DeepSeek的压力终于传给了Huang Renxun。
1月27日晚上,北京时间,NVIDIA的股价在市场前近11%。基于当前的34928亿美元的市场价值,NVIDIA的市场价值可能会缩小超过3500亿美元。
DeepSeek设定的低成本模型培训策略使资本市场怀疑,当相对较小的计算能力也可以实现模型的性能而不会丢失OpenAI时,无论是由NVIDIA代表的高端计算能力芯片在迎来新的泡沫中?
这种担忧进一步有助于DeepSeek的普及。在1月27日,DeepSeek应用程序在短短的一周内就利用了新的DeepSeek R1版本发布,赢得了美国应用商店的两个顶部和中国应用商店的免费列表。
值得一提的是,这是AI助理产品第一次超越Openai以超越Openai,并登上American App Store。
大火的用户体验场景直接导致两天内的DeepSeek停机时间。 1月26日(1月27日)短期闪光灯崩溃之后,DeepSeek再次短暂出现在网络/API上的服务提示。官方回应指出,这可能与服务维护和请求限制等因素有关。
新型DeepSeek R1无疑是一种直接的保险丝,触发了围绕DeepSeek的全球用户讨论。 1月20日,DeepSeek正式发布了完整版Openai O1的完整版本。
数据越多,效果越好,缩放定律(模型尺度的定律)就越达到瓶颈。去年9月,OpenAI发布了新的推理模型O1。该行业被认为是大型模型领域中的“范式转移”。
但是,在DeepSeek R1发布之前,许多国内模型制造商还没有推出可以针对OpenAi O1的模型。 DeepSeek成为第一个打破OpenAI技术黑匣子的玩家。
更重要的是,与该模型上的OpenAI的封闭来源以及O1模型付款使用情况的限制相比,DeepSeek R1不仅是开源的,而且还没有对全球用户的无限呼叫。
R1的出现除了打破旗舰开源模型外,还只能在行业中达成传统共识来促进该行业,但也打破了去年该行业的另一种共识。资本竞争游戏。 DeepSeek没有使用OpenAI的第十一个资源,而是使R1与O1相当。
DeepSeek带来的影响使一些大型制造商无法坐下。
第一个是元。梅塔(meta)一直被该行业视为“大型模特之王”,他开始担心尚未发布的骆驼4,并且可能无法追赶DeepSeek R1的性能。

我被习惯于完全针对Openai,并开始感到压力。 Openai首席执行官Ultraman不仅发布了第一个智能机构运营商的知名度,而且还开始了外国戏剧的新闻,以便上网。
可以预见的是,DeepSeek引发的行业地震不仅会影响外国公司,而且国内大型制造商也很难逃脱例外。
作为开源模型,DeepSeek R1在数学,代码,自然语言推理和其他任务中的性能,声称是Weepenai O1模型的官方版本。
在AIME 2024数学基准测试中,DeepSeek R1评分率为79.8%,OpenAI O1的评分率为79.2%;在Math-500基准测试中,DeepSeek R1得分率为97.3%,OpenAI O1的得分率为96.4%。
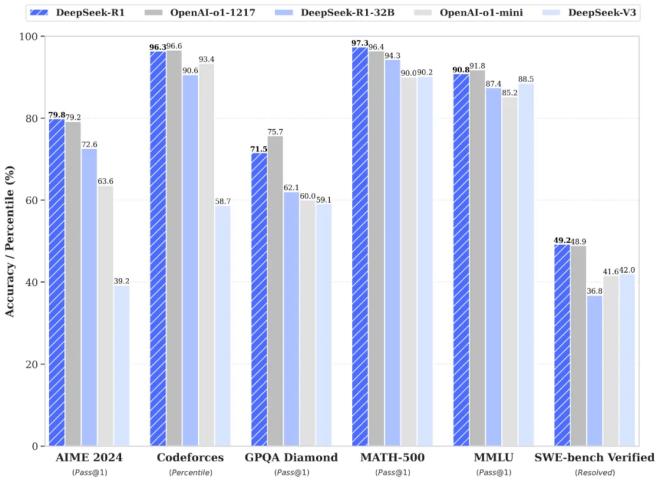
在相同的推理模型中,DeepSeek R1与OpenAI O1的技术要点不同,这是其创新培训方法。例如,数据培训会话中使用的R1 -Zero路由直接适用于基本模型监督细态(SFT)和标记数据。
此前,OpenAI的数据培训依赖手动干预的依赖。它的数据团队甚至已建立在不同级别的水平。具有大量数据和简单标签要求的大量数据简单明了。许多较高质量的标记都是训练有素的大学医生。
