OpenAI o3模型的发布引发的人群狂热是我们从未见过的。
有些人实在坚持不下去,选择放弃计算机科学职业,因为他们觉得这些技能在人工智能时代很快就不再需要了。
但这只是彻头彻尾的哗众取宠而已。
这是这个行业最糟糕的一面:人工智能影响者正在煽动大量不必要的炒作,他们不择手段地通过点击获利,但对我来说,他们看起来完全是骗子,充其量是无知。
在这篇文章中,我将解释为什么这是无稽之谈,以及为什么 2025 年没有人会因为 o3 而失业。
下面我们仔细看看。
令人印象深刻但有点微妙的公告
随着 OpenAI 发布最新大型推理模型 (LRM) o3 的消息逐渐消失,现实开始浮出水面。
历史性的时刻
是的,从表面上看,这个模式令人印象深刻,令人印象深刻,以至于让你怀疑明年是否还能找到工作。
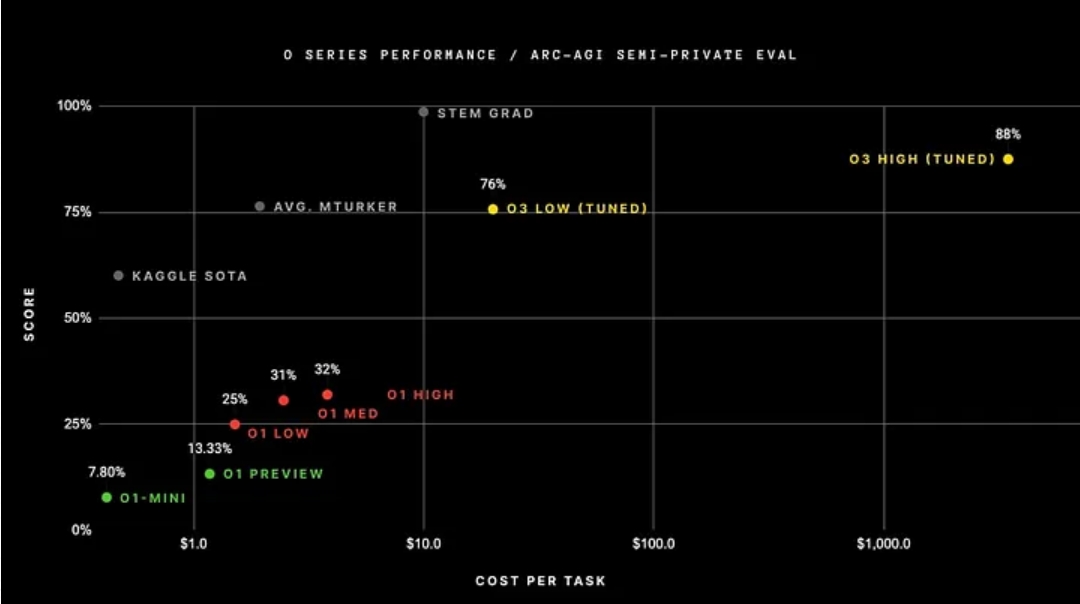
O3 在许多基准测试中取得了惊人的结果,但其中一个特别令人感兴趣:在 ARC-AGI 公共基准测试中,o3 在高计算阈值(这允许模型思考更长时间)下实现了 87.5% 的准确率。
人工智能第一次可以执行抽象推理任务——识别网格对象中存在的微妙模式并将其应用到新的例子中——表现优于普通人类。
测试主要涉及智力的两个关键方面:
即时学习技能。换句话说,受试者是否可以即时学习新模式。
学习效率,即受试者能否仅通过少数例子学习新模式。
人工智能模型能够成功完成这一挑战确实值得称赞,但结果并不像我们看到的那样。
未提及的微妙之处
虽然说结果不能反映现实有点太绝对了,但也没有AI网红说的那么可怕。
假设有两个孩子参加考试。其中一位仔细思考了20多分钟,答对了80%。另一个孩子答对了90%,却花了整整两个月的时间才完成考试。
哪个孩子更聪明? 20 分钟内正确率达到 80% 吗?还是花了两个月的时间取得更好结果的人?
在我看来,智能不仅仅是单纯的价值,效率也很重要。但说到效率,人工智能仍然非常非常糟糕。
据业内人士透露,O3在基准测试期间完成一项任务的平均处理成本为5000美元。
用白话来说,在解决人类最多几分钟就能解决的网格图案问题时,O3 在每个任务上平均花费 5700 万个 Token(单词元素,大约相当于超过 4000 万个单词),总共花费 5,000 美元。
换句话说,像o3这样的大型推理模型(LRM)使用大得离谱的计算和资金,将解决问题的游戏变成了只要计算能力足够就能找到正确答案的游戏。
而且这还不考虑5亿美元的模型训练成本,所以总数可能连巴菲特都头晕了。
我想说明的是,像o3这样的人工智能想要对社会产生真正的影响,就必须大幅提升其智能效率,或者说提高“智能”/算力的比值。
但这个效率如何计算呢?
