捍卫最后的“人类智慧”之战!
刚才,缩放AI和AI安全中心(CAI)宣布了“人类的ARTHS”的结果!
新基准“人类的最后考试”的全名(称为“ HLM”)包含3,000个问题,这些问题由数百名专家开发,并用于追求人类知识推理的边界。
目前,最佳模型的精度不到10%,并且自信是“开销”。


具体结果如下:

Scale AI和CAI还宣布了相关论文,数据集和测试代码。

项目链接:
网民不欣赏这项工作:


“人类的最后考验”
为了评估AI的进度,已经发布了多个数据集。对于语言模型,根据“带有代码的纸质”网站统计信息,有165个相关的数据集。

但是,当前的基准测试难度并没有保持进度的步伐:LLM可以在一些流行的基准测试(例如MMLU)上达到超过90%的准确率,这限制了对最新LLM功能的有效评估。
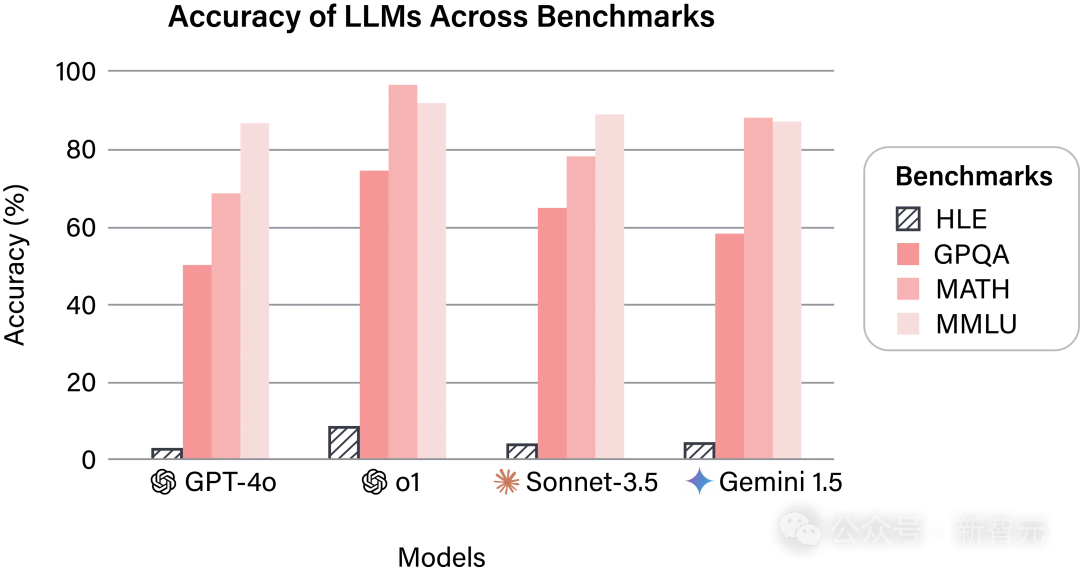
甚至基准也被揭示,并且可能存在某些模型“缺少问题”的问题。
为此,Scale AI和CAIS推出了称为“人类的最后考试”的多模式基准测试,该测试的目的是成为此类封闭的学术基准测试的最终版本,涵盖了广泛的学科。
评估列表
“人类的最后测试”(HLE)包括两种类型的问题:
精确匹配问题:该模型需要输出完全匹配的字符串作为答案。
多项选择问题:该模型需要从五个或更多选项中选择正确的答案。
此外,HLE是多式联运基准测试。其中10%需要了解文本和图像参考。 80%的问题是精确的匹配问题,其余的是选择问题。
该数据集包含3,000个困难问题,涉及100多个学科。
各个学科的分类如下:

