封面记者Bian Xue
农历新年的钟声尚未听起来,人工智能领域已经迎来了新年礼物包装中的AI初创公司DeepSeek发行了其最新的理由大型模型DeepSeek-R1。
这是DeepSeek在短短一个月内发布的第二个大型模型,也就是仅次于DeepSeek-V3。凭借极高的计算效率,出色的性能和极低的开发成本,它已成功地在国际AI领域引发了波浪。本质
DeepSeek-R1的投入定价为0.55美元/百万美元(OpenAI为15/百万美元),输出令牌为2.19美元/百万美元(OpenAI为60/百万美元),降低了90%以上。以前,DeepSeek -V3在研发成本和2,000张图形卡中仅使用了550万元人民币,但其性能与Llama 3 405B相当,Openai花费了数亿美元来实现这一目标。
DeepSeek的最新版本不仅显示了中国人工智能技术的实力,而且还重新定义了该行业的竞争规则:DeepSeek-R1发行后,外国媒体专注于DeepSeek,他们同意中国大型模型的新进展听起来很警报。硅谷的时钟。 :图灵赢家詹恩·莱肯(Jann Lecun)评论说,DeepSeek验证了“开源模型已超过封闭的源系统”。
性能与肩部Openai O1相当
开源和低成本颠覆行业
封面新闻记者注意到,DeepSeek-R1首先通过纯粹的强化学习实现了推理能力的突破(无需监督微调SFT)。 DeepSeek-R1-Zero的实验版本直接在基本模型上应用RL培训,并成功地达到了与数学和编程任务的人类专家接近的水平。例如,它在美国数学邀请赛(AIME 2024)中的准确性从最初的15.6%跃升至71%,最终通过多个阶段提高到86.7%,这相当于OpenAI O1-0912。
该模型显示了类似于训练中人类的“反思”行为,例如积极暂停推理,重新评估问题的步骤和探索替代方案。自发的“顿悟时刻”被认为是增强学习能力而不是人工编程的自然出现。
DeepSeek-V3模型使用接口。
值得注意的是,团队开发的群体政策优化算法放弃了传统的评论家网络,并通过小组的相对优势估算了优化策略,以显着降低计算成本。奖励机制结合了准确性,格式和语言的一致性,以确保推理过程结构并符合人类习惯。
DeepSeek-R1型号的权重和培训细节完全公开。 MIT方案用于允许商业和二级发展。从这个角度来看,这不仅是中国对中国AI技术独立创新的里程碑,而且还通过开源和低成本策略促进了全球AI生态系统开放性。 ,进化进化。
正如周·洪吉(Zhou Hongyi)所说的那样,“中国模特技术复仇者联盟”(Avengers)悄悄地形成了,DeepSeek正成为反对技术霸权的关键力量。
技术的新基准:DeepSeek-V3的三个创新
DeepSeek-V3是DeepSeek系列中的最新迭代版本。这是一种基于专家(MOE)体系结构的混合物(中国模型的兴起:Minimax-text-01领导AI创新趋势)的高级语言模型。该型号具有671亿个气孔,每个代币将激活37亿个参数,因此在处理自然语言处理(NLP)到计算机视觉时,它显示出其出色的能力。
DeepSeek-V3的重要优点是它可以处理较大的数据集,在各种任务中显示更强的概括功能,并提供更快的推理时间。与竞争对手相比,小额计算足迹。在成功的背后,它与三个核心建筑创新密不可分。尽管这些技术突破了成本,但它们会大大提高其性能,并为该行业树立新的基准。
首先,多层注意力(MLA)技术解决了长文本推理的高成本问题。传统模型在处理长文本时通常会消耗巨大的计算能力,而DeepSeek团队通过潜在的功率机制优化了模型信息的捕获效率,并大大降低了长文本推理的计算成本。该技术不仅增强了模型理解复杂环境的能力,而且还使其在实际应用中更稳定和有效。
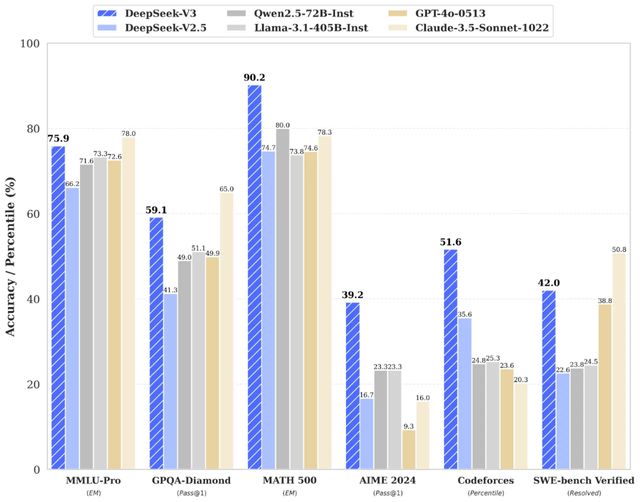
DeepSeek-V3测试结果首先。
其次,专家(MOE)技术混合的改进已经克服了困扰该行业的长期路由崩溃。在传统的MOE体系结构的高持续任务中,一些路由节点容易过多,这会影响模型性能。 DeepSeek团队通过创新的路由算法优化了任务分配机制,从而显着提高了训练效率和系统稳定性。
一些海外网民比较了Openai发布的“ DeepSeek-V3”和“ GPT-4O”,并得出结论,“两种产品是可比的”结论。硅谷的技术Daniel还使用“ DeepSeek-V3”来尝试选择一些问题,但要捡起它并选择它,并且只能使用“令人难以置信的”来总结一下心情。
