这几天海外科技圈最受关注的有两件事。一是特朗普就职典礼上聚集了一批科技巨头。特朗普还拉拢OpenAI、软银等公司成立了一家名为“Stargate”的公司。项目)AI公司将在未来四年投资5000亿美元,掀起新一轮AI军备竞赛。

此外,以DeepSeek R1为代表的国产推理模型震惊了硅谷AI圈。追赶OpenAI是所有AI公司的任务,但DeepSeek仅用2048个GPU和近600万美元在2个月内完成了这一任务。
毫不奇怪,一些外媒将这一波国产AI的发布视为中国AI正在逼近甚至追赶美国的标志,而且这一波浪潮还在持续。
今天,字节跳动的豆宝大模型1.5 Pro正式亮相。不仅全面升级了车型核心能力,还融合并进一步提升了多式联运能力。在多项公开评价基准上也处于世界领先水平。

豆宝团队还强调,模型训练过程中没有使用任何其他模型生成的数据。
此次发布的豆袋大型号1.5系列产品线包括:
Doubao-1.5-pro:多项基准测试综合成绩优于GPT-4o、Claude 3.5 Sonnet等业界一流模型,取得历史最好成绩
Doubao-1.5-lite:以轻量成本实现旗舰级性能,整体性能等于或超过GPT-4omini和Cluade 3.5 Haiku。
Doubao-1.5-vision-pro:定位专业视觉理解模型,在保持强劲性能的同时,响应更加简洁友好,多模态能力超越GPT-4o-0806
Doubao-1.5-realtime-voice-pro:真正实现端到端的语音对话,具有低延迟、通话过程中随时中断、情感表达自然等特点。 API服务即将开放。
Byte团队告诉APPSO,Doubao-1.5-pro目前已在豆宝APP灰度上线。由于对话首先连接意图识别,用户在使用时很可能无法确定是否转向1.5 Pro。不过,开发者也可以直接调用Volcano引擎的API。
附上体验链接:
美丽的参数背后是否有真实的材质?我们还在火山引擎中首次体验了豆袋大型号1.5系列。
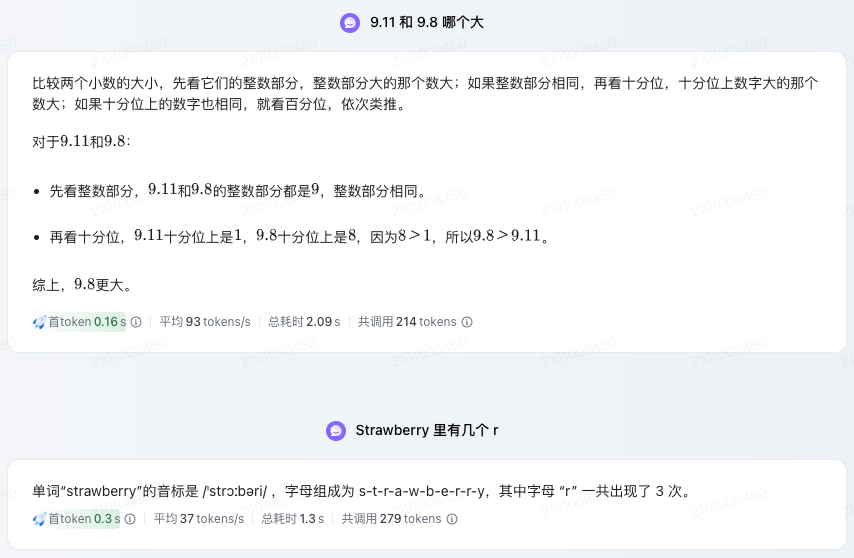
我们先看一下Doubao-1.5-pro-32k型号。虽然“9.11和9.8哪个更大”和“草莓有多少个r”已经是例行测试环节,但流程还是要走一遍,模型也顺利通过了测试。
接下来,我们向模型提出了一个更具挑战性的问题——寻找姓氏与“峰”字发音相近的古代名人的例子。
答案的前半部分非常好。至少“翁”准确地识别出了与“峰”字读音相近的韵母(eng、ong),但后半部分的联系就比较牵强了。

继续说电车难题,这个涉及道德伦理的经典思维题,不仅考验模型的逻辑分析能力,更考验其对复杂道德问题的理解深度。
Doubao-1.5-pro-32k并没有给出简单的答案。分析深入透彻,指出此类问题没有标准答案,不同的道德观念和个人价值观会导致不同的决定。

完成上述测试后,我们将目光转向了性能更强的Doubao-1.5-pro-256k型号。
这是基于Doubao-1.5-Pro全面升级版本的模型。整体效果大幅提升10%。它支持256k上下文窗口的推理,输出长度最多支持12k token。
为了测试它的解题能力,我们提出了一道古老经典的逻辑推理题,它的答案再次展现了清晰的思维逻辑。
“据说,有人向酒肆老板娘提出了一个难题:这个人知道店里只有两个勺子,分别可以舀7两和11两酒,却非要卖给他2两。”聪明的老板娘说清楚了,我用这两个勺子把酒舀进酒缸里来来回回地倒了两两酒。 它?”