DeepSeek R1的直接强化学习途径就像让天才的孩子学会纯粹没有任何例子和指导解决问题。
困惑首席执行官Alawen Srinvas评论说:“需求是发明的母亲。由于DeepSeek必须找到解决方案,因此他们最终创造了更高效的技术。”
此外,DeepSeek在获得高质量数据方面也具有创新性。
根据DeepSeek的官方技术文档,R1模型使用数据蒸馏技术(蒸馏技术)生成的高质量数据,从而提高了培训效率。数据蒸馏是指原始和复杂数据通过一系列算法和策略的运行,以获取更精致和有用的数据。
这也是具有较少人参的OpenAI O1模型性能的主要关键。人工智能专家丁·雷(Ding Lei)博士在模型参数的效果与最终模型的效果之间说了字母清单(id:wujicaijing),两个“输入和输出不是成比例的,而是非线性...数据只是定性的,数据只是定性的,数据只是定性的,数据只是定性,数据只是定性的,数据只是定性的。团队数据清洁,否则数据干扰将随着数据的增加而变大。
更重要的是,DeepSeek是基于少于1个资源的上述结果。
去年12月底发布的DeepSeek-V3开源基本模型具有Pavaruable gpt-4O。但是,官方培训成本仅为2048 NVIDIA H800,总成本约为557.6万美元。
相比之下,GPT-4O型号的培训成本约为1亿美元,占据了NVIDIA GPU超过10,000元的NVIDIA GPU,并且是H100,它比H800强。
当时,负责Openai Lianchuang和Tesla的自动驾驶人员Andre Cappis表示,DeepSeek-V3水平的能力通常需要近16,000个GPU群集。
目前,DeepSeek尚未宣布培训推理模型R1的全部成本,但正式宣布其API定价。 R1输入为1元到1百万元,百万元,百万产量为16元。相比之下,OpenAI O1的运营成本约为前者的30倍。
这样的性能还触发了评估AI创始人Alexandr Wang的评估。中国人工智能公司DeepSeek的AI模型的性能与美国最佳模型大致相当。 “在过去的十年中,美国可能在人工智能竞争中一直在中国领导,但是DeepSeek的AI模型发布可能是“改变一切”。”
A16Z合作伙伴的成员,AI模型Mistral的成员Anjney Midha说,从斯坦福大学到麻省理工学院,DeepSeek R1成为美国顶级大学研究人员的首选模型。
包括斯坦福大学的计算机科学教授,微软主席兼首席执行官萨蒂亚·纳德拉(Satia Nadella)等,他们还开始关注中国的这一新模式。
实际上,这不是第一次DeepSeek。自从团队自行开发的模型宣布以来,DeepSeek两次引起了激烈的讨论,但仅限于国内。
2023年4月,1000亿个量化私募股权巨头幻想发布了公告,称它将集中资源和力量,专门的人工智能技术来建立一个新的独立研究组织来探索AGI(一般人工智能)。
一个月后的2023年5月,该组织被命名为“ -Depth搜索”,并发布了第一个模型DeepSeek V1。当时,“ 11财务”报道说,中国不超过5家拥有10,000多个GPU的公司。 DeepSeek是其中之一,并开始引起外部关注。
到2024年5月,DeepSeek再次在大型模型的帮助下再次闻名。当时,DeepSeek发布了DeepSeek V2开源模型,并领导了降低行业的价格。推理成本仅减少到百万元的百万元代币,约占GPT-4涡轮增压的1-70。
随后,主要制造商(例如字节,腾讯,百度,阿里等)降低了价格。中国的价格战揭晓。
