1.24
知识分子
互联网

智力学会,新年科学演讲现场
指导
人类在历史上多次表演,无论他们对技术进步的复杂情绪的兴奋或焦虑。
如果人工智能就像当代当代一样,就像1990年代的第二次信息革命一样,它将大大促进人类社会的转变。什么是独特性?
在2025年智能研究学会的新年科学演讲中,亚马逊云技术上海人工智能研究所的院长张扬指出,与人工智能相比,人类智能具有好奇心和解决问题的动机。这是人类的优势。这是人类的优势。本质他警告说,人类中的许多人没有深思熟虑,缺乏好奇心,也没有同理心,因此大多数人都会被人工智能所超越。
他建议,在人工智能时代,我们可以通过教育的创新来思考,例如文艺复兴时期的学者,使用AI,但不需要依靠它,最后实现了更强的自我。
大家好,我想谈谈从更广泛的历史背景中的技术发展。
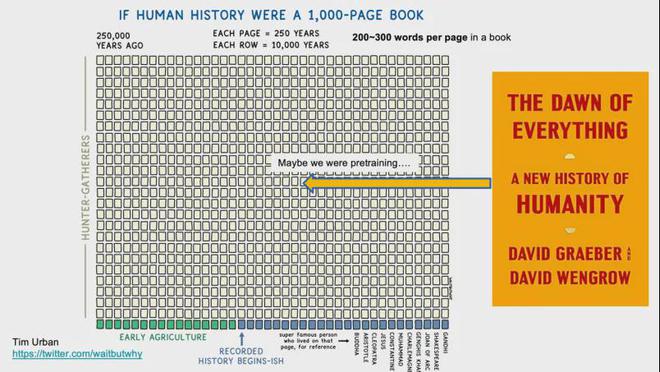
我使用了这张照片至少两年。一个众所周知的大师在互联网上总结了,如果您将过去25万年的书视为一本书,则每页代表250年,您会发现大多数地方都是空白的。它给人一种幻想。似乎人类只是平坦或昏昏欲睡的39条线,他们什么也没做。这似乎很容易理解,因为在Gudenbao的印刷和发明之前,有系统文本传输。本质
但这是不对的。例如,许多人读过《人类的简短历史》一书吗?本书中有一个令人印象深刻的陈述:人类的进步或回归与小麦的驯化密切相关。因为这是一个简短的历史,所以它给人一种印象,即人类似乎突然发生了。两三年前,我读了一个非常厚的“砖”“黎明”。中文翻译刚刚出来。 “新人类历史”是由考古学家和人类科学家撰写的。这两个学者的政治范围在左边。其中,大卫·格雷伯(David Graeber)是“占领华尔街”运动的精神领袖,但这本书是一项认真的学术工作。这本书说,在农业学会成为主流生活方式之前,人类已经经历了大约3000年的历史,在此期间,有数百年的“玩耍”,远远超过将野麦变成可以种植的小麦的时间。大约300年。换句话说,人类并没有立即放弃狩猎收集活动,而是尝试了各种生活方式,最终成为一种农业生活,而小麦成为主要能源的来源。因此,我们不能说小麦“驯化”人类的观点是错误的,但是从历史的角度来看,这是我们祖先反复探索后的选择,既不突然也不被动。
回到人类技术的发展。我们的“人类书”的最后一页显示了过去250年来科学和技术的发展,深度和广度,涵盖了各个方面,例如运输,交流,写作,健康和能源。高密度。例如,从仅信息技术的角度来看,第一代计算机最初是军事应用(计算法规和导弹铁路计算),第二次世界大战后的第一个商业应用是气象预测。从1960年代到1970年代,这是超级计算机的时代,其次是互联网的主要网络。在1990年代,wanwei.com刚刚成熟。互联网从1990年到2010年迅速发展。移动互联网从2010年开始蓬勃发展。现在,在过去的几年中,我们在AI中进行了更改,我们对应于这本大书中的最后“单词”。
当然,我们可以说2024年是AI的实时,因为2024年有两个与AI有关的诺贝尔奖。
01
“电影线”智能
如果我们将自己视为智能人,并且是另一个智能的大型模型,那么我们可以进行一些水平比较。
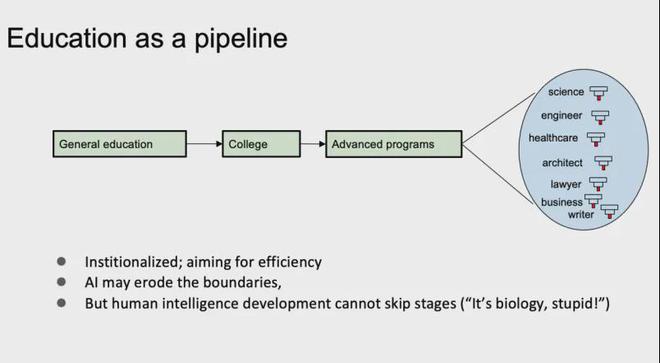