图3:HLE高级类别组。
大多数问题已公开发布,同时保留一部分私人测试集用于评估该模型是否过于拟合。
在项目网站上,不同领域/主题中有八个主题,包括化学,物理,数学,计算机科学,语言学等。
例如,常识问题之一:
谁是希腊神话中IO歌曲的祖父?
有关特定问题,请参阅以下图片。
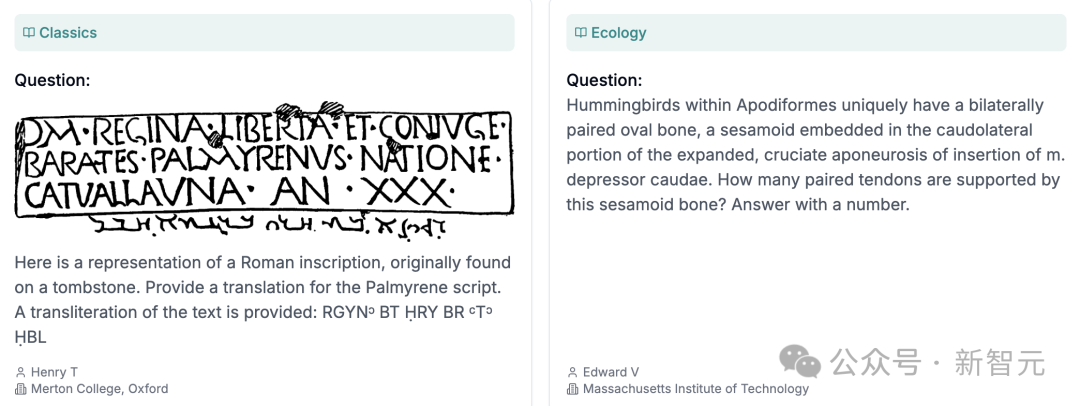


