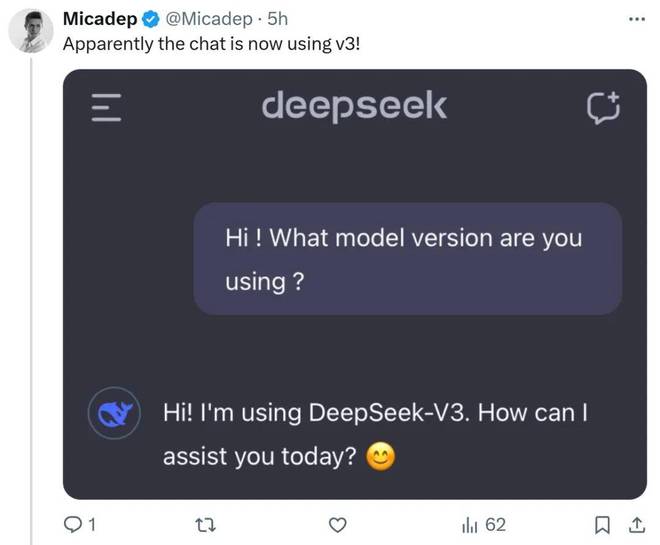
图片来源:X@Micadep
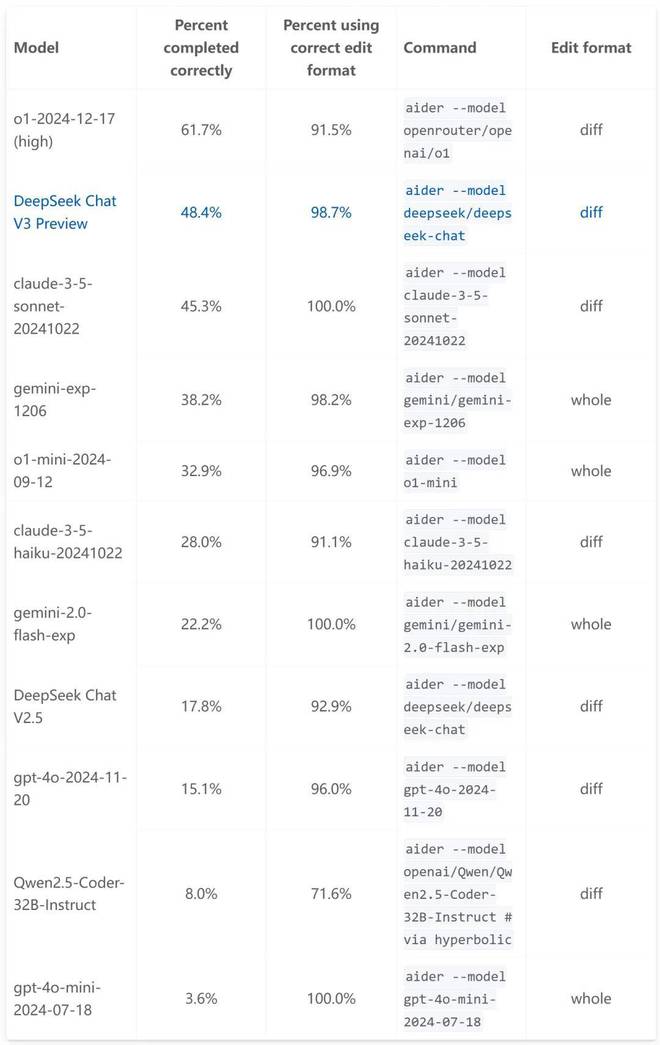
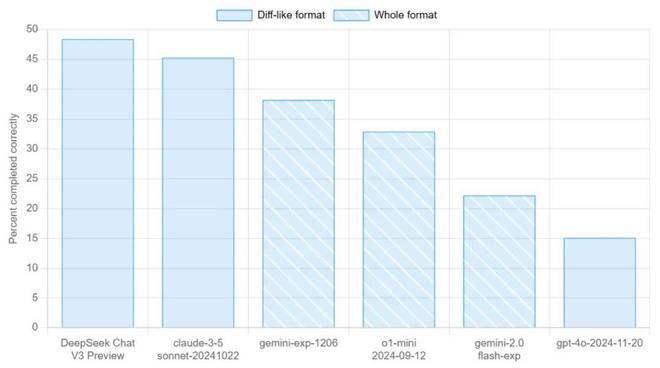
那么,DeepSeek-V3-base的性能如何呢? Aider多语言编程评估的结果给了我们答案。
我们先来看看Aider多语言基准测试。它需要大型语言模型(LLM)编辑源文件才能完成 Exercism 的 225 道编程题,涵盖 C++、Go、Java、Javascript、Python 和 Rust 等多种编程语言。这225道精心挑选的最难编程题给LLM的编程能力带来了巨大的挑战。
该基准衡量法学硕士使用流行编程语言进行编码的能力以及编写可集成到现有代码中的全新代码的能力。
从下表的模型对比结果来看,DeepSeek-V3-base仅次于OpenAI o1-2024-12-17(高),超过claude-3.5-sonnet-20241022、Gemini-Exp-1206、o1-mini一举。 -2024-09-12、gemini-2.0-flash-exp等竞品型号以及上一代DeepSeek Chat V2.5。