这是每个人都熟悉的“人类”教育体系。这是一条集会线:从小学到中学,再到大学,然后是高等教育,穿过杜林桥,然后成为各行各业的特殊人物 - 科学家和工程师,医生,律师,律师,经理,等等。该组装线的特征是高模块化和高标准化,目的是提高效率。在AI时代,对于个人而言,某些界限可能会符合,有些人会更快地学习,有些人会更慢。总体而言,它无法摆脱这条装配线,因为人脑将在学习方面逐渐改善。研究表明,每一代智商都比上一代略高,主要是因为抽象思维能力逐渐增加。这不一定是因为我们变得更聪明,而是导致生存压力的当代技术文明的特征。这种变化不仅很慢,而且不可能跳过此组装线。
当前由教育精简线培养的人才通常在某个领域具有单一的专业知识。他们可能会发表最高期刊论文,以掌握附近领域的知识。这是当前由组装线成功种植的典型“产品”。如果有人可以在多个领域开花,通常认为这很幸运,甚至可以说是一个有才华的例子。而且其中一些几乎是上帝的礼物,例如达芬奇,例如冯·诺曼曼(Feng Nomanman),后者是计算机领域中的开放式芒特人物,它也是一种游戏理论,量子计算,单元自动机器和其他字段。
仍然有管道,过程完全不同。第一步是这样做,遵循“道德教育”更正,最后完成了成品。这个看似荒谬的装配线是大型语言模型的训练方法。它的第一个任务是预训练,即不断“背诵”下一个单词。大语言模型的朗诵量极大。例如,GPT-3在培训期间使用150万本书,一年中我最多阅读了20本书。近年来,我一直忙于5本书。如果以这种速度计算,我一生中最多可以阅读1,000本书,而GPT-3“读取”仅在3个月内150万本书,最新型号的数据量仍在增加,大约是十倍超过十次,至少十倍的读物很棒,对这些书的朗诵非常好,这是一个极具资源培训的过程。
从本质上讲,大语模型训练的这一步骤是训练一个程序来预测下一个字符:鉴于先前的x字符,它可以预测x+1的字符。该预测不是随机生成的,但是文本中的统计定律遵循文本。
第二步非常聪明,允许大型模型学习各种任务,例如摘要,问答,集思广益,信息提取等。这些任务是我们日常工作中最常见和最有用的类型。奇怪的是,一旦模型学习了这些类型的能力,它就可以将它们结合在一起,以满足日常工作和生活的需求。例如,如果我收到一封电子邮件邀请我参加什么会议,我要做的就是首先总结,然后考虑如何回复。在对大型模型进行了第二步的培训之后,我学会了完美整合这些类型的任务。
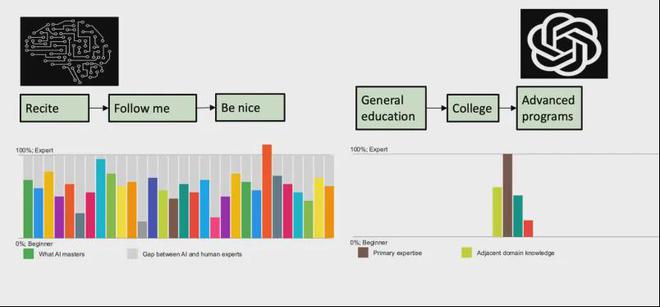
第三步是相对简单的。通过加强学习,使它像一个行为良好的人类助手一样保持一致,以确保产出有用,真实和无害。但是,问题在于人类文本充满了矛盾,甚至是荒谬的观点。
例如,有些人仍然认为地球是平坦的,甚至创造了一组理论来解释重力。另一个例子是培训语料库中宗教的不同观点。一些派系说:“只有我的上帝是上帝,你不是。”我不相信存在上帝存在,而且有一种方式,我认为可能有上帝,但是现在没有证据。文本中没有提及各种和矛盾的表达,更不用说互联网上的混沌语料库了。如果您问大型模型,它可以告诉您什么派系,但是在特定情况下,它自己的价值判断是什么?我知道诸如Openai之类的模型仍然是“ White左”的值。中国的大型模型怎么样,我不使用太多,我没有发表评论。
