
DeepSeek 17岁时的创始人被宣读为惠会大学,在36岁时,他负责1000亿个私人优惠
根据公众信息,DeepSeek的创始人Liang Wenfeng于1985年出生于广东省的Zhanjiang City。Liang Wenfeng从小就成绩优异。在小学的六年级中,他在考试中被吴楚1号中学聘用。它一直是学校的“顶级学生”,并展示了数学的伟大才能。

右边的第六次是Liang Wenfeng。图片来源:Zhanjiang青年

2002年,Liang Wenfeng今年17岁。他被朱钟1号中学的“大学入学考试冠军”(College Contrance Assige Champion)录取,并被宣教大学的本科电子信息工程专业。
2013年,郑安格大学的同学Liang Wenfeng和Xu Jin共同成立了Hangzhou Yakby Investment Management Co.,Ltd。和两年后,Hangzhou Fangfang Technology Co.智力。
在2021年,幻想党的资产管理规模超过了1000亿大关。 2023年,他宣布他将正式进入通用人工智能领域,并深入建立Deepseek,重点是人工智能。
最近,邮报-85s也出现在“新闻广播”中,作为AI初创公司的DeepSeek的创始人,参加了全国超级规格研讨会并当场演讲。

DeepSeek的崛起,NVIDDA的唱片暴跌
1月27日,当地时间,美国库存芯片行业进行了彻底的调整,NVIDIA下降了16.86%,创造了最大的市场价值的记录; Broadcom下降了17%以上,甲骨文下降了近14%,纳斯达克跌落了3.07%。
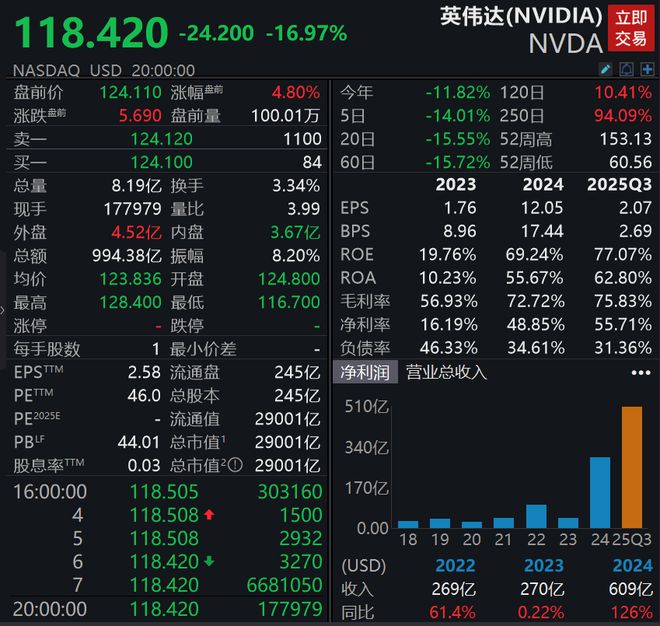
许多投资者将这种调整归因于DeepSeek的兴起。这家位于杭州的人工智能公司最近推出了最新的开源Model R1,其性能已追逐Openai Model O1。
该公司的大型DeepSeek-V3于去年12月推出,许多测试性能吸引了Claude-3.5和OpenAI的封闭式源代码型GPT-4O。各个项目甚至超过了。
就像一批人工智能分析师相信DeepSeek仅关注大型语言模型并暂时放弃多模式模型一样,该公司于1月28日发布了多模式的大型Janus-Pro,该模型是图像生成中的基准。 。在测试中超过了OpenAI的DALL-E3。
最令人震惊的硅谷是,DeepSeek的开源模型具有出色的性能,但基于较低的成本,较短的时间和较小的计算能力来实现。 V3和R1的培训成本仅为550万美元,不及人类和Openai类似模型的十分之一。

图片来源:DeepSeek官方网站
特朗普的声音:DeepSeek为美国行业震惊了
美国总统特朗普在27日在佛罗里达州迈阿密举行的共和党会议上说,中国人工智能初创公司DeepSeek的兴起应该为美国公司敲响“闹钟”。投资数十亿美元的资金,最好花费更少的钱(资源),我希望获得相同的解决方案。 “
人工智能国际黑帮如何看待这个奇迹?
微软首席执行官萨蒂亚·纳德拉(Satya Nadella)在世界经济论坛的世界经济论坛上说。是时候在计算效率方面有效地运行高效并表现良好。
困惑成立于2022年,其估值为90亿美元,这是首次人工智能和Openai梯队之后的第一个人工智能创业公司。最近,困惑性首席执行官Aravind Srinivas在接受采访时谈到了DeepSeek。
斯林瓦斯说,需求是发明的母亲。由于硬件资源的局限性,中国公司必须找到转型解决方案。最后,“他们(DeepSeek)以更高效,更低的成本方式开发了类似的技术。这确实很大。”如果meta被Openai或Anthropic所吸引,那么在中国也可以使用同样的言论来赶上美国。
但是,当我对DeepSeek的成就感到兴奋时,我们还必须对世界人工智能的发展动力保持客观和理性的理解永远不会停止,并且不会盲目自满。
21观察│雷 - 理解DeepSeek奇迹
21世纪的《先驱报》记者最近采访了许多家庭专家以及相关的从业者和投资者。 DeepSeek的现象具有以下共识:
首先,V3和R1的主要突破无法证明计算能力并不重要。
近年来,由OpenAI代表的美国人工智能建立在更强的计算能力,更大的参数和更高的成本上。在某种程度上,它可以称为人工智能的“硅谷叙事”。这种粗糙而水平的模型谈论了最终,这是一个5000亿美元的星际计划。
但是中国公司无法获得高性能的筹码,而且资金并不多。客观条件是有限的,只能通过基础计算能力来通过建筑,算法和数据利用来探索,并在特定领域采取了高效率和低成本的实用道路。
据说这条道路是,据江大学的计算机医生福·康(Fu Cong),南加州大学的来访学者说,在“邮政培训”的过程中,通过学习COT(思维链)方法,结果是获得结果,而不是直接而不是直接,而不是直接的预测答案,“该计划也是在圆圈中实现路径实现路径的猜测路径,而DeepSeek则使用非常快速的速度来验证可行性这条路!”
实际上,DeepSