大模型赛道之间的价格战已经持续了一年,而且还在继续……
就在过年前一天,阿里云宣布2024年第三轮大型模型降价,同易千文视觉理解模型价格全线下调80%以上。
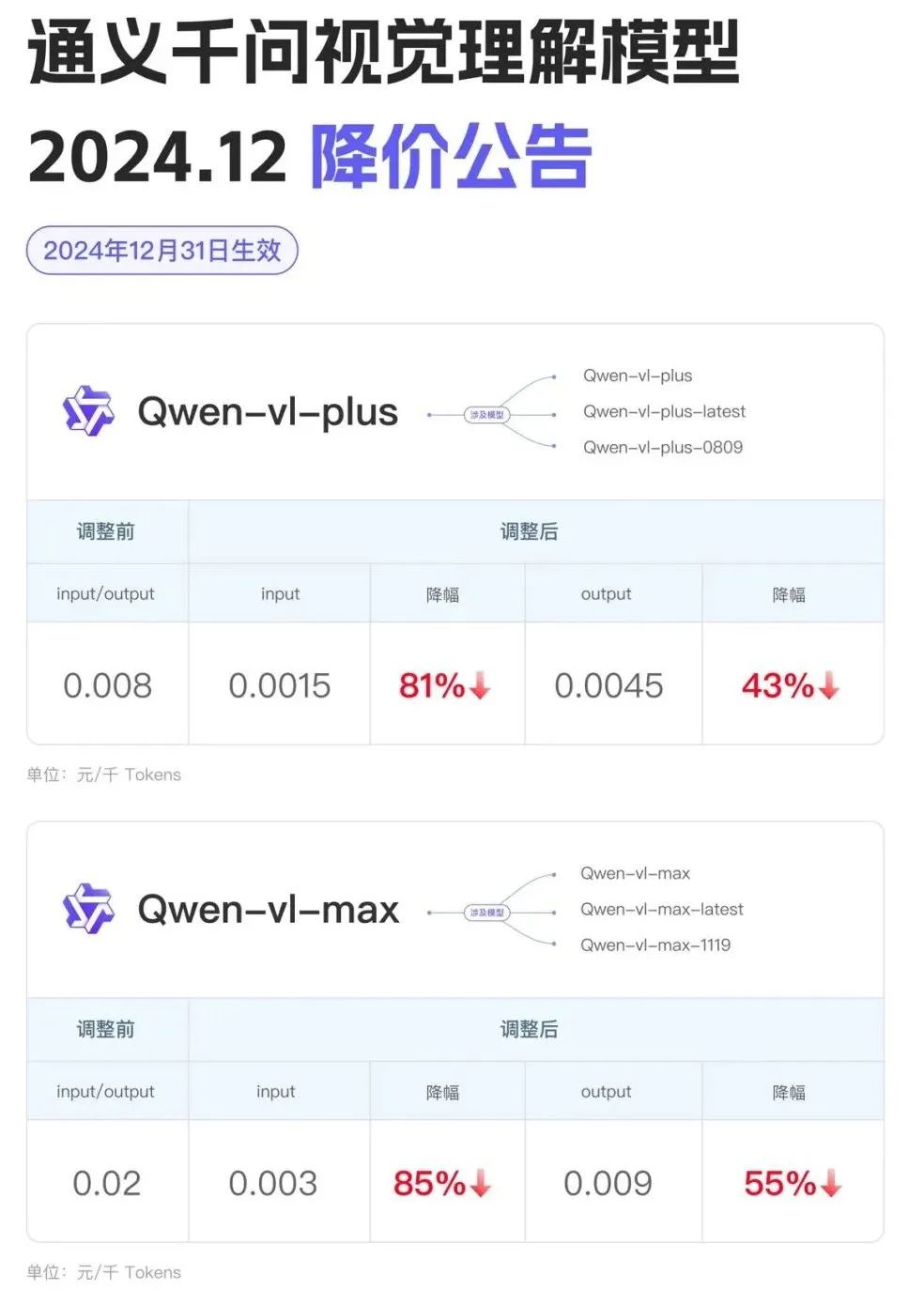
同样,在不久前的火山引擎原力发布会上,除了大力推广豆袋之外,最值得关注的就是价格再次下降。目前豆宝视觉理解模型的投入价格为0.003元/千代币,1元可以处理284 720P图片。
此前,去年5月,豆宝通用模型Pro-32k版的推理输入价格为0.0008元/千币,不到1毛钱。此举迫使阿里云对其三款同易千文核心机型进行新一轮降价,降幅高达90%。百度智能云则更为激进,宣布文信模型两款旗舰产品ENIRE Speed和ENIRE Lite将全面免费向公众开放。
火山发动机总裁谭代表示,“市场需要充分竞争,成本降低是技术优化的结果,只有做到最好,才能生存。”显然,在这场大规模的模型军备竞赛中,豆宝想要上演一出“力量就能创造奇迹”的大戏。
但在 Byte 的疯狂内卷化过程中,也不断有人提出疑问:豆袋椅的价格真的足够便宜吗?为什么大型型号价格昂贵?未来价格还会成为企业订单的重点吗?
