
AIxiv专栏是机器之心发布学术和技术内容的专栏。几年来,机器之心AIxiv专栏已收到2000余篇报道,覆盖全球各大高校和企业的顶级实验室,有效促进了学术交流和传播。如果您有优秀的作品想要分享,请随时投稿或联系我们进行举报。投稿邮箱:liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
可控视频生成需要对摄像机进行精确控制。然而,视频生成模型的摄像头控制总是不可避免地伴随着视频质量的下降。近日,来自多伦多大学、Vector Institute、Snap Research和西蒙弗雷泽大学(SFU)的研究团队推出了AC3D(高级3D相机控制)。 AC3D从基本原理出发,分析视频生成中摄像机运动的特点,通过以下三个方面提高视频生成的效果和效率:
1.低频运动建模:研究发现视频中的摄像机运动具有低频特征。研究人员优化了训练和测试的条件调度,加速了训练收敛,提高了视觉和运动质量。
2.相机信息表示:通过研究无条件视频扩散变换器的表示,研究人员观察到相机姿态估计是在内部隐式执行的。将相机条件注入限制到特定子层不仅可以减少干扰,还可以显着减少参数数量并提高训练速度和视觉质量。
3.数据集改进:通过添加包含20,000个动态视频的高质量静态相机数据集,增强了模型区分相机运动和场景运动的能力。这些发现导致了AC3D架构的设计,该架构同时提高了相机控制的效率和视频的质量,使AC3D在相机控制的生成视频建模方面达到了新的技术水平。

方法介绍
研究人员首先构建了Vincent视频扩散模型作为基本模型,并对该模型进行了分析,获得了摄像机控制的首要原理。研究人员随后根据这些原理设计了AC3D。
基本模型:视频扩散模型
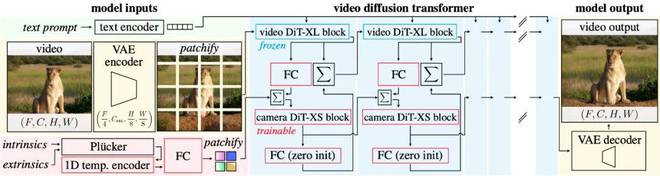
AC3D基于VDiT(Video Diffusion Transformer)构建,采用标准Transformer结构。 VDiT 通过在变分自动编码器 (VAE) 潜在空间中执行扩散建模,根据文本描述生成视频。模型架构包括:
具体来说,研究人员采用了标准设计,预训练了具有11.5B参数的Video DiT模型。该模型包含 32 层,隐藏维度为 4,096,在 CogVideoX 的潜在空间中运行,并使用整流流扩散。基础模型在包含分辨率范围从 17×144×256 到 121×576×1024 的文本注释的大规模图像和视频数据集上进行训练。
相机运动的第一性原理分析
(1) 分析1:运动频谱体(MSV)分析
通过运动频谱体(MSV)分析,研究人员发现相机引起的运动主要位于低频段。与场景移动相比,摄像机移动更平滑且不那么剧烈。而且,84%的低频运动信息在扩散过程的前10%阶段就已经确定,后续不会发生变化。基于这一观察,我们调整了训练和测试的噪声条件调度,以将相机运动注入限制在训练和推理的早期噪声阶段。该方法显着减少了后期制作干扰,同时提高了视频的视觉质量和运动保真度。
(2) 分析2:线性检测的VDiT表征
研究人员使用线性检测实验在 Vincent 视频网络的每一层中训练一个线性层来预测相机参数。实验结果表明:
1、无条件Vincent视频模型在中间层预测摄像机姿态信息最准确;
2.网络的中间层对相机参数具有最好的表示,表明模型在早期隐式注入相机位置信息,并使用后续层来指导其他视觉元素的生成。
基于这一发现,AC3D将相机条件注入限制在前8层,从而减少对其他视觉特征表示的干扰,并显着提高训练速度和生成质量。

(3)分析3:数据集偏差分析