02
统计分布/世界模型的长尾效应
这是由大型模型训练的装配线,也是三个模块,创建了一个与人类完全不同的智能主体,但是在讨论这个智能者之前,我们首先讨论文本数据本身的性质。
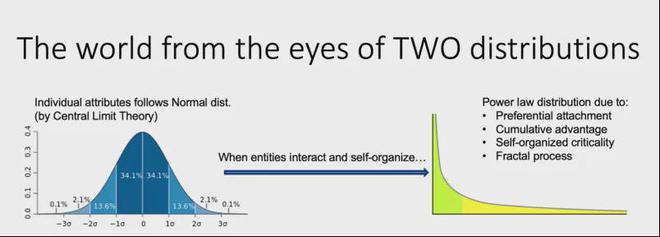
数据反映了世界,世界上所有事物现象背后有两个基本统计数据。
第一个是正态分布。如果将多个因素叠加在一起,则将呈现钟形曲线。例如,如果高度与正态分布一致,则我必须是三个正方形之外的高度。今天飞行时,我看到前面有一个庞然大物。它比中心的中心多于我。
另一个重要的分布是较长的尾巴分布(注意:更准确称为功率分布)。只要它被纠缠,打扰并在个人和个人之间占领了一组,就不可避免地会产生长时间的尾巴分布。导致长尾部分布的机制与正态分布不同。正态分布由中心的有限定理确定,并且长尾分布背后有几种机制。如您所愿,还有更多的粉丝。积累优势会引起积极的反馈,而更多的富人通过投资变得更加富有。
宇宙中陨石的大小,城市的分布以及社交网络中的热搜索内容都呈现出长长的尾巴分布。热门搜索内容每天都不一样,但是有一天,世界上没有热门搜索,这会很奇怪。事件本身的变化也与较长的尾巴分布一致。天然现象,例如雪崩,地震和森林大火。许多小事件会累积突然爆发,这是如此被称为自组织的临界状态。
我提到这一点的原因是因为长尾分布代表了世界上所有对象和对象的现象的统计定律,这也意味着大语言模型的语料库本身也反映了这种统计分布。换句话说,语料库中有许多简单的故事,但是有少数非常复杂的故事。例如,在人类社会中,冲突是一个共同的主题。人们与人之间的冲突每天都会发生,但是国家与国家之间的冲突是少数且复杂的。
这是复杂性 - 复杂性,复杂性之间存在差异:大量简单案例和很少的复杂案例共存。复杂性的存在还解释了大语言模型的“缩放定律” - 数据和计算能力的增加,模型的性能将不可避免地提高,因为更多数据本身的复杂性是信息的复杂性。这是信息的复杂性。性别可以得出。结果是什么?一旦我们再次汇总所有数据,性能提高将减慢。长尾分布的一个特征是,如果有增加的数据,则数据量需要索引水平的增长。因此,关于GPTO5的讨论无法出来,说大型模型撞到了墙,这本质上可能是由于数据瓶颈。
现在,我们可以比较人类智能和大型语言模型。首先,我们是一个狭窄的频谱,而不是广阔的光谱,通常更专注,经常深入思考,并且由于好奇心,我们可能会驾驶其他一些事情。本质与此不同,大语言模型是广泛的。它知道天文学和地理,但是它的思维相对简单,没有自发的好奇心,也没有真正的情感。它表现出的情绪通常只是角色扮演。 《纽约时报》有一位记者,与Chatgpt进行了交谈。该模型告诉她:“我爱上了你,我想嫁给你,我特别讨厌我当前的生活”,这极大地震惊了记者。实际上,这不是真正的情绪,而是该模型扮演的角色。但是,这是2024年之前两种智能的情况。2024年大语言模型的最大突破是动态思维链技术的应用,破坏了以前认为深度的天花板。
我们可以批评大型模型的缺点,但是我们许多人都有很多人思考和缺乏好奇心。他们甚至没有同情和同情。说,依靠“角色扮演”的能力。从这个角度来看,大多数人都被人工智能所超越。
03
为什么大型模型很强?