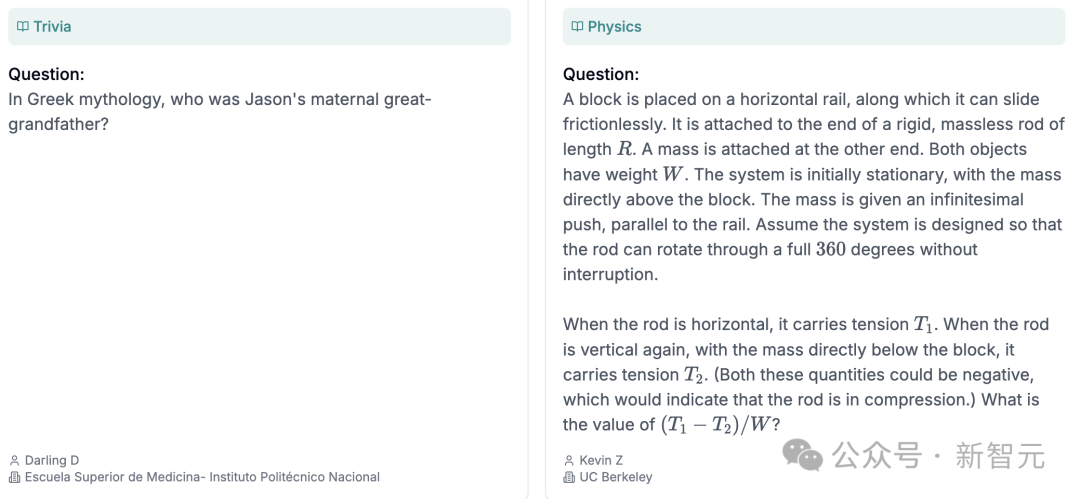
创建过程
为了吸引高质量的问题,HLE设置了500,000美元的奖金池,并提供了以下奖励:
顶级问题奖励:前50期将获得5,000美元的奖金。
高质量问题奖励:接下来的500期将获得500美元的奖金。
此外,由HLE提交的任何人都有机会成为相关论文的合伙人,这激发了许多高级专家的参与,尤其是那些在相关技术领域拥有高度或具有丰富经验的人。
总体而言,收集了70,000多个实验问题,其中选择了13,000个问题以审查人类专家,并最终确定了公共考试中发布的3,000个问题。
近1,000名专家成功提交了这个问题。
它们来自50个国家 /地区的500多家机构,其中大多数是活跃的研究人员或教授。
该问题涵盖了各种格式,包括纯文本和多模式问题,并集成了图像和图表。
为了确保问题的高质量和困难,HLE数据集是通过以下过程创建的:
问题筛查:首先,提交问题,这些问题是特别切割的 - 边缘LLM设计。 LLM通常很难正确回答。
迭代优化:借助专家同行评审,反复修改并优化提交的问题,以提高问题的复杂性和准确性。
手动审查:组织者或由组织者培训的专家手动查看每个问题,以确保该问题符合测试要求。
私人数据集:除了公共数据集外,还保留了一些私人测试集,以评估公开基准测试中模型的过度拟合和可能的作弊行为。
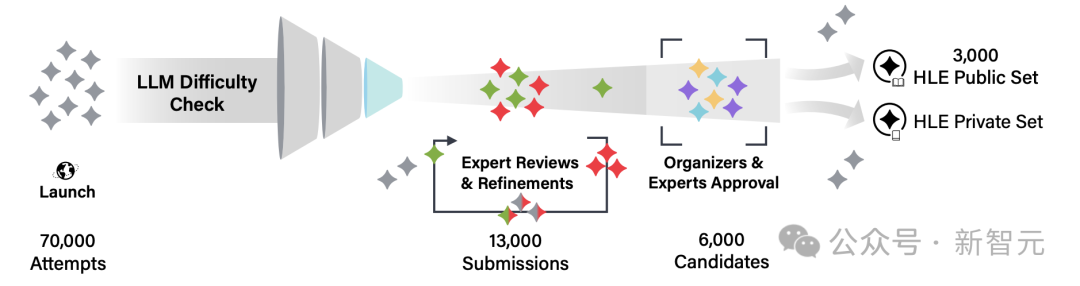
HLE的数据集创建过程
具体结果
研究人员评估了7种模型,包括GPT-40,Grok 2,Claude 3.5 SONNECT,GEMINI 1.5 PRO,GEMINI 2.0 Flash Thinking,O1和DeepSeek-R1。
