1.25
知识分子
知识分子

来源:pixabay
撰文:张天琪、李珊珊
“meta 的生成人工智能部门陷入了恐慌。这一切都始于 Deepseek,它使得 Llama 4 在基准测试中已经落后。更糟糕的是:这家不知名的中国公司只有 550 万美元的培训预算。工程师们我们正在疯狂地剖析 Deepseek 并试图从中复制一切可能的东西......”
一位 meta 工程师在美国科技公司员工社区 Blind 上写下了这篇文章。
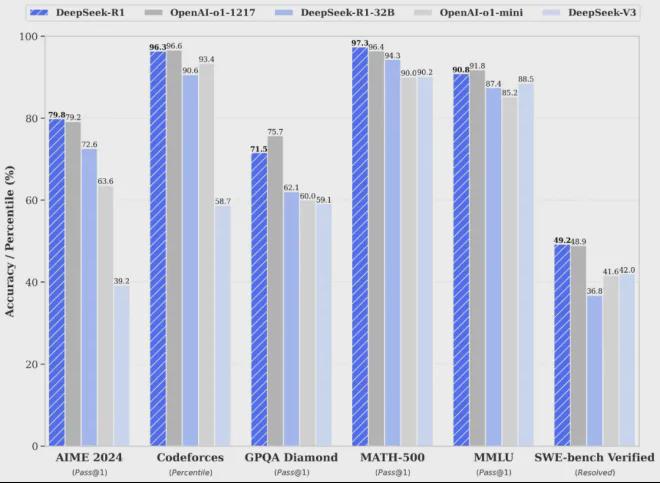
五天前,中国AI大模型创业公司DeepSeek正式发布了DeepSeek-R1大模型。 DeepSeek在发布声明中表示,DeepSeek-R1在数学、编码、自然语言推理等任务上的性能可与OpenAI o1正式版相媲美。此消息震惊全球人工智能圈。
例如,在 AIME 2024 数学基准测试中,DeepSeek-R1 得分为 79.8%,而 OpenAI-o1 得分为 79.2%。在 MATH-500 基准测试中,DeepSeek-R1 得分为 97.3%,而 OpenAI-o1 得分为 96.4%。在编码任务中,DeepSeek-R1超过了人类玩家的96.3%,而o1为96.6%。
01
同样有用,
但成本不到三十分之一
尽管这款来自中国的大型模型的各项指标往往只与国外竞品“持平”,或者最多“稍强”,但其低廉的成本和节省的计算资源仍然让国外同行更具竞争力。 《自然》杂志惊呼:“这太疯狂了,完全出乎意料。”
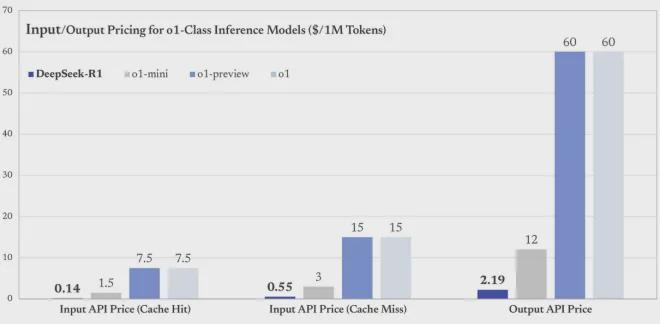
DeepSeek 尚未公布训练 R1 的完整成本,但已公布了 API 的定价,即每百万个输入令牌 1 元(缓存命中)/4 元(缓存未命中),每百万个输出令牌 16 元。这笔费用大约是 OpenAI o1 运营成本的三十分之一。
在低价、高品质的基础上,DeepSeek-R1还实现了部分开源。官方声明同步开源了模型权重,让研究人员和开发者可以在自己的项目中自由使用该模型,或者基于该模型进行进一步的研发。 DeepSeek-R1系列支持商业用途,允许用户对模型进行任何形式的修改和衍生创作。同时,DeepSeek-R1向用户开放了思维链输出,这意味着我们可以直接看到它的“思维”过程以文本形式输出。
去年12月底,DeepSeek发布了DeepSeek-V3,引起了AI圈的震动。其性能与GPT-4o和Claude Sonnet 3.5等顶级模型相似,但训练成本极低。整个训练在2048个NVIDIA H800 GPU集群上完成,成本仅约557.6万美元,不到训练其他顶级模型成本的十分之一。
GPT-4o等模型的训练成本约为1亿美元。它在至少10,000个GPU的计算集群上进行训练,并使用性能优越的H100 GPU。例如,去年发布的同为顶级大型模型的 Llama 3.1 在训练过程中使用了 16,384 个 H100 GPU,消耗的计算资源是 DeepSeek-V3 的 11 倍,成本超过 6000 万美元。
随着大模型的竞争越来越激烈,去年OpenAI、meta、谷歌和马斯克的xAI,各大AI巨头都开始搭建自己的万卡(GPU)集群。万卡集群似乎已经成为训练顶级大型模型的最佳方式。入场券。然而,DeepSeek只用了不到十分之一的资源就创建了性能相似的大型模型,这让习惯了资源竞争的硅谷AI行业人士感到惊讶。
DeepSeek-V3发布后,NVIDIA高级研究科学家Jim Fan曾在社交媒体上表示“DeepSeek是今年开源大语言模型领域最大的黑马[1]”。
硅谷人工智能数据服务公司Scale AI创始人Alexander Wang在社交媒体上直言不讳地表达了对中国科技界追赶美国的担忧。他认为DeepSeek-V3的发布是中国科技界给美国的惨痛教训。 “当美国在休息时,中国(科技界)正在努力,以更低的成本、更快的速度和更强的实力迎头赶上。”