01 降价是否夸张?技巧十足
想要了解大模特商家的套路,就需要了解大模特的经营模式。据《远传科技评论》显示,目前各公司提供的服务主要可以分为三种类型:
首先是基础服务,包括模型推理,是指根据输入的信息内容给出答案的过程。简单来说,就是“实际运用”模型的过程。每个公司在这部分都有不同的模型标准。
二是模型微调。厂商可以根据客户需求按照代币使用量(训练文本*训练迭代次数)进行收费。培训结束后打款到账,按金额付款。
第三种是模型部署,相当于客户独占一部分计算资源。这是一个大客户。其收费模型也是基于计算资源的消耗或模型推断的代币数量。
这三种充电模型也代表了大模型由浅入深的发展过程。各大科技公司讨价还价的其实是第一个基础服务,即标准版模型的推理费。这部分定价分为两部分:“投入”和“产出”。简单来说,输入就是用户问题的内容,输出就是大模型的答案。
在调用大型模型时,往往会根据输入和输出令牌的数量进行双向计费。这种细微的差别很容易成为大型模特公司的惯例。
例如,豆宝通用型号豆宝Pro-32k的投入价格为“0.8元/百万代币”。据官方说法,比行业便宜99.3%。一些主流机型也开始降价,比如阿里云的三通易机型。钱文主力机型Qwen-Turbo的价格较之前下降了85%,低至百万代币0.3元,Qwen-Plus和Qwen-Max的投入价格进一步分别降低了80%和50%,至分别为0.8元/百万代币和20元/百万代币。
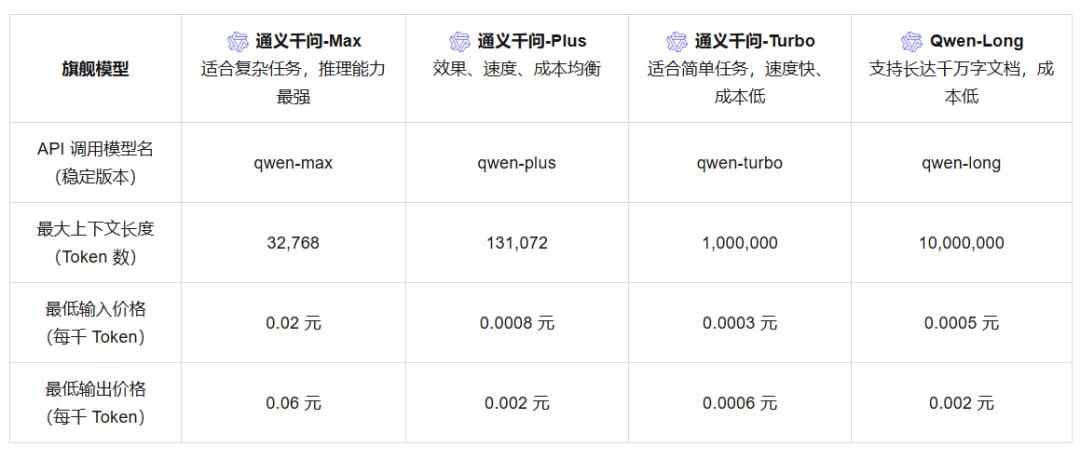
但产出价格存在差异。 2元/百万代币的价格与Qwen-Plus、DeepSeek-V2等同行相同,甚至高于Qwen-Turbo、GLM-4-9B等部分同行。