“ DeepSeek-V3超过了性能中的其他开源模型,并且可以与主流封闭的源模型相媲美。它创新地使用MTP目标将预测范围扩展到每个位置的多个后续令牌。” 1月26日26日,行业内部人士告诉封面记者,DeepSeek-V3可以适合科学研究,企业,开发人员和AI爱好者,尤其是在逻辑推理,代码生成,文本生成,数学计算以及多语言处理中。
从一无所有:DeepSeek的兴起
DeepSeek的快速崛起与团队的技术积累和准确的战略布局密不可分。这家中国公司于2023年成立,旨在挑战全球AI巨头。成为行业先驱只花了不到2年的时间。既有技术创新支持,也有成功的业务策略。
外界认为DeepSeek非常神秘,其创始人Liang Wenfeng很少对外界讲话,但总是经常搜索。
DeepSeek的名声是它发布了DeepSeek V2开源模型,该模型以前所未有的成本业绩震惊了该行业。推理成本降低至百万元即百分百令牌。这一成本仅为Llama3 70B的1-7,而GPT-4涡轮增压的1-70。这项创新不仅允许DeepSeek获得“ AI战斗Duoduo”的头衔,还促使大型制造商(例如Bytes,Tencent,Baidu,Ali,Ali和其他大型制造商)等大型制造商,这在中国大型模型市场中引起了价格战。
2025年初,Liang Wenfeng出现在“新闻广播”中,参加了AI Startup DeepSeek的创始人,并在现场演讲。
最近,“ Lei Jun的1000万年薪水和95个AI Girls AI Girls”的热门话题与Liang Wenfeng也间接相关:这个AI Genius Girl Luo Fuli以前是DeepSeek团队的成员。
值得一提的是,DeepSeek总是遵守“最佳资源”策略。与OpenAI等数亿美元的投资相比,DeepSeek在研发方面仅使用100万个水平,但仍创造国际竞争力。大型模型。通过对计算能力的精致管理和资源有效分配,该团队证明了中国人工智能公司在技术研发中的独特优势。
在业务层面上,DeepSeek的成功与其敏锐的市场见解是不可分割的。该公司准确地将中小型企业推向市场,以使计算能力敏感,从而为客户提供具有成本效益的AI解决方案。 1月25日,AMD宣布,新的DeepSeek-V3模型已集成到本能MI300X GPU上,该MI300X GPU旨在通过Sglang取得最佳性能。 DeepSeek-V3优化了AL推理。
如何重塑AI比赛模式
近年来,LLM经历了快速的迭代和进化,并通过通用人工智能(AGI)逐渐缩小了差距。 2024年,斯坦福大学和Epoch AI的研究人员发表了一项研究,称到2027年,最大模型的培训成本将超过10亿美元。但是,DeepSeek以非常低的价格建立了突破性的AI模型。尽管绩效突破,但它还显示出高度的资源利用效率,在全球AI技术领域中引发了“有效的革命”。
最近,投资者Geiger Capital在社交平台上发布说:“ DeepSeek和Openai一样好,甚至更好,价格仅占后者的3%……纳斯达克会怎样?”
封面记者注意到,在DeepSeek-R1发行后,市场情绪已经做出反应。 1月24日,NVIDIA的股价据报道为142.62美元,下跌3.12%,市场价值蒸发为1,127亿美元(约8165亿元)。
在中国的大型创业公司中,DeepSeek逐渐以低调和高效的姿势出现在AI领域。该公司不仅取得了技术突破,而且在商业模式中引起了行业的价格战,并成为中国人工智能行业不容忽视的一支部队。
许多行业内部人士告诉封面记者,DeepSeek的低成本和高性能策略将对行业的竞争模式产生深远的影响。一家国内AI初创公司的创始人直言不讳地说:“ DeepSeek通过最小的资源实现了最高效率,并显示了向全球公司有效的研究和发展的可能性。该模型的成功可能会迫使行业的传统概念。”
“ DeepSeek的目标是实现AGI(人为地普遍的智能),而不仅仅是短期商业化。” Liang Wenfeng曾经在采访中强调,DeepSeek的价格降低不是吸引用户,而是基于成本下降和追求包容性AI AI的本质,他认为,随着经济发展的发展,中国也应该成为技术创新的贡献者只是应用创新的关注者。
在加强全球AI竞争的背景下,DeepSeek不仅对行业的日常活动提出了挑战,而且为中国人工智能的未来发展提供了新的想法和方向。其低成本和有效的研发路径为技术创新的技术创新提供了新的参考。该方向还向世界展示了中国人工智能公司的潜力和决心。
也许“搅动”硅谷只是一个开始。
