文字|金雷梦辰
来源|量子比特(ID:QbitAI)
实在是有点不可思议。
这两天GPU圈发生了一件事情,被网友热议——一块显卡被卖光了。
它有多受欢迎?刚到货就被抢购一空。
GPU供不应求其实是家常便饭,但这次之所以被如此热议,还是因为这款产品背后的厂商。
不是您想象中的 NVIDIA 或 AMD,而是……英特尔。
为什么会这样呢?
从玩家们的讨论中不难得出答案——性价比足够高,2000元的价格就能玩2K画质的3A游戏。
The Verge 也给出了非常“直接”的评价:
英特尔终于在 GPU 上获胜。
这款显卡就是英特尔前不久发布的第二代Arc B580,售价仅为249美元。

你知道,Nvidia 售价 299 美元的 RTX 4060 和 AMD 售价 269 美元的 RX 7600 仅配备 8GB VRAM。
但Intel的Arc B580不仅比他们便宜,还配备了12GB VRAM和192bit显存宽度。
即使是更便宜的 Arc B570(219 美元,下个月上市)也配备了 10GB 的 VRAM。

除此之外,还有一件更有趣的事情。
Arc虽然是游戏显卡,但它毕竟是GPU,所以……就有人买了,开始做AI。而这或许会让其未来的销售更加火爆。
这不,有人在 Reddit 上分享了如何在 Arc B580 上使用 AI 绘图 Comfy UI:

不仅个人用户在尝试,我们还听说一些公司已经开始将英特尔显卡插入包括工作站和服务器在内的商业计算设备中。具体“菜谱”是:Intel Xeon系列CPU+Arc显卡。
不过暂时还是使用Intel上一代的A770。作为上一代的旗舰机型,A770拥有16G大显存,可以轻松用于AI推理。
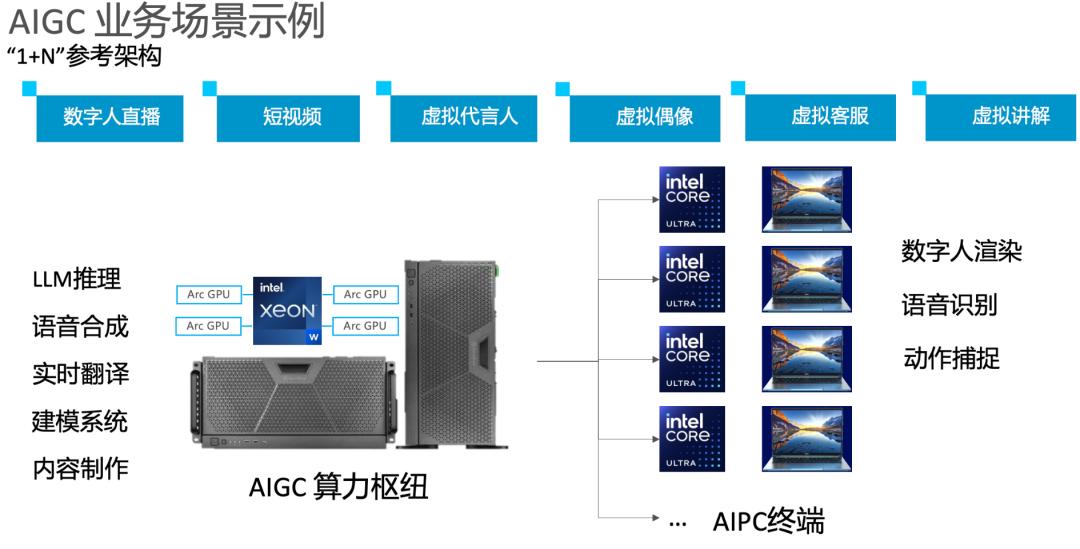
据可靠消息显示,这一组合最引人注目的优势还在于“性价比”二字。
而一个更值得讨论的话题应该是:

用消费级显卡搞AI有可能吗?
首先可以看出,无论是个人还是企业购买英特尔消费级显卡搞AI,基本上都是在做AI推理。
事实上,对推理算力的需求正在快速增长,并且很可能超过对训练算力的需求。
一方面,随着业界热议的“预训练缩放法则”碰壁,OpenAI o1/o3系列等模型开始依靠不断增加的推理算力来提升模型能力。
另一方面,AI应用的爆发也导致推理需求大幅增长。这些需求往往不需要溢出甚至极限的计算能力,即所谓的硬性要求并不高,而是更注重实现足够的性能(包括并发和时序)。扩展),以及它是否易于获取、易于部署、易于使用且价格足够实惠以与其同步。
那么为什么选择英特尔游戏显卡进行AI推理呢?正如前面分析的,成本效益绝对是一个主要考虑因素。
从硬件角度来看,即使是顶级的计算卡,面对单卡AI推理高并发等场景,显存也会成为瓶颈。然而,升级到四张或八张卡的成本将会飙升。此时,2000元价位的Intel A770这款拥有16G大显存的机型就成为了平衡性能与成本的选择。
从应用角度来看,很多场景其实对每秒的代币生成速度要求并不高,尤其是流式传输等优化方法。只要首个代币延迟到位,并且后续代币速度满足一定要求,体验就会很好。
这是我们拿到的4张Intel Arc A770显卡运行Qwen2.5 32B型号的演示demo,感受一下速度。够了吗?
看到这里可能有人会问,使用Intel显卡运行AI时出现CUDA问题如何解决?
以最流行的大型模型推理框架之一 vLLM 为例。得益于开源软件的发展,它已经实现了高层的抽象和封装。事实上,您使用哪种硬件并不重要。
再加上Intel自己提供的开源oneAPI,可以实现非常低的迁移成本。

可能有人还会问,为什么不选择专用的AI推理加速器,比如流行的Groq和Sambanova呢?
这意味着多模态交互是当前人工智能应用的一大趋势。无论是与AI视频、数字人对话,还是直播、短视频场景中的一些应用,也会用到视频解码或者图形渲染能力。 ,这需要通用 GPU。
虽然专用加速器在特定任务中具有优势,但通用 GPU 在处理多样化需求时更加灵活。
所以综上所述,使用Intel显卡进行AI推理,具有足够的计算能力和大的显存,这使其可行且具有成本效益。对于现有企业来说,迁移成本更加理想。
未来市场有多大,是否成为趋势,还有待观察。

英特尔的突破曲线
英特尔的消费类显卡正被公司用于人工智能推理。英特尔是什么态度?
我绝对很高兴看到结果并非常认真地对待它。
事实上,英特尔在两年前推出Arc系列时,采取了与竞争对手不同的策略。该许可证显然没有限制数据中心的使用。