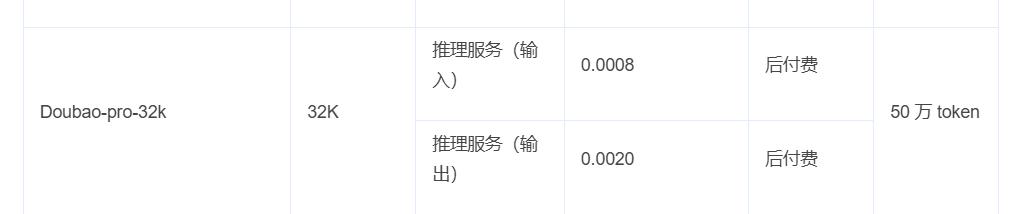
看最新的豆宝视觉理解模型Doubao-vision-pro-32k,输入价格为每百万代币3元,约合0.4美元,输出直接9元,约合1.23美元。据豆宝介绍,这个价格比行业平均价格便宜85%。
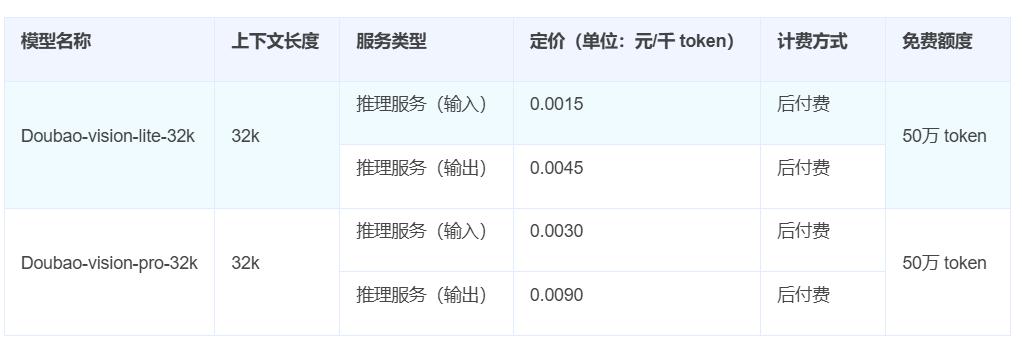
但对比几个直接竞争对手:阿里巴巴的多式联运车型Qwen-VL系列在近期降价后,定价已与其价格一致;多模态 Gemini 1.5 Flash 模型报价为每百万输入代币 0.075 美元,每百万输出代币成本为 0.3 美元,对于较小的上下文(小于 128k)有折扣; GPT-4o mini 输入价格为 0.15 美元,输出价格为 0.6 美元。
但不光是豆袋,国内其他厂家基本都有类似的降价“套路”。例如,百度宣布免费提供ERNIE-Speed-8K。如果实际部署,费用将变为5元/百万代币。还有阿里巴巴的Qwen-Max,其实和字节跳动的通用豆包型号Pro-32k是一样的,只是投入价格降低了。
值得一提的是,标准模型推理的降价确实可以让中小开发者降低成本,但只要用得远一点,就涉及到模型微调和模型部署。不过,这两项服务从来都不是价格战的主角。而且降价幅度也不大。
简单来说,各家降价最厉害的其实是轻量级预制车型;相比之下,实力更强的“超大杯”机型实际降价幅度并没有那么夸张。例如,精调豆宝-pro系列的价格为50元/百万代币,高于阿里巴巴、腾讯等厂商的旗舰机型。
各大厂商发起的价格战就像玩网络游戏一样,用各种形式来吸引玩家,然后在游戏中加入各种玩法。总之,想要变强,就得花钱。当然,即便如此,各大厂商也付出了很多真金白银,那么为什么这些厂商还要在价格上花这么多钱呢?