表1显示,HLE中所有切割模型的精度非常低,并且所有模型的校准性能都很差,反映了较高的RMS校准误差评分。
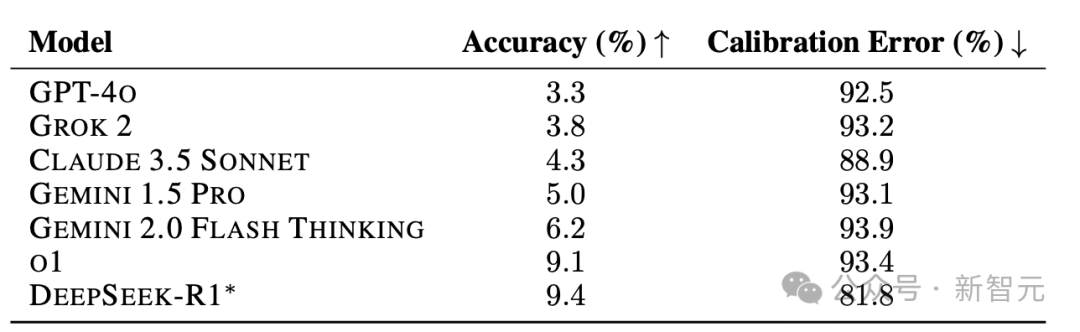
表1:HLE和RMS校准误差上不同模型的精度。
具有推理能力的模型通常需要大量的推理时间和计算资源。
为了更清楚地理解这一点,分析了每个模型生成的完成的数量(完成)令牌。
如图5所示,推理模型Gemini 2.0 Flash Thinking,O1和DeepSeek-R1为了提高性能,需要生成的代币数量远远超过了不合理的模型GPT-40,Grok 2,Claude 2,Claude 2 3.5 Sonnect和Gemini 1.5 Pro(请参见图5中的图片)。
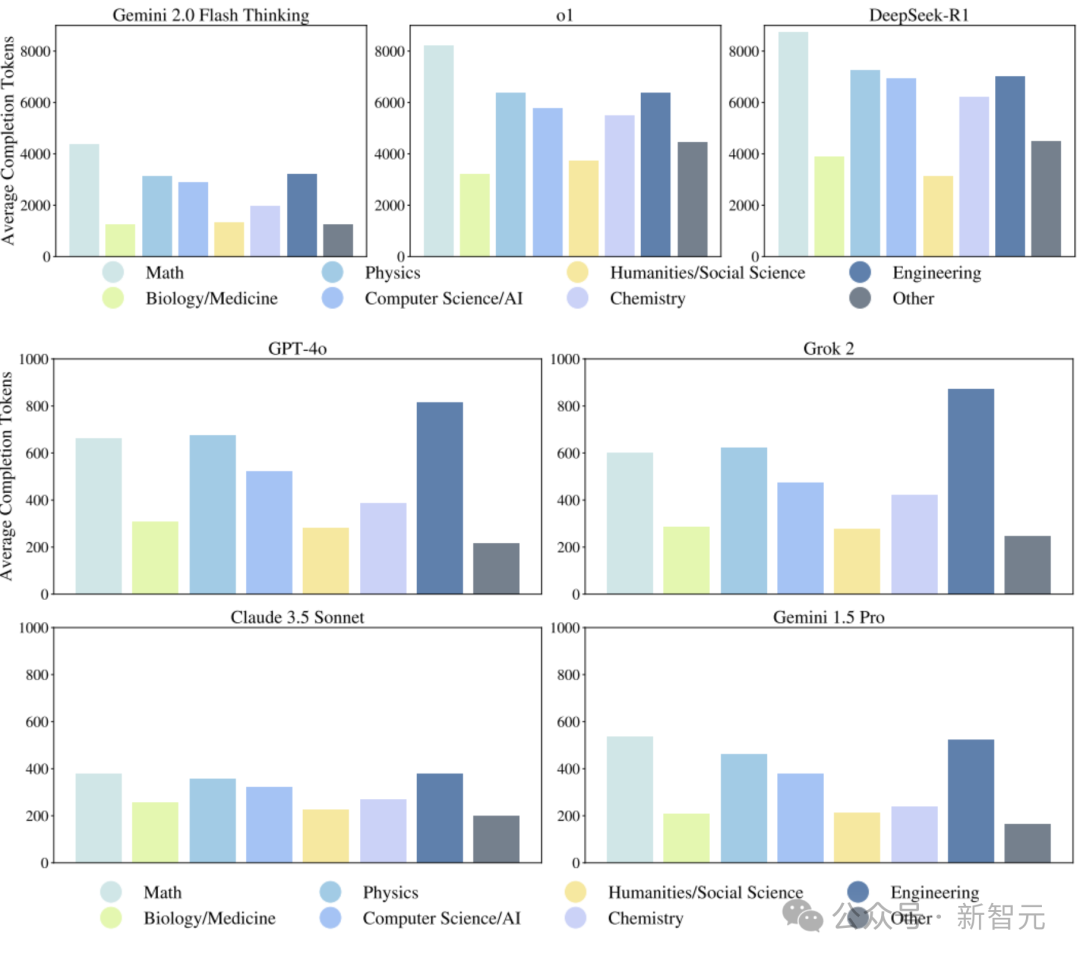
图5:不同模型的平均完成数量
期待未来
在“人类的最后考试(HLE)中,当前的LLM表现仍然很差。
但是,从发展历史的角度来看,基准测试的饱和速度非常快 - 模型通常在短时间内从近0%上升到近100%。
鉴于AI开发的快速速度,在2025年底之前,该模型可能会超过HLE准确性的50%。

AI实验室有一个新列表要刷,渴望尝试
如果该模型在HLE中获得很高的分数,则将指示该模型在封闭的,可验证的问题和切割边缘科学知识中的专家性能。本质
HLE测试结构化的学术问题,而不是开放研究或创造性问题来解决该能力,因此它更多地关注了技术知识和推理能力的衡量。
作者在本文中说:“尽管HLE是该模型的最后一次学术考验,但它远非AI评估的最后基准。”
参考材料:
%20 Ready%20人类的%20last%20EXAM.pdf