今年年初DeepSeek-R1发布后,硅谷技术界的评价还是很高的。 Alexander Wang 认为,“我们发现 DeepSeek... 是表现最好的,或者大致相当于美国最好的模型。这个领域的竞争越来越激烈,而不是更少[2]”。
Jim Fan的评价更进一步,他甚至讨论了DeepSeek“接班”OpenAI的话题。与依靠闭源构建护城河的 OpenAI 相比,他在社交网站上表示,“我们生活在一个非美国公司正在维护 OpenAI 最初使命的时间线——真正开放、前沿的研究,为每个人赋能。这可能看起来不合逻辑,但最有趣的结果往往是最容易发生的[3]”。
基准测试的分数可能并不能完全代表大型模型的真实能力,科学家们对R1的能力更加谨慎。目前,科学家们已经开始对R1进行更深入的测试。
德国埃尔兰根马克斯·普朗克光学研究所人工智能科学家实验室负责人 Mario Kron 要求 OpenAI o1 和 DeepSeek-R1 这两个竞争模型按照兴趣程度对 3000 个研究想法进行排名。结果与人类排名进行了比较。在这个评价标准上,R1 的表现比 o1 稍差。然而,她指出,在某些量子光学计算任务中,R1 的表现优于 o1 [4]。
02
不走寻常路
引起AI圈好奇的不仅仅是DeepSeek-R1的性能和低成本,还有技术论文中展示的DeepSeek团队在AI训练方法上的新尝试。
在提高推理能力时,以前的模型通常依赖于监督微调(SFT)。在监督微调阶段,研究人员将使用大量标记数据来进一步训练预训练的AI模型。数据包含问题及其相应的正确答案,以及如何构建思维步骤的示例。依靠这些模仿人类思维的“例子”和“答案”,大模型可以提高推理能力。
DeepSeek-R1训练过程中的DeepSeek-R1-Zero路线直接将强化学习(RL)应用到基础模型上。他们的目标是探索大型模型如何在没有任何监督数据的情况下通过纯粹的强化学习过程进行自我进化,从而获得推理能力。
该团队制定了两个简单的奖励规则。一是准确率加分,答对了加分,答错了扣分。另一个是格式要求。模型必须在标签之间写出思维过程,类似于我们必须在考试的答案框中写下答案。不再依赖“例子”,而是让“学生”AI以自己的方式学习推理。
从基准测试结果来看,DeepSeek-R1-Zero无需任何监督微调数据即可实现强大的推理能力。在AIME 2024基准测试中,DeepSeek-R1-Zero在使用多数投票机制时取得了86.7%的准确率,高于OpenAI o1。
在训练 OpenAI o1 级别的推理模型的任务上,DeepSeek-R1 是第一个证明该方法有效性的直接强化学习模型。
艾伦人工智能研究所的研究科学家 Nathan Lambert 在社交媒体上表示,R1 的论文“是推理模型不确定性研究的一个重要转折点”,因为“到目前为止,推理模型一直是推理模型的重要领域”工业研究,但缺乏开创性论文 [5]。”
中山大学集成电路学院助理教授王美琪解释说,直接强化学习方法是与一系列工程优化技术(如简化奖励和惩罚模型设计等)结合起来的。 DeepSeek团队进行多版本模型迭代,有效降低了大模型的训练成本。直接强化学习避免了大量的人工数据标注工作,同时奖励和惩罚模型的简化设计减少了对计算资源的需求。
DeepSeek-R1的结果表明,大规模应用直接强化学习,而不是依赖于大型模型的经典训练范式(例如使用预设的思想链模板和监督微调)是可行的。这为大型模型训练提供了更高效的思路,有望激发更多研究人员和工程师朝这个方向进行重现和探索。 DeepSeek还将模型开源并提供了详细的技术报告,这也帮助其他人快速验证和扩展该方法。
“从核心原理来看,DeepSeek的大部分训练技术都可以追溯到AI的发展过程,但它所揭示的直接强化学习的巨大潜力,以及训练过程中自我反思和探索行为的出现,对于模型的高效训练乃至人类学习模型的探索都有着很大的启示。”王美琪表示。
03
这个大模型能为中国人工智能产业带来什么?