与V2.5(17.8%)相比,V3编程性能大幅提升至48.4%,提升了近31%。
此外,DeepSeek-V3的LiveBench基准测试结果也疑似泄露。我们可以看到,该模型的整体、推理、编程、数学、数据分析、语言和IF成绩都非常有竞争力,整体性能超过gemini-2.0-flash-exp和Claude 3.5 Sonnet等模型。
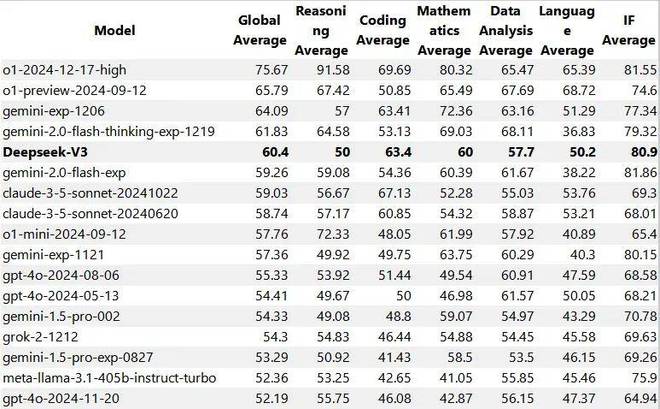
图片来源:reddit@homeworkkun
HuggingFace 负责 GPU Poor 的数据科学家 Vaibhav (VB) Srivastav 总结了 DeepSeek v3 和 v2 版本之间的差异:
从配置文件来看,v2和v3的主要区别包括:
v3 看起来像是 v2 的放大版本。
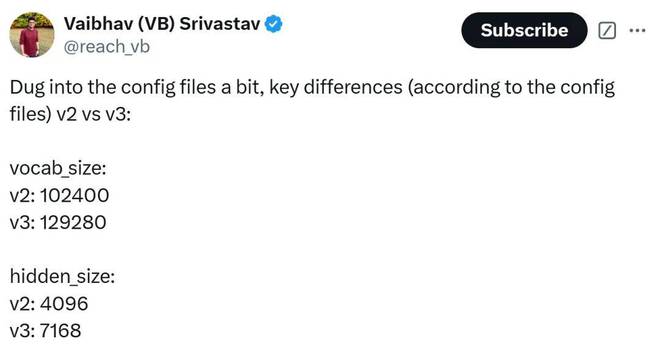
图片来源:X@reach_vb
值得注意的是,在模型评分函数方面,v3使用了sigmoid函数,而v2则使用了softmax函数。
网友热评:开源模式接近SOTA
不少网友表示,克劳德终于迎来了真正强大的对手,在一定程度上,DeepSeek-V3甚至可以取代克劳德3.5。

其他人感叹开源模式继续以惊人的速度追赶SOTA,而且没有放缓的迹象。 2025年将是人工智能最重要的一年。