02 要想做好,热度就不能停
纵观大型模特行业,字节跳动绝对不是起步最快的玩家之一。甚至在今年年初,字节跳动CEO梁如波在一次内部演讲中就提到了“慢”这个词,直指字节跳动对于大机型的态度。与初创公司相比,他们的敏感度较低。
“直到2023年,GPT才开始被讨论,行业里做得比较好的大型模型初创公司都是在2018年到2021年成立的。”他说。
后来者往往是最需要卷入的,字节跳动也是如此。从今年年中开始,就开始掀起一波又一波的人气。
除了上面提到的,除了B端豆包市场明显的减利降价意图外,C端市场的豆包市场也在全力以赴。
对于C端来说,无论是线上平台还是线下公共场所,都可以看到豆袋的身影。据《Wired Insight》援引AppGrowing统计,截至11月15日,国内十大AI原生应用中,Kimi和豆宝是最受欢迎的两款产品,投资额分别为5.4亿元和4亿元。
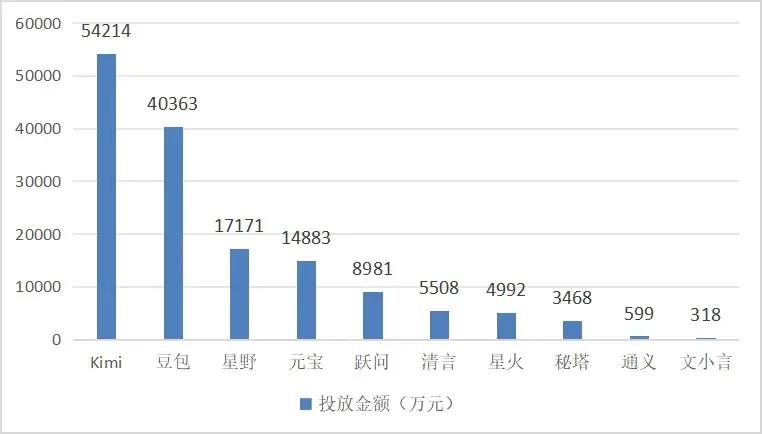
从更长的时间来看,豆袋的流动显然更加激烈。据AppGrowing统计,2024年4月至5月,豆宝上线金额预计为1500万元至1750万元。 6月初,豆宝再次发起新一轮大型广告活动,投资金额高达1.24亿元。
除了直播,豆宝还有抖音这个流量池。字节跳动已经屏蔽了除了豆宝之外的几乎所有人工智能应用程序在抖音上发布。目的也很明确,就是彻底解决大模型应用的“用户焦虑”。
然而,现实往往适得其反。据《智能涌现》报道,字节内部反映——豆宝目前的用户活跃度并不是很高。豆宝每周仅活跃2至3天,用户每天发送消息仅5至6次,每次持续约2分钟,每个用户的平均使用时间仅约10分钟。过去一年这些数据的增长并不显着。
简单来说,不计成本的投入让豆宝成为了国内用户数量最多的AI软件,但它仍然不是杀手级应用。
字节管理层的判断是,像豆宝这样的AI对话产品可能只是AI产品的“中间状态”。字节内部的判断是,付费订阅模式在中国不太可能成功。时长和轮次过低,导致潜在的广告空间较小,这对此类产品构成了无形的天花板。
因此,从长远来看,更低的门槛、更多“多式联运”的产品形态更有可能落地。切割和梦想可能是合适的入口。这也是本次大会豆宝将部分重点放在视频模型上的本质原因。 。
但从用户角度来看,据《财经杂志》报道,大多数用户付费的原因是产品和服务能够带来价值。价值不仅仅是解决具体问题,比如提高工作效率、提供情感陪伴等,市场上还有一类价值是“符合政策方向”。更重要的是找到特定客户并交付的能力。这考验着AI公司超越技术和产品的能力。很多时候,这种能力能够帮助AI企业成长的不仅仅是技术实力。
中国的人工智能市场与美国不同。通过平台销售模式很难打开市场。很多时候,需要一个一个地抓住项目、项目,才能实现商业化。这些项目和项目的由来往往和它们本身的受欢迎程度有关。
“当一个成熟的公司布局大模型时,很难考虑不成熟的产品或公司。在不考虑成本的情况下,大品牌往往是首选。这不仅仅是技术上的信任,更是服务、整体的信任。” “质量问题”,一位科技公司经理告诉《科技报》,“毕竟小厂还是有风险的,就像买车开着,如果车厂破产了,损失会很大。”
初创公司制造热点新闻,最有可能筹集资金并生存下来,而有背景的豆宝则想依靠人气来寻找并留住更多客户,但这却是圈内默认的事实,那就是,没有无论你是谁,无论你的技术有多强大,你都必须善于保持热度。毕竟,喝得好,也可能会怕巷子深。
03 淘汰赛,或告别价格战
事实上,不光是豆宝,目前市面上所有二线、下线的大机型厂商都处于花钱买流量以留住用户的阶段。因为这场不折不扣的“滚王秀”背后是疯狂的产品能力和研发速度,也意味着这场大型模型服务商关于“挤泡沫”的淘汰赛再次吹响了号角。
2024年,已经经历了一轮淘汰赛,让9个大车型节省了1个,产业结构更加合理,只剩下10%左右的大车型进入决赛。
