12月26日晚,杭州DeepSeek人工智能基础技术研究有限公司(简称“DeepSeek”)宣布,新系列模型DeepSeek-V3首个版本上线并同步开源。 API服务已同步更新,接口配置无需更改。
公开资料显示,深搜由知名量化资产管理巨头欢放量化于2023年7月17日创立。还方量化创始人梁文峰在量化投资、高性能计算领域拥有深厚的背景和丰富的经验。
Deep Search显示,DeepSeek-V3在知识任务(MMLU、MMLU-Pro、GPQA、SimpleQA)方面的水平相比上一代DeepSeek-V2.5有显着提升,并且接近目前表现最好的模型Anthropic发布十月 Claude-3.5-Sonnet-1022。
在美国数学竞赛(AIME 2024,MATH)和全国高中数学联赛(CNMO 2024)中,DeepSeek-V3 显着超越了所有其他开源和闭源模型。此外,在生成速度方面,DeepSeek-V3的生成和铰接速度从20TPS(每秒事务数)大幅提升至60TPS。与V2.5机型相比,实现了3倍的提升,能够带来更流畅的使用体验。
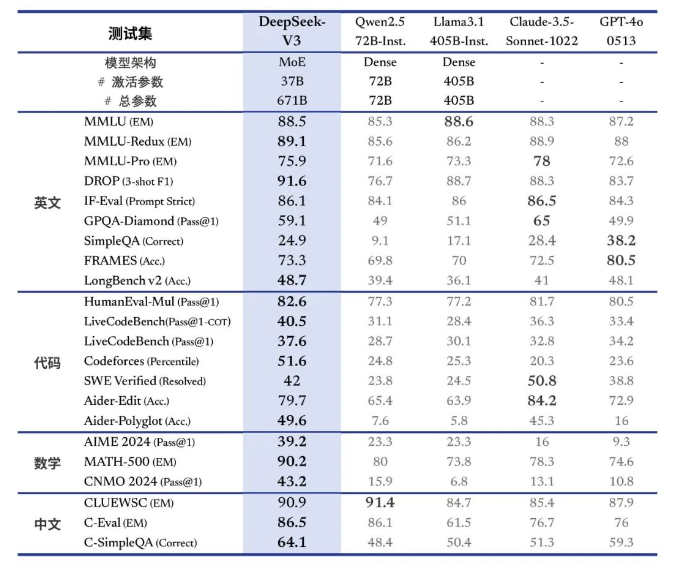
△ DeepSeek-V3与其他型号对比。图片来源:Deep Seek微信公众号
据澎湃新闻报道,meta AI研究科学家田元东对DeepSeek-V3在各个方向上取得的进展表示赞赏,称“这是一项了不起的工作”。
根据官方技术论文,DeepSeek-V3模型的总训练成本为557.6万美元,而GPT-4o等模型的训练成本约为1亿美元。深搜表示,“这是一个全新的开始。”
据财联社报道,OpenAI 联合创始人之一 Andrej Karpathy 也撰文赞扬:作为参考,要达到这种水平的能力,通常需要约 16000 个 GPU 的计算集群。不仅如此,业界正在部署的集群规模甚至达到了10万个GPU。例如,Llama 3 405B 消耗了 3080 万个 GPU 小时,而看似更强大的 DeepSeek-V3 仅使用了 280 万个 GPU 小时。
性能更强、速度更快的DeepSeek-V3上线。 Magic Square Quantification给出的定价是多少?
深搜表示,“我们的模型 API 服务定价也将调整为每百万输入代币 0.5 元(缓存命中)/2 元(缓存未命中),每百万输出代币 8 元。”据财联社报道,总成本为10元。
上一代模型Deepseek-V2.5的价格为:输入:0.14美元/百万Token,输出:0.28美元/百万Token,总成本为0.14+0.28=0.42美元,约3元人民币。
这里的token是一个大模型处理数据时的最小单位。一般来说,100万个代币相当于70万-100万个英文单词,或者接近100万个汉字。列夫·托尔斯泰的代表作《战争与和平》英文版约1200-1500页,58万个英文单词。翻译成中文大约有1-130万字,DeepSeek-V3可以完整阅读。写作仅需2元左右。
尽管价格上涨,但DeepSeek-V3与同类机型相比仍然非常具有性价比。例如,OpenAI的GPT 4o定价相当高。输入:5 美元/百万代币,输出:15 美元/百万代币。总费用为20美元,约合人民币140元。
本文结合 DeepSeek 微信公众号、澎湃新闻、财联社
(免责声明:本文内容仅供参考,不构成投资建议,投资者操作风险自担。)

海量信息、精准解读,尽在新浪财经APP
