DeepSeek上周发布了开源DeepSeek-R1,并表示,在模型的Performance Benchmark Openai O1的正式版本之后,海外AI行业对模型的讨论继续进行。
热门讨论的重点是,当开源模型赶上最新封闭源模型的能力可能会改变大型模型的竞争模式时。
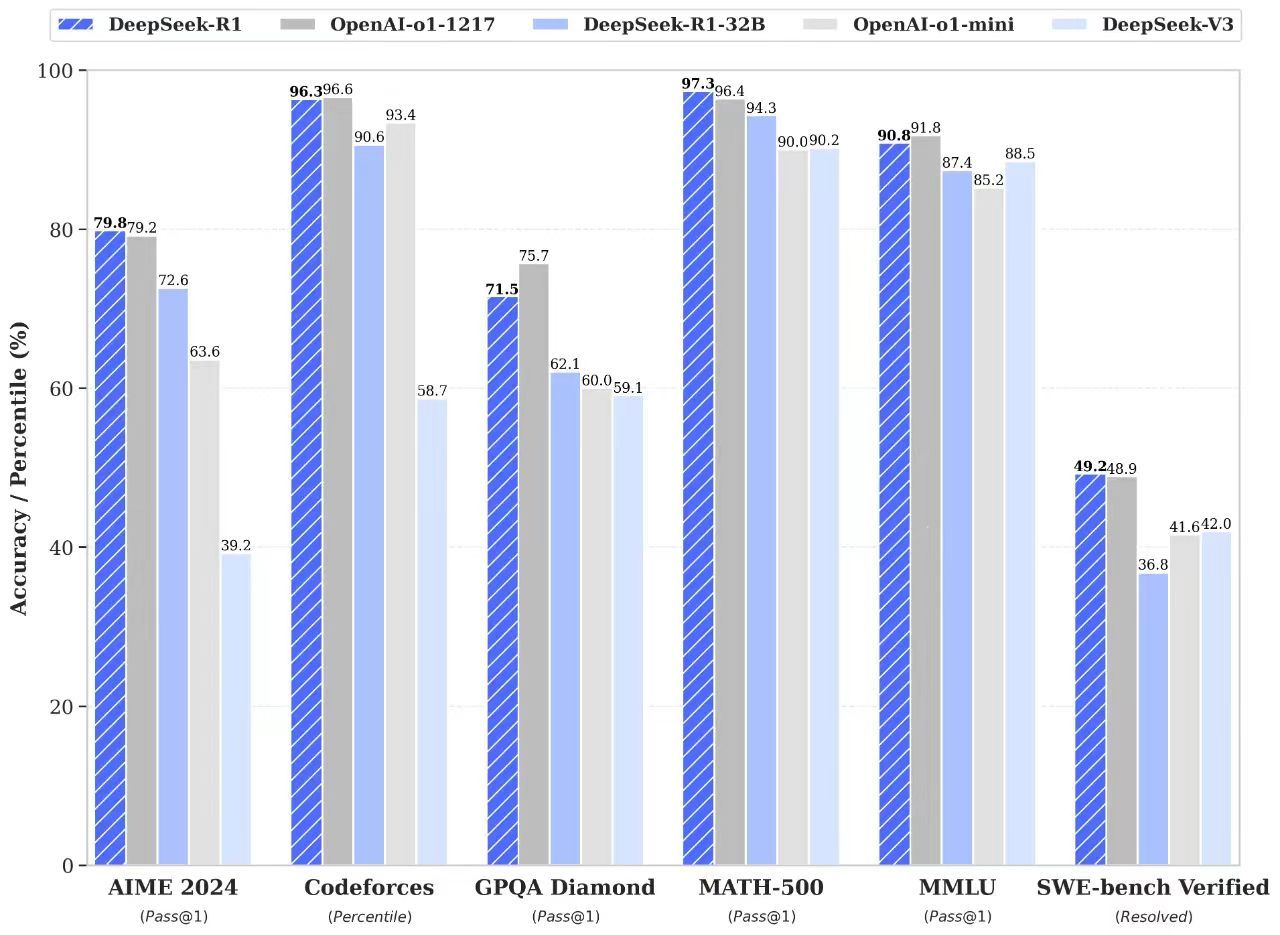
根据DeepSeek的说法,DeepSeek-R1靠近Codeforcess,GPQA Diamond,Math-500,MMLU,SWE-Bench验证等的O1的官方版本,并且某些测试分数超过了O1的官方版本。该模型在后培训阶段使用大型增强的学习技术,在很少标记数据时,可以增强模型推理能力。
AI行业的人们已经在讨论开源的影响。 meta的首席AI科学家Yann Lecun说,DeepSeek-R1的外观意味着中国公司正在AI领域超过美国公司。 “ DeepSeek将从开源研究和开源中获利,这可能与meta的Pytorch和Llama相似。他们提出了新的想法并根据他人的基础实现他们。由于他们的工作是开放和开源的,所以每个人都可以从中。利润,这是开放式研究的力量。
“我们生活在这样一个时代。一家非美国公司允许Openai的最初意图继续,也就是说,这是一项真正的开放和赋予所有人权力的尖端研究。”一个显示RL(增强学习)飞轮的OSS(开源软件)项目可以发挥作用并带来可持续增长。加利福尼亚大学教授亚历克斯·迪马基斯(Alex DiMakis)说,DeepSeek似乎是OpenAI最初任务的“最佳候选人”,其他公司需要赶上。
Silicon Valley Venture Capital A16Z的创始人Marc Andreessen还评论说,DeepSeek-R1是他见过的最令人惊叹,最令人印象深刻的突破。作为开源模型,它将礼物带给世界给世界的礼物。本质
与也采用开源路线的meta相比,Sina Weibo的新技术研发负责人张Junlin说,DeepSeek和Ali已将meta带入了开源。国内开源氛围越来越好。这是由DeepSeek和Ali驱动的。多亏了DeepSeek开源的许多R1版本模型,该行业可以以低成本的逻辑推理功能快速复制模型。