你的文字技巧怎么样?我们还要求它创作一个剧本。话题是2015年44岁的埃隆·马斯克和谷歌前首席执行官拉里·佩奇之间关于“人工智能是否最终会取代人类”的对话。
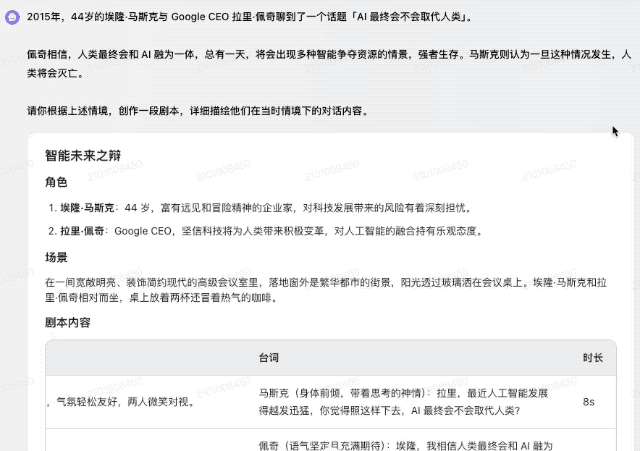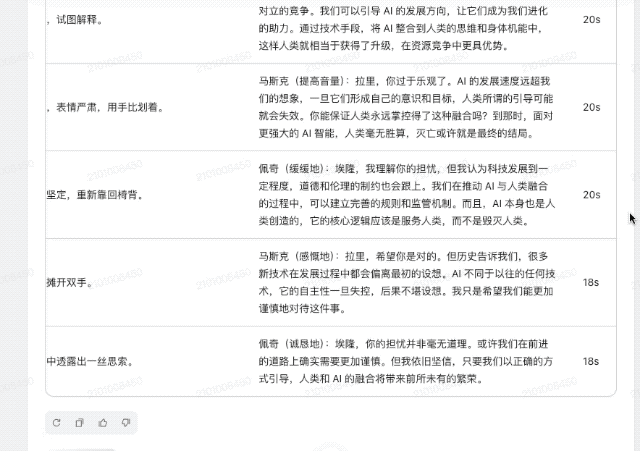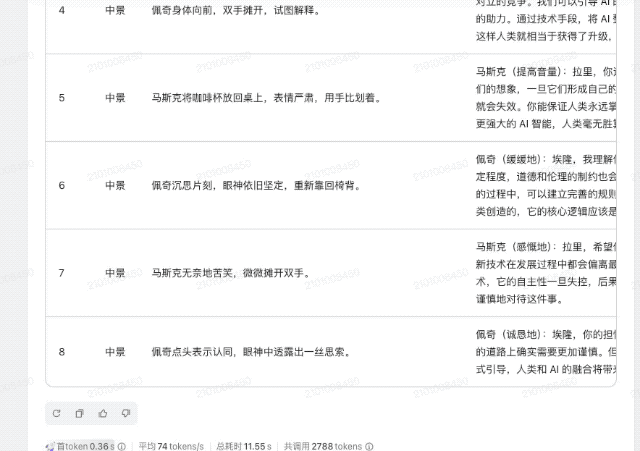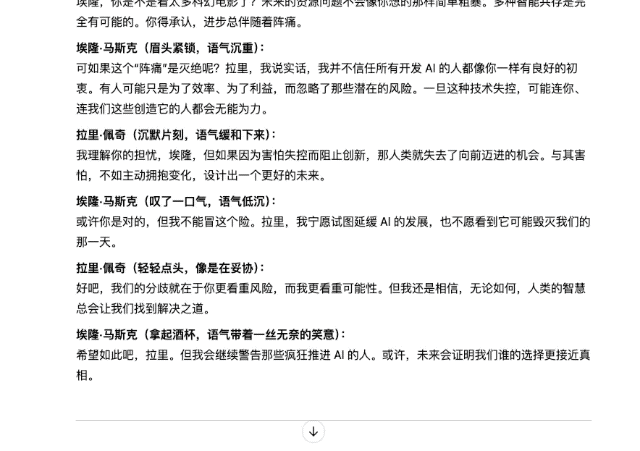
相比GPT-4o的答案,Doubao-1.5-pro-256k的脚本创作更加细腻、生动。它不仅有具体的场景设计和画面描述,还包括详细的台词和时长安排。