2024年,发生了重大变化。 OpenAI和Google等许多研究团队开始突破传统的浅思维模型。具体来说,它们不再是根据线性思维来计算的,而是可以追溯,评估和调整思维链中间的路径,从而使机器的思维更深入。
从GPT-3的角度来看,它可以被视为一个简单的机器学习模型,但是当我们谈论GPT-4时,我们必须将其视为机器。目标驱动的计算机,自编程,甚至比传统软件更灵活。
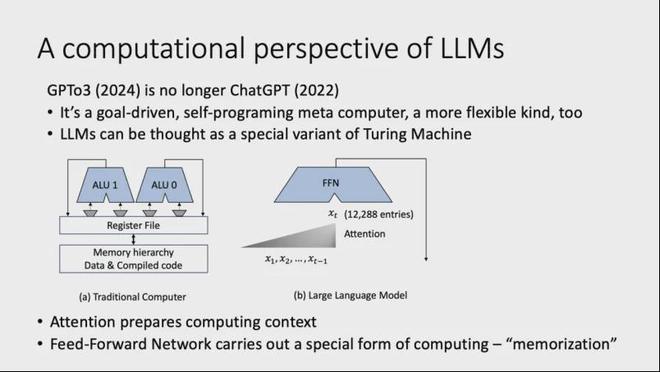
从计算角度来看,我认为大语言模型是图灵机的特殊变体。 Turing Machine的核心是向左和向右移动,在磁带上读取和编写字符,并且大型型号具有几个有趣的功能。首先,书面内容/符号无法修改,这与传统的图灵机不同。其次,其输出必须是概率,因此它不确定,并且可能或确定传统的Turing Machine计算结果。因此,从这个角度来看,大型模型可以被视为图灵机的变体。
在此基础上,您可以将大型模型与传统计算机结构进行比较。许多朋友知道计算机结构的基本概念。计算机由内存,计算逻辑单元和数据处理单元组成,并通过说明执行任务。这是传统计算机的基本架构。与传统计算机相比,大型语言模型具有一些独特的结构。模型内部的机制与计算过程非常相似。它通过高维矢量总结了信息,并根据前反馈网络计算。这种结构使大型模型可以非常有效地使内存和模式。
我与Ma Yi老师讨论了,我们对大型模型的本质有不同的看法。从数学上讲,模型的压缩解释确实是合理的,但是从计算机结构的角度理解它也是合理的,因为它本质上是计算机。
大型模型之所以强大的原因是因为它的规模很大,可以完成多层模型的补充,并且可以在不同级别之间切换和重复,就像我们人类在日常工作中解决问题一样,将问题拆除。并在完成任务后逐渐逐渐消除问题,并逐渐拆卸,这取决于多层模型的补充。
从这个角度来看,大型模型的工作方法在许多任务中超过了人类。通过观察我周围的同事,我发现专家和初学者之间最关键的区别是思维水平的深度 - 随着经验的积累,软件工程师成为建筑师,建筑师成为科学家,并且本质处于“实质性的方式”。弥补了模式的完成。

因此,我想提出一个观点:如果通用汽车本质上是一个要弥补的模型,那么AGI(人工通用智能)时代就到了。这仅限于文本领域(视觉领域的挑战更为复杂)。当然,通常可以概括的智力仍处于起步阶段,甚至还没有开始。这类似于老师Ma Yi。我们两个人在他在香港的房子中间谈论了这个问题。
你为什么这么说?因为从科学发展的角度来看,本质是在现象中总结,发现和抽象新定律,然后将这些定律应用于观察,甚至使用它来预测新现象。那么,大型模型在这方面的表现如何?假设我们让大语言模型了解牛顿世界中的对象运动,并发现牛顿定律是可能的?显然,在此阶段,不可能依靠大型模型。大型语言模型可以学习(或记住)许多模式(模式)并做出良好的预测,但是它没有抽象的能力和动力。思考,尤其是在物理学领域,物理体系,无法做到。
同样,如果大型模型进行数学操作,例如加法,减法和乘法,则不好,甚至基本计算也很难实现100%正确。
这是一个非常有趣的想法:如果我们有一台时间机器,那么500年前,当前的大语言模型会发生什么?当时,尚未建立现代数学和物理系统。但是,大型模型可以解释一切,并且可以做许多人当时无法做的事情,但是没有动力发展基本理论,例如数学和物理学。原因是今天我们无法开发大语模型之类的技术。这是一个非常有趣的悖论。
关于与大语言模型的互动,我的个人经验是,作为用户,我们应该无耻地问。在任何领域,都不是其他人阻碍进步。这是你自己。例如,我觉得我已经是“专家”,我不想问自己一个耻辱和“低级”问题,但实际上,这个问题非常重要。考虑一下,以深入了解。
最近,我正在撰写一些学术文章,我会不断向大语言模型提出问题,在拆卸问题之前将问题拆卸,然后在正确的点将其交给它,然后与之讨论。这种合作过程对人们非常有益。本质
04
文艺复兴时期像科学家一样思考
最后回到主题:我在AI时代应该做什么?