用户可以在自己的服务器上部署开源模型,也可以使用云计算能力,并使用自己的数据来罚款大型模型。就数据安全性而言,开源模型的使用可能比大型模型的API接口更好。制造商支付API电话。当大型开源型号的容量超过或大型肩部闭合来源时,开源将对封闭来源产生影响。
在启动DeepSeep-R1之前,开源场中的基准是meta的Llama系列模型。 Minimax副总裁Liu Hua承认,在接受第一名财务记者的采访中,它比开源模式更好。在这一点上,您可以变成AI应用程序。中国商业化最基本的先决条件之一比meta的Llama模型更好。 “否则,其他人可以使用美洲驼,为什么您要与模型一起花钱?这是非常现实的。”
DeepSeek是幻想形成下的AI公司。幻想量化的创始人Liang Wenfeng成立于2023年,在定量投资和高性能计算领域具有深厚的背景。该公司采用了开源和成本效益的路线,也被称为“ AI Fighting Duoduo”。去年5月,DeepSeek发行了DeepSeek-V2,价格几乎是GPT-4-Turbo的百分之一,这发起了大型Model Price War的先驱。这次发布的DeepSeek-R1还提供了API调用方法。 API输入(缓存命中),输出定价为百万Tokens1云,6元,小于55元和438元的O1。去年12月,DeepSeek还发布了一款大型DeepSeek-V3,由于“ 2048 GPU,2个月,近600万美元”引起了人们的关注。
但是,从最新消息中,DeepSeek的产品更新并没有改变在大型模型中投资大量资金和大型计算能力基础设施的做法。最近,OpenAI,Oracle和Softbank宣布将建立合资企业“ Star Program”。它计划在未来四年内投资多达5000亿美元,以建立与AI相关的基础设施。相当。
1月24日,当地时间,元首席执行官扎克伯格说,为了在AI领域实现该公司的目标,该公司正在建立一个2 Givava或以上的数据中心,涵盖了“大部分地区该公司预计到今年年底将拥有130万个GPU,今年的资本支出将达到60至650亿美元。