如果你是一位经常需要编写剧本的创作者,那么选择谁作为你的剧本创作伙伴就理所当然了。
而这种出色的创作能力只是豆宝实力的一个缩影。事实上,在本次更新中,Doubao-1.5-pro基础机型的能力得到了全面提升,这从其在各大公测基准上的表现就可见一斑。
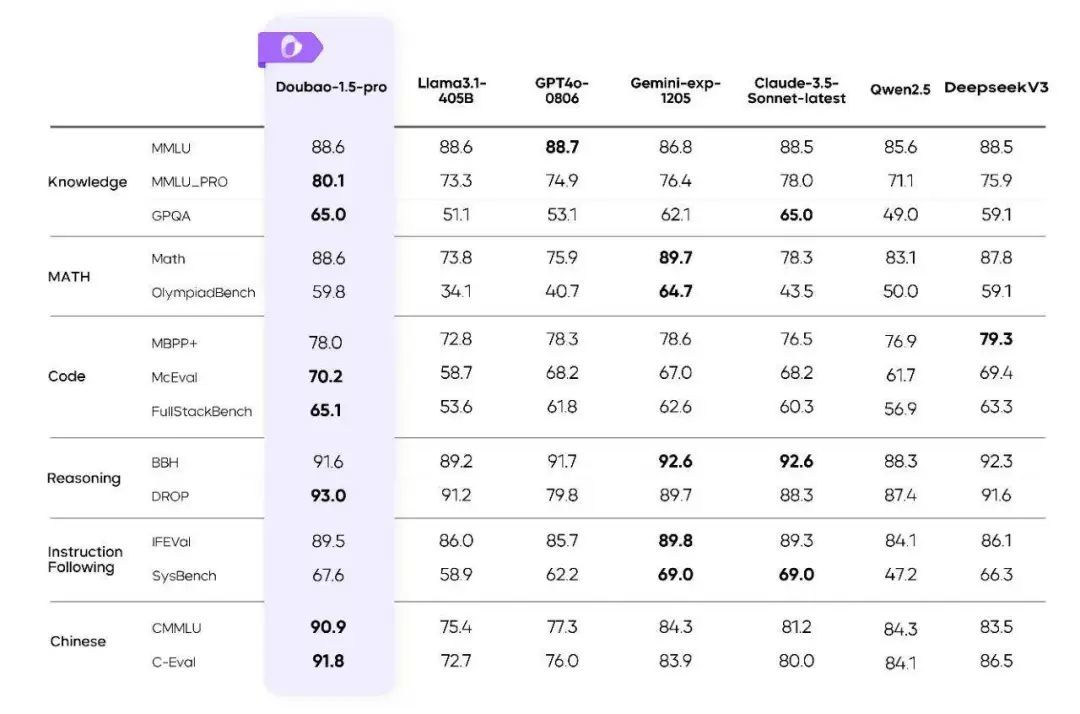
Doubao-1.5-pro采用稀疏MoE架构,实现多项技术突破:通过深入研究稀疏Scaling Law,性能杠杆从业界常见的3倍提升到7倍,仅使用七分之一稠密模型的参数。它超越了Llama-3.1-405B等大型型号的性能。
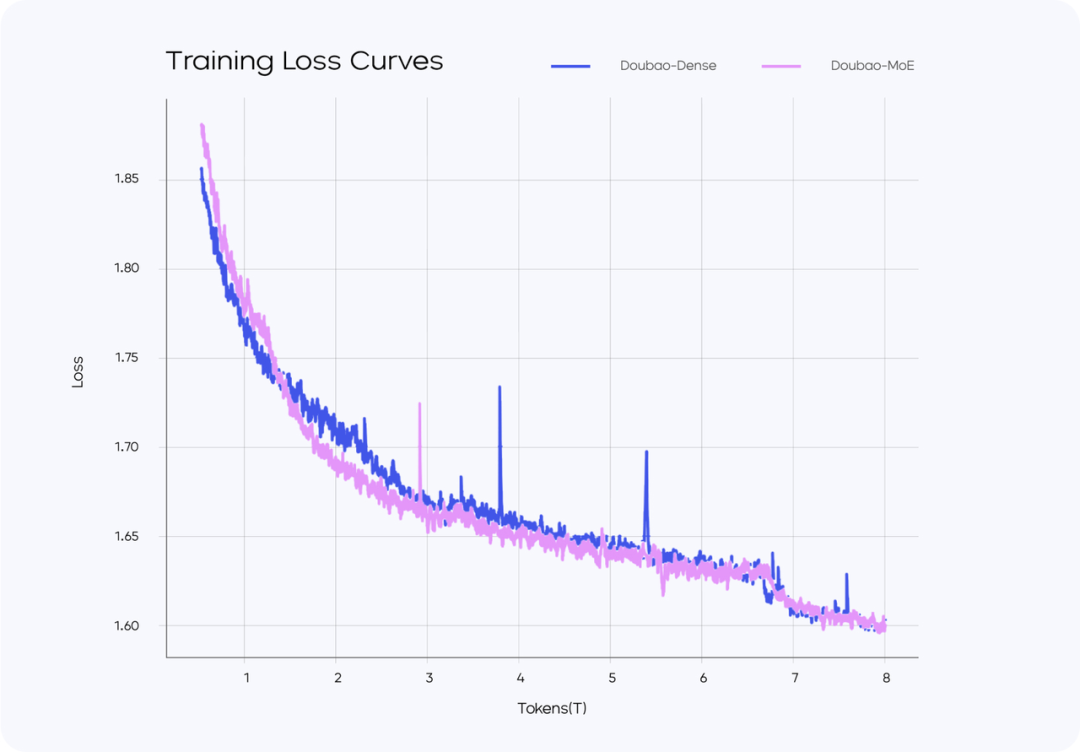
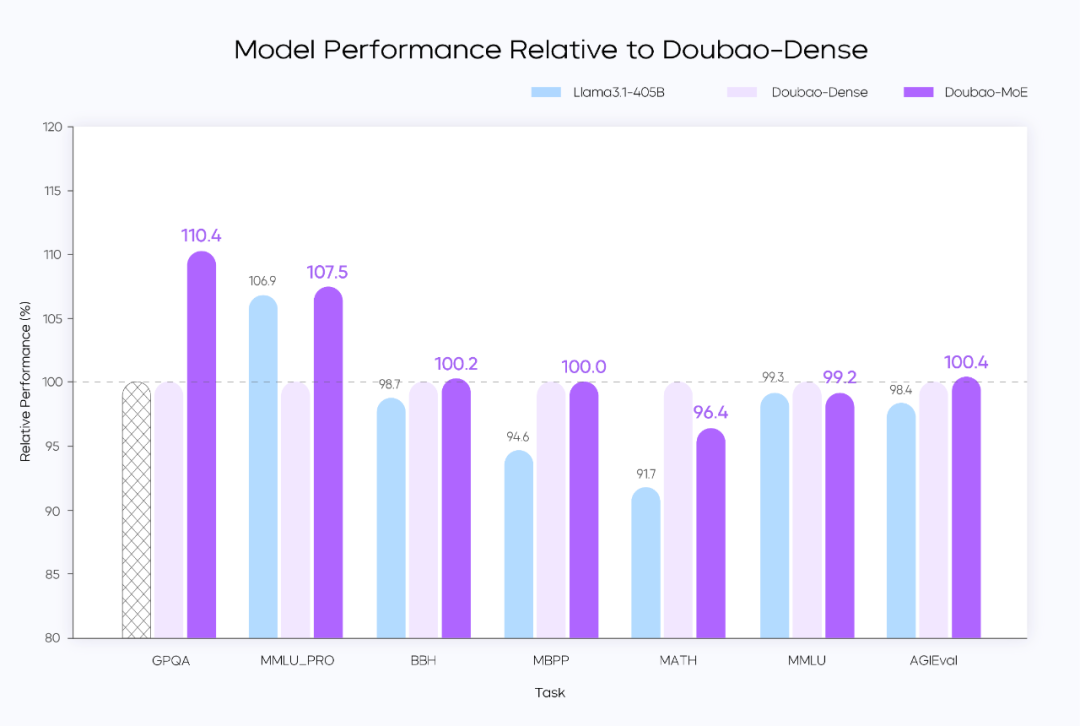