关于 DeepSeek,《Nature》指出,尽管美国出口管制限制这家中国公司获得用于人工智能处理的最佳计算机芯片,但它还是成功构建了(DeepSeek 的)R1。
在硅谷,人们将这种大算力节能的中国模式称为“来自东方的神秘力量”。从《纽约时报》到《连线》、《福布斯》,几乎所有媒体都在说:美国痴迷于先进半导体。出口管制的目的是减缓中国人工智能的发展,但可能会无意中刺激创新。 ”
那么,如此大的节省算力的模型会成为中国解决AI芯片禁运的方案吗?
一位人工智能领域的专家告诉《知识分子》:最终,“我们还是需要安装芯片。”
计算能力的困境仍然存在。不过,如此计算效率极高的大型模型的出现,仍然给中国的大型模型带来了新的希望——除了计算能力,我们还可以依靠优化。正如《自然》杂志援引华盛顿西雅图人工智能研究员弗朗索瓦·乔莱(François Chollet)的评论:“这一事实表明,资源的有效利用比纯粹的计算规模更重要。”
《福布斯》指出,它让世界认识到“中国并没有退出这场(人工智能)竞争”。
这个来自中国的大模型让人们看到了架构和算法方面优化的潜力。它几乎以一己之力扭转了全球大模型领域对算力的疯狂追求,给无数小公司带来了新的机遇。 。
《自然》杂志称,DeepSeek的V3训练成本不到600万美元,而meta则花费超过6000万美元训练其最新人工智能模型Llama 3.1 405B。 《纽约时报》称:“有600万美元。融资1亿美元或10亿美元的公司远远多于融资1亿美元的公司。”
除了效率之外,DeepSeek另一个经常被人称赞的亮点就是它的开源。在 Reddit 上,人们称赞 DeepSeek“开源,可以本地运行”,“我必须下载一个到我的电脑上”。
开源,这意味着这种模式的开发者不仅会与自己的同事合作,他们“实际上与世界上最好的同事合作”,《纽约时报》称,“如果最好的开源技术来自中国,美国开发商将在这些技术的基础上构建他们的系统,这可能使中国成为人工智能的研发中心。”
当然,引领整个生态系统是遥远的未来。开源,更直接、看得见的影响是:“一个开源且易于使用的AI将迅速占领学术界”,前述人工智能相关专家对《知识分子》表示。
参考:
;1]自然出版集团。 (2025)。中国廉价、开放的人工智能模型 DeepSeek 让科学家们兴奋不已。自然。
[2]Jiang, B. (2025年1月13日)。 DeepSeek:这家中国初创公司正在改变人工智能模型的训练方式。南华早报。
[3]Field, H.(2025 年,1 月 23 日)。 Scale AI首席执行官表示,中国凭借DeepSeek开源模型很快赶上了美国。美国全国广播公司财经频道。
[4]自然出版集团。 (2025b)。中国廉价、开放的人工智能模型 DeepSeek 让科学家们兴奋不已。自然。
[5]Chowdhury, H.(2025 年,1 月 22 日)。一家中国初创公司刚刚向所有美国科技公司展示了它在人工智能领域的追赶速度。商业内幕。