传统的带有相机参数的视频数据集(例如RealEstate10k)几乎只有静态场景。这种静态场景视频使得模型很难区分摄像机运动和场景运动,也使得网络过拟合静态分布,从而降低了生成的视频中国运动场景的质量。然而,仍然没有好的开源解决方案来预测动态视频中的相机运动。研究人员采用了不同的方法,构建了一个包含 20,000 个动态场景的数据集,但使用静态摄像机捕获。
这种动态场景中的静态摄像机和静态场景中的动态摄像机的混合数据集显着提高了模型的学习效果。训练后,模型能够更好地分离相机运动和场景运动,从而产生更真实和动态的视频。
相机控制方式
为了实现摄像头控制,研究人员将ControlNet模块与VDiT结合起来,形成VDiT-CC(VDiT with Camera Control)。具体方法:
1.使用Plücker相机表示,通过全卷积编码器对相机轨迹进行编码;
2.使用轻量级128维DiT-XS模块处理相机编码,直接将相机特征添加到视频特征中进行类似于ControlNet的融合;
3.仅在256x256的分辨率下训练相机运动注入,因为研究人员发现相机运动是一种低频信息。在低分辨率下进行训练还可以在高分辨率下进行推理时实现精确的相机控制。
4. 在训练和推理期间调整相机条件调度,以仅覆盖逆扩散轨迹的前 40%。这种噪声调整将 MSR-VTT 数据集上的 FID 和 FVD 指标平均提高了 14%,并将相机跟踪能力提高了 30%,该数据集用于评估模型对微调分布之外的各种场景的泛化能力。能力)。此外,这种方法还增强了整体场景运动,我们在实验中定性地验证了这一点。
5.仅将相机信息注入前8个DiT块,并无条件保留后续24个DiT块。这种设计可以避免相机信息与后续层中其他特征表示之间的干扰,同时显着降低训练复杂度并提高模型生成效率和质量。
其他改进:为了进一步提高模型的性能和相机控制能力,研究人员引入了以下创新:
1.一维时间编码器:通过因果卷积将高分辨率相机轨迹数据转换为低分辨率表示。
2. 单独的文本和摄像头引导:针对文本和摄像头信号独立设计引导机制,并单独调整每种输入类型的权重。
3.ControlNet反馈机制:通过交叉注意力提供从视频到相机的反馈,以优化相机表示。
4.去除相机分支的上下文信息:消除上下文干扰,提高相机轨迹的跟踪能力。
通过这些方法,AC3D在相机控制效率和生成质量方面取得了重大突破,为高质量文本生成视频提供了新的技术标杆。
模型结果
研究人员展示了一系列提示词以及不同摄像机轨迹下可控视频的生成(总时长40秒)。通过这些视频,可以直观地观察AC3D在摄像机控制方面的表现。
提示:
1. 在艺术工作室里,一只戴着贝雷帽的猫正在小画布上作画。
2. 在未来厨房里,宇航员熟练地用平底锅做饭。
3. 在舒适的厨房里,一只泰迪熊正在勤奋地洗碗。
4、热带海滩上,一只金毛犬坐在沙滩上,兴奋地吃着冰淇淋。
5、公园的长椅上,一只松鼠用小爪子抓起一个多汁的汉堡,悠闲地吃着。
6. 一只水獭在舒适的咖啡馆里熟练地操作浓缩咖啡机。
7. 一只戴着小厨师帽的猫在别致的城市厨房里揉面团。
8. 在厨房里,一名宇航员正在用锅做饭。
9. 在未来派的东京屋顶上,一只戴着耳机的机器考拉正在混合音乐。
10. 穿着正式服装的猫坐在棋盘前,专注于下一步。
11. 在一片废墟中,一个孤独的机器人正在寻找可用的材料。
12. 一只穿着文艺复兴服装的小老鼠正在优雅地吃一块奶酪。
总结
AC3D系统地分析视频扩散模型中的摄像机运动,显着提高控制精度和效率。通过改进的条件调度、特定于层的摄像机控制和更准确的校准训练数据,该模型在 3D 摄像机控制的视频合成中实现了最先进的性能,同时保持了高视觉质量和自然场景动态。这项工作为文本生成视频中更精确、更高效的摄像机控制奠定了基础。未来的研究将集中于进一步克服数据限制并开发适合训练分布范围之外的相机轨迹的控制机制。