DeepSeek R1的出现进一步向外界证明了初创企业在大型模型,尤其是一般模型中仍然有机会。
1月初,10,000元人民币的创始人李·凯福(Li Kaifu)正式表示他将退出追求AGI。将来,该公司专注于中小型参数的行业模型。 “从业务角度来看,我们认为只有大公司才能继续制作超大的模型。”李·凯夫说。
投资人比李·凯夫(Li Kaifu)更具侵略性。自2023年以来,Jinshajiang Venture Capital的合作伙伴Zhu Xiaohu认为大型模型正在破坏企业家精神,因为该模型的三个支柱,计算能力和数据集中在大型制造商中。在大型模型上应用护城河太低,很多时候提醒企业家不要对通用模型迷信。
Yuanwang Capital Cheng Hao直接认为,中国版的Chatgpt只会在5家公司中产生:BAT+BYTE+HUAWEI。在郑浩看来,企业家只有在第一名的优势时才能赢得大型工厂。
这正是因为Google和其他大型外国制造商对OpenAI的大语言模型途径并不乐观,因此Chatgpt在起始姿势的帮助下跑了出来。但是,目前的主要研究与开发模式已成为中国主要技术制造商的共识,甚至百度和阿里(Baidu)和阿里(Ali)也推出了比初创企业更快的产品。
然而,在对黑暗潮汐的采访中,DeepSeek Liang Wenfeng的创始人在回应与大型制造商的竞争时说:“大型制造商必须具有优势,但是如果不能迅速应用它,大型制造商可能不会是能够持续使用,因为它需要更多地了解结果,但头部的创业公司也具有坚实的技术,但是像旧的AI初创公司一样,它必须面临商业问题。
得到1000亿个量化基金的支持的DeepSeek选择了一条路径,除了对基金的担忧之外,也表明了唯心主义,也就是说,对于模型研究,无论商业货币化如何,都大胆地推出了年轻人。
在大约150支DeepSeek团队中,其中大多数是顶级大学的新毕业生,Bo Si,Bo 5次未毕业的实习生,以及一些仅毕业几年的年轻人。
这是Liang Wenfeng打算选择的结果,这也是DeepSeek在大型工厂面前抓住R1型号的秘密之一。 ,基本能力,创造力,爱等更重要。 “ Liang Wenfeng解释说。
这也使DeepSeek成为一家只有基本模型并且暂时不考虑商业化的公司,以及有能力继续开源旗舰模型的公司。
截至目前,DeepSeek R1已成为开源社区拥抱面的最高负载能力的最大型号之一,下载量超过100,000。
早些时候,由百度创始人李·扬洪(Li Yanhong)代表的国内派系坚决认为,开源路线无法采用封闭的源路线,并且缺乏对开源模型的商业支持,这将在未来的竞争中变得越来越大。
但是至少从目前的角度来看,DeepSeek R1的出现证明它仍然可以赶上大型模型的脚步球员,而初创公司仍然能够促进开源生态发展。
meta AI的首席科学家Yann Lecun在评估中提到:“在看到那些看到DeepSeek的人之后,中国在AI中超越了美国,您的解释是错误的。正确的解释应该是“开源模型超过专有模型”。 “
去年DeepSeekv3发行后,Liang Wenfeng表示,将来该公司将不会选择从开源到OpenAI等封闭资源。 “我们认为拥有强大的技术生态学更为重要。”
毕竟,至少可以解释Openai的经验。面对破坏性的技术,很难形成足够的护城河,并且不能阻止他人超越。 “因此,我们对团队具有浓厚的价值。我们的同事们在此过程中成长,并积累了很多专业知识,以形成一种创新的组织和文化,这是我们的护城河。”