然而,这不是结束,而是开始。只是从《科技报》的角度来看,新一轮淘汰赛的焦点不再是价格成为主导因素而是技术。
目前,科技公司开始意识到,仅仅发布免费应用程序并不能为公司带来直接利益。 C端用户增长困难,获客成本大幅增加。更重要的是直接触达那些愿意付费的B端客户,比如金融、政务、汽车等行业。
但通常当大量企业进入某个行业时,就会出现持久的价格战,因为每个企业都需要打造标杆客户,为后续的市场拓展铺平道路。简单粗暴的价格战,会导致一些企业主动或被动退出。待市场稳定后,价格将恢复正常。
但吊诡的是,每个人都想进入“富人”领域。在长期的价格战中,技术成本成为制胜的关键。简单来说,在同样的方案和报价下,谁的技术成本低,谁的损失就少,寿命就长。
技术成本取决于企业的硬件成本和算法逻辑。目前国内主流大型车型厂商基本处于同一水平,迭代和追赶的速度也都差不多,但这并不意味着他们可以高枕无忧。
今年9月,OpenAI“渣王”o1模型的推出也让大家看到了差距。与现有的大型模型相比,o1最大的特点是“推理型AI”,要回答复杂的问题将花费大量资金。有更多时间逐步解决问题。这种延迟思维并不是缺点,而是让O1更接近人类真正的逻辑推理方法。
从“生成式AI”到“推理式AI”,o1的推出预示着人工智能进入了新的阶段。更令人震惊的是,o1发布3个月后,下一代o系列产品o3诞生了,o3有完整版和迷你版。新功能是模型推理时间可以设置为低或中。 ,high,模型思考时间越高,效果越好。迷你版更加精简,针对特定任务进行了微调,将于 1 月底推出,o3 完整版将在不久后推出。

这也意味着,随着快速迭代,目前主流的生成式AI很快就会成为历史产物。
“价格是影响大型模型公司的一个因素,但更重要的是技术能力。”一位大型模型应用开发商告诉《科技报》。目前,国内阿里巴巴、昆仑万维等公司也推出了类似O1的机型。 “虽然存在差异,但这也意味着他们都认同这个趋势。”
一位业内专家也表示,国内企业正在采取整合思维链的思路,利用搜索方式提升深度推理能力,加入反射策略和算法提升逻辑推理性能,但尚未完全超越OpenAI 。
值得一提的是,最近在国内流行的DeepSeek-V3所采用的蒸馏技术为业界提供了新的思路,但也陷入了“优化GPT”的争论。
对于人工智能训练可能使用合成数据(大型模型生成的数据)的话题,伦敦大学学院(UCL)名誉教授兼计算机科学家彼得·本特利(Peter Bentley)表达了担忧,他说:“如果人工智能继续根据合成数据的输出进行训练,其他AI,结果可能是模型崩溃。确保高质量人工智能的唯一方法是为其提供高质量的人类内容。”
“缺乏现成的开源架构可供参考,不清楚如何加强学习,o1模型后期训练时使用的数据集,树搜索和COT不开源,训练数据受到污染,而且国产模型的推理性能很难提升,这些都是国内企业目前面临的问题,”专家补充道,“但如果出现支持o1架构的开源模型,那就会提速。进程。在此过程中,两到三个公司将首先运行,其他公司将跟随。”
如果按照以往GPT系列的发展节奏,极有可能在2025年上半年所有厂商都会赶上O系列,而在此之后,目前的技术将逐渐退出历史舞台所以对于大型模型厂商来说,与其等着被淘汰,不如在被淘汰之前让迭代技术发挥更大的作用。
总体而言,虽然未来价格仍将是影响企业接单的因素之一,但随着技术的快速迭代和行业的发展,技术能力将变得越来越关键。规模化企业只有不断改进技术、降低成本、优化服务才能赢得订单。只有模型制造商才能在即将到来的淘汰赛中生存下来。
参考:
[1]《豆包价格再次下跌,字节“饱和”攻击持续》,Wired Insight
[2]《大机型的价格战可以更狠》,远传科技评论
[3]《中国模式大洗牌年即将开启,隐藏两大逻辑》,财经
[4]“字节内部判定AI对话产品天花板可能不高,提高剪辑和做梦的优先级”,智能的出现