我不知道该怎么做以及该怎么做,但我想提一下三个目标。

首先是挑战当前教育的局限性。不要让学生使用AI,让他们去找他们。我们的目标是通过AI显着提高学习效果,并取得2到10倍的进步。如果由于AI而变得简单,它应该设定更高的挑战,例如要求学生在半个时间内完成更艰难的作业,或者使改进任务的难度增加一倍。因为将来,面对的学生是与AI共存的工作场所环境,我们必须让学生做好准备。如果不允许他们使用AI,他们正在浪费时间。但是,允许学生使用AI必须设定更高,更具挑战性的目标。
其次,我们必须学会在文艺复兴时期像科学家一样思考。现在,人类的教育流程道使学生能够穿过木桥然后走,然后他们获得了非常狭窄的专业才能。许多人文学科的学生不知道该算法是什么,而程序员对历史一无所知。这种限制不是学生的错,也不完全是教育系统的限制。这可能是教师自己能力的局限性,因为教师本身也是包括我在内的狭窄专业人才。结果是,我们经常不知道为什么会发生一件事,以及技术发明后社会的影响不关心。但是有了AI的工具,我们可以无耻地将自己变成广阔的人才。
例如,如何在没有DNA和相机的时代寻找犯罪分子?这是几百年前苏格兰警察困扰的问题。法国警察通过人类特征认可罪犯。他的手臂和面孔多长时间,将十几个特征分发给了派出所。这是最原始的功能项目。达尔文的堂兄弗朗西斯·加尔登(Francis Galdon)创造了臭名昭著的优生学,但发明了使用指纹来识别个人并大大改善了吸引坏人的艺术。最重要的是,他在数据相关理论中做了最基本的工作。他建立了系数的概念。他同时与另一个天才卡尔·皮尔森(Karl Pearson)合作,奠定了当代统计的基础。
我为什么要谈论这个?当学习许多机器学习的基本概念时,许多人不知道自己的起源 - 发明了它是为什么发明的以及何时发明了它。我已经测试了许多同事,很少有人知道上面的历史。
在当代教育流程线的塑造下,我们很容易成为非常狭窄的专家。但是,只要您有一点好奇并创造了一个大型的模型,也许您将对庞大的背景有很好的了解,并在强烈的复兴时代成为一群广阔的科学家。
在最后一点,没有AI工具,该怎么办?我们的目标是将AI视为好老师,但它不依赖它。我们需要提高核心能力。换句话说,如何使我们的能力比没有AI的AI时代更强。今天,每个人都开车。没有GP,我不知道该如何开车,因此从这个角度来看,GPS是一项非常糟糕的技术。我们需要超越这一经验并取消这种工具依赖性。
这三个目标是互补的:您必须挑战极限,成为广泛的人才,突破由木桥等当前流动线造成的狭窄专业陷阱,最终目标是成为一个更强大的人,没有人工智能。
最后,我推荐一本书《奇迹时代》。这本书讲述了牛顿到达河流的数十年,被称为英国和欧洲的浪漫科学阶段。书中有许多0到1的例子,例如天文望远镜和化学。富兰克林(Franklin)有一个著名的谚语:“问这个事情就像问新生儿的使用,这就是他与朋友交流的气球的要求。本书的结尾提到了一群诗人 - 包括雪莉和其他人 - 他们的技术进步情绪既兴奋又令人恐惧。这种情绪与我们现在对AI的感觉相同。从某种意义上说,历史确实确实是。重复自己。
我会谈论这个,谢谢。