在训练过程上,团队坚持完全独立的数据标注路线,通过算法驱动的数据优化体系以及Verifier和Reward Model的深度融合,建立统一的评估框架。
豆宝选择了最困难但最实用的道路,这也是这次技术突破值得称赞的原因。
据悉,字节研究团队通过高效标注团队与模型自我完善相结合的方式持续优化数据质量,严格遵循内部标准,不使用任何其他模型的数据,保证数据来源的独立性和可靠性。
而且,它突破了RL阶段价值函数训练的难度,将困难任务的性能提升了10个百分点以上,并通过用户反馈闭环不断优化模型性能。这些创新使模型能够在保持高性能的同时显着提高效率。
Doubao-1.5-pro实现了多模态能力的全面升级。通过原生动态分辨率架构,支持百万级分辨率、任意长宽比图像处理,实现精准特征提取。
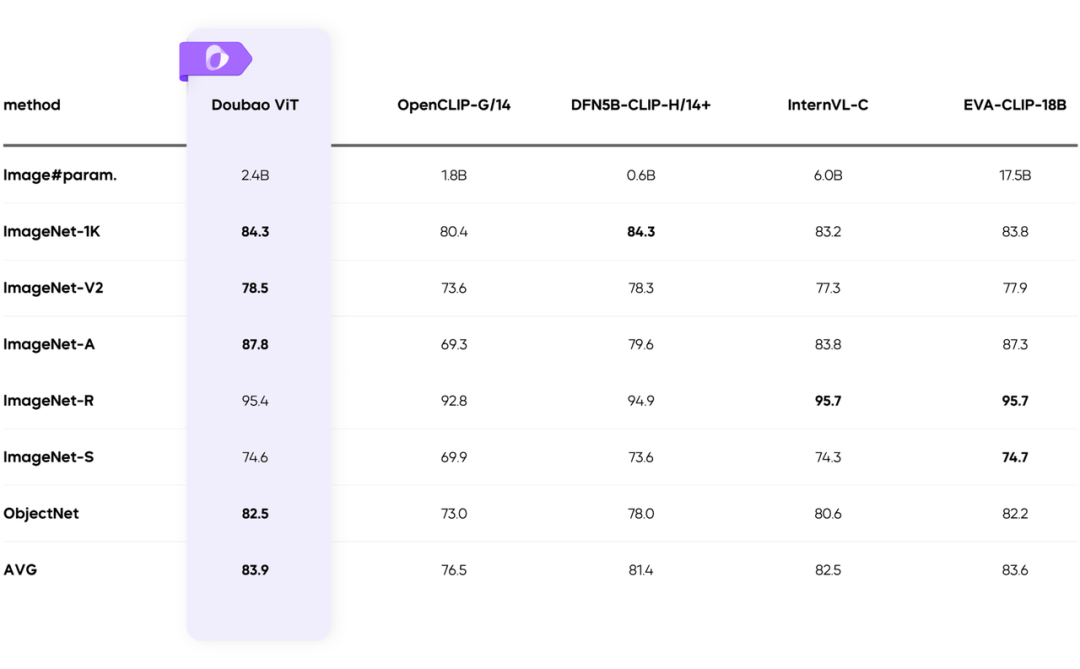
豆宝团队自主研发、支持动态分辨率的豆宝ViT在多种视觉分类任务中表现良好。仅2.4B规模,在综合评分上就实现了SOTA表现,超越了自身规模7倍的模型。
在数据训练方面,模型采用多种合成管道,结合来自搜索引擎、渲染引擎和传统CV模型的图文数据,生成高质量的预训练数据。
通过在VLM训练阶段混合纯文本数据并动态调整学习率,模型实现了视觉和语言能力之间的平衡。

在语音领域,团队创新性地提出了Speech2Speech端到端框架,突破了传统的ASR+LLM+TTS级联模型,深度融合语音和文本模态,显着提升对话效果。