为了让大家更容易用好AI,英特尔的软件团队一直在忙碌。除了更新oneAPI之外,还在持续推出和更新一系列开源工具,吸引粉丝。
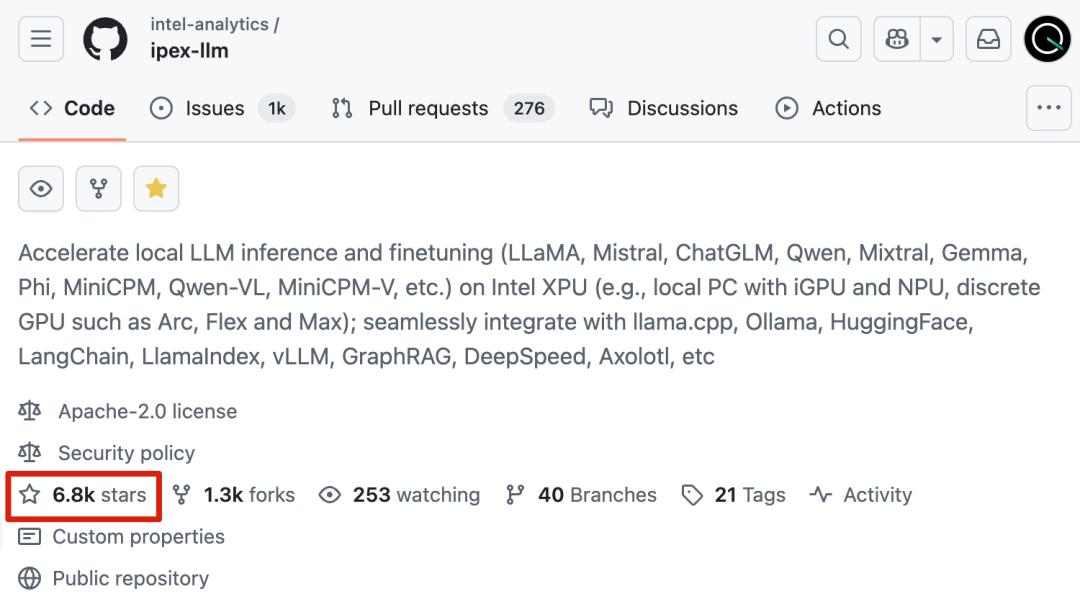
例如,加速库IPEX-LLM可用于大型模型的推理和微调。它在 GitHub 上已经有 6800 颗星。
以及低位量化工具 Neural-compressor,也获得了 2.3k 颗星。
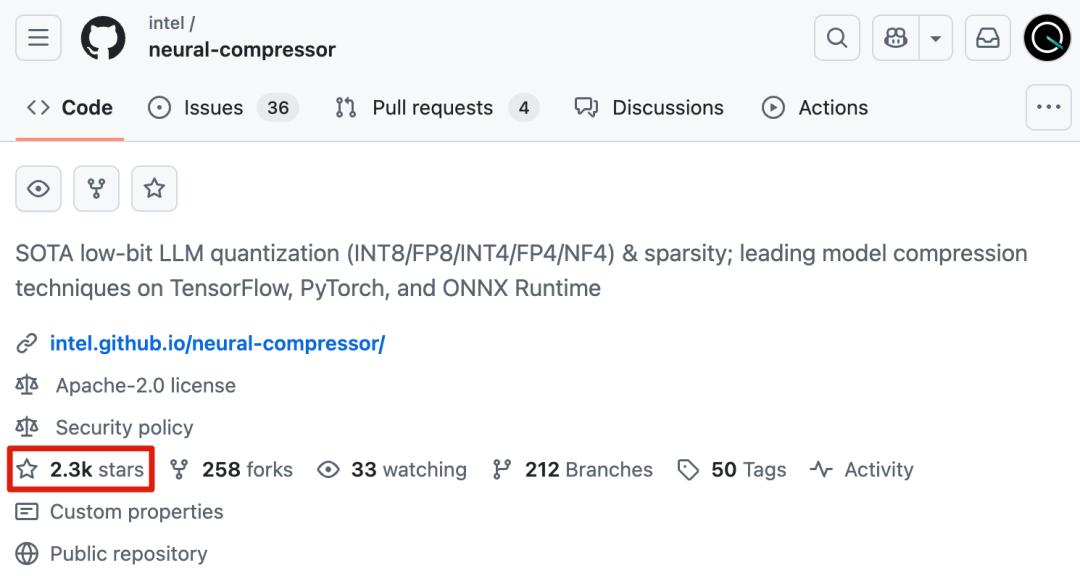
IPEX-LLM也可以看出Intel对中国市场的重视。已经提供了针对中国主流开源大模型ChatGLM、Qwen、MiniCPM等的适配,中文文档和教程也比较齐全。