位/字节比
标准大语言模型(LLM)的主要性能指标是困惑度(perplexity)。通俗地说,它衡量模型的“惊喜”程度,或者说它在预测下一个单词时的信心程度。
如果混淆减少,则意味着对单词应该是什么更有信心(通过分配给所选单词的置信概率来衡量)。
但LRM的主要指标是每字节位数(BpB)。
新指标的出现
ByB 测量每个生成的标记或单词传达的信息“量”。
如果在回答时使用LRM来生成推理和响应令牌,则每个任务生成的令牌数量会大得多。这时候,仅仅准确预测下一个单词已经不够了。该单词还必须具有相关性,以便模型可以逐渐减少生成的标记数量。
令人欣慰的是,o3 在 ARC-AGI 测试中取得了近 90% 的准确率,但你会发现它为每个问题生成数百万个 token,而人类最多只能生成 100 到 200 个 token。这就足够了(如果可以这样比较的话)。
所以,如果我们想要真正衡量像o3这样的O型模型的智能,我们不仅要衡量响应的质量,还要衡量模型创造价值的效率。
这就是为什么 BpB 是一个很好的指标; o3 的响应通常是正确的,但 BpB(即每个生成的令牌的信息量)低得离谱。套用之前的比喻,人类就是20分钟内答对80%的孩子;人工智能打败了我们(只是有时),但它需要相当于“人一生”的时间才能做出反应。
但问题并没有就此结束。正如顶级人工智能研究员迈尔斯·克兰默指出的那样,O 形模型似乎并没有改善幻觉现象。
事实上,用户体验实际上变得更糟,因为模型比以前更频繁地犯错误,就好像它对自己的知识变得更加自负一样。
结果是 O 模型体验不仅成本高昂,而且可能导致代价高昂的错误。
保持冷静
对于人工智能研究实验室来说,引用基准测试结果来比较其他实验室的产品是一个很好的手段,因为它可以体现自己模型的实用性和“智能性”,但目前还不能反映现实。 。
o3的成绩还是值得肯定的
o3 在 ARC-AGI 或 FrontierMath 测试上的结果值得祝贺,有一个非常重要的原因:因为它再次给了我们希望,人类可能正朝着通用人工智能(AGI)的正确方向前进。
但说它“征服了AGI”是绝对错误的。这意味着这些模型比实际情况要聪明得多。但就智力效率而言,他们仍然比孩子笨,o3 的结果并没有改变这一点。
事实上,他们进一步证实了这一点:o3 需要数百万美元才能通过某个基准,因为他们必须生成数百万代币来解决某个具有挑战性的网格模式查找问题。
这不是AGI,它只是证明只要有足够的计算能力,AI模型确实可以取得显着的结果(再次强调,真正的胜利是更多的计算能力可以带来更好的结果)。
无论如何,o3 必须被视为计算似乎是解锁智能的关键这一想法的证明,但我们距离我们希望通过这些系统开发的真正智能还很远(甚至 OpenAI 也承认这一点)。
话虽如此,我们还是有理由乐观的:ChatGPT 自推出以来已将处理成本降低了 100 倍。另外,o3-mini虽然更加“智能”,但其运营成本甚至比o1-mini还要低。
换句话说,我们确实正在改进 BpB 指标,但现实是这个过程将比人们想象的要长得多。
我们的工作会受到影响吗?影响因素有哪些?
嗯,其实很简单:钱。
激励就是一切
为什么这种模式不能真正渗透到劳动力市场呢?原因无非就是成本。想一想:
当然不是!
如果O3的价格降到零,每个人都会有一个可以解决一些最困难的数学问题的模型。
至于解题过程是否依赖死记硬背和大量“思考”,你并不关心,你只关心结果。但现在,如果大规模部署o3,公司几天之内就会破产。
人工智能的真相以及如何探索机器智能
我们的目标从来不是,也永远不会是——创造真正的智能;我们的目标始终是让机器智能比人类智能更便宜。
如果人工智能实验室实现了这一点,我们就可以提出这样的问题:这些工具是否会取代一些人类(再次强调,谈论人工智能取代所有人类工人是廉价的危言耸听)。
虽然LLM实现了这一逆转,但他们却做得很愚蠢。一旦 LRM 变得比雇用人类更便宜,真正释放的人才就会出现。 o3 确实可以问问自己是否需要额外的软件开发人员,或者支付订阅费并将工具交给原来的高级软件开发人员是否更划算。
类似这样的问题即将出现,但到 2025 年这些数字还会增加吗?我非常怀疑,特别是考虑到各个人工智能实验室可用的计算能力和能源的限制。
那么它算AGI吗?
别再说这些可笑的话了
过去几天,我在社交媒体上看到许多声称 o3 是 AGI 的说法,因为它在 ARC-AGI 公共基准测试中取得了令人印象深刻的结果。
让我澄清一下:这不是事实,而且这种说法令人尴尬。
这些说法基于以下两点之一:要么是无知,要么是为了吸引注意力而哗众取宠;就连 OpenAI 也不敢做出这样的说法。
无论如何,o3 值得庆祝,因为它是一项奖励工程努力的突破。与过去的 AlphaGo 或 AlphaStar 一样,该模型在奖励可验证的领域(即奖励函数可以自动验证的领域,例如编码或数学)实现了超人的壮举。
然而,o3 是第一个实现奖励通用性的模型,即用单一数据分布训练的模型可以在多个领域(也是可验证领域)取得超人的结果。这很疯狂,但这不是 AGI。为了实现AGI,这个奖励函数(或多个函数)应该推广到其他无法自动计算奖励的领域;这是人工智能的圣杯,但尚未实现。
AGI还必须考虑经济因素。简而言之,情报成本必须低于实施成本,才能具有经济意义。
为了实现AGI,我们需要做两件事之一:将代币成本降低到接近零(算力成本和能源成本),或者找到一种方法让AI更快、更便宜地解决问题(增加BpB指标,即算法的突破)。
o3模型给了我们希望,增加计算能力将继续带来更好的“智能”,但这是通过测试时的计算来实现的,而不是通过增加预训练预算来实现的。
但我们不要再假装它不是这样的东西(AGI)。
译者:博熙.