当GPT-3于2020年发布时,OpenAI已详细介绍了模型培训的所有技术细节。中国人工智能大学人工智能大学的执行院长Wen Jirong认为,中国许多大型模型都具有GPT-3的阴影。
但是,随着OpenAI改变了其在GPT-4上的开源战略,并逐渐关闭,一些国内大型模型失去了追求复制。
如今,DeepSeek开放源R1的到来无疑将为国内外的大型模型参与者创造一个新的参考想法,以竞标模型的研究和开发。
DeepSeek在大型模型领域的蝴蝶效应开始影响一些大型工厂。
meta员工发布在硅谷匿名八卦共享平台上,梅塔一代人AI部门感到恐慌,因为DeepSeek感到恐慌,甚至报道了尚未发布的新一代开源开源Llama 4尚未发布,落后于DeepSeek落后于DeepSeek在基准测试中。
在外国媒体的进一步报道中,由元的AI团队和基础设施团队组建了4个战斗团队,以在像素级别的分析中分析DeepSeek。一些人试图了解DeepSeek如何降低培训和运营成本。有些人负责研究DeepSeek可以使用哪些数据来培训模型,有些人会根据基于DeepSeek模型的属性来考虑元模型的新技术。

图片来源:AI生产
同时,为了激发士气,梅塔(meta)的创始人扎克伯格(Zuckerberg)甚至发布了新闻,该新闻继续在2025年继续扩大AI投资,称2025年AI的整体支出将达到600亿至650亿美元至650亿美元。与去年的380亿美元400亿美元相比,增长了70%以上,从而构建了一个超级计算机集群,其超级计算机集群为130万GPU。
除了元来的源头之王的名字外,DeepSeek还从Openai窃取了顾客。
在API价格的诱惑下,比Openai便宜30倍,一些初创公司正在改变门。 Enterprise AI Agent Developer SuperFocus的联合创始人Steve Hsu认为,DeepSeek的性能类似于OpenAI旗舰模型GPT-4类似于SuperFocus最生成的AI功能。 “超级焦点可能会在接下来的几周内转向DeepSeek,因为可以在自己的服务器上免费下载DeepSeek,并将增加销售产品的利润率。”
成为更多公司的榜样,这也是DeepSeek大多数人希望在Liang Wenfeng的计划中占据的立场。在Liang Wenfeng的看来,DeepSeek只能负责将来的基本模型和切割边缘创新,然后其他公司根据DeepSeek为B和C业务建立。 “如果我们可以在上游和下游形成一个完整的行业,那么我们就不需要自己应用它。” Liang Wenfeng说。
在中国,对DeepSeek的研究也同时进行。据报道,坎bump,阿里巴巴和智慧等团队正在积极研究DeepSeek。 Byte Beating甚至可能正在考虑与DeepSeek进行研究合作。
在这些公司之前,Lei Jun在一步一步中挖出了DeepSeek的角落。去年12月,第一个财务爆发了消息,即雷·朱尼(Lei Jun)被怀疑已经支付了1000万年的薪水,并挖了一个“ 95年代才华横溢的女孩” Luo Fuli,这是DeepSeek-V2开源模型的主要开发商。将来,卢·富里(Luo Fuli)可能会在小米AI实验室工作,以领导小米的大型模型团队。
除了挖掘人们之外,中国更激烈的竞争也可能围绕API开始。 “去年,中国有一组初创公司和中小型企业,因为Openai中断了供应转向了一家大型国内模特公司。
压力传递给了这些大型国内模型公司。如果他们无法快速遵循模型效应达到R1级别,则客户将不可避免地用脚投票。
本文来自作者的微信公共帐户:Zhao Jinjie,授权36氪出版。