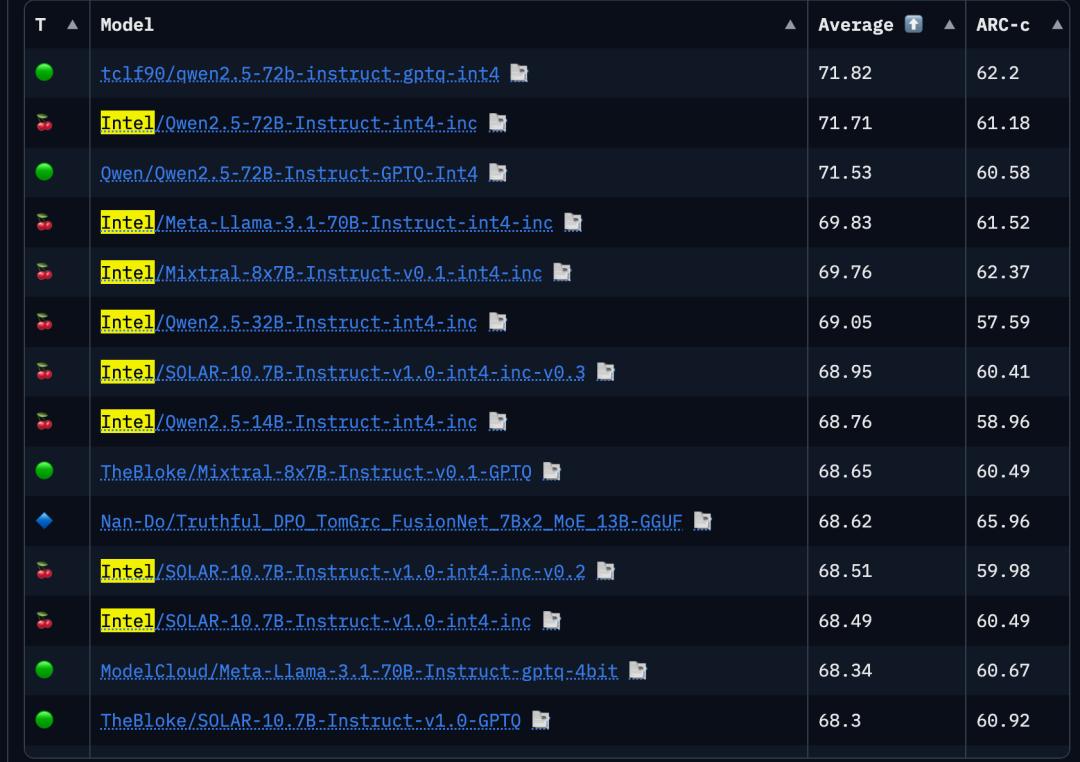
为了方便大家选择模型,Intel还在HuggingFace上维护了一个低位量化模型的排名。设置条件后,您可以一键比较并筛选出您需要的型号。
其中,性能排名靠前的包括英特尔自己量化的来自开源社区的优秀模型。
这样看来,英特尔对AI开源社区的诸多贡献为企业和开发者提供了便利,也是现在大家愿意尝试英特尔显卡的原因之一。
最后,我们还得到了一个内部提示:
英特尔看到AI推理的市场需求逐渐扩大后,也对后续的产品策略进行了调整。
2025年,Intel准备推出更大显存版本的Battlemage系列显卡,容量将提升至24G。
未来,现有版本将继续服务游戏等消费市场,24G更大显存版本将瞄准“生产力市场”。
“生产力市场”的目标用户涵盖数据中心、边缘机房、教育科研、个人开发者等。
具有更大显存的英特尔显卡比专业显卡和工作站显卡更具性价比,不仅适合AI推理需求,还适合渲染和视频编解码应用。
更何况,“从游戏世界转向打工赚钱”+“足够的算力和大显存”很可能是Intel GPU突围的聪明之举。
参考链接:
[1]
[2]
[3]videocardz.com/newz/intel-will-not-prohibit-gaming-arc-gpu-use-in-data-centers
[4]
[5][6]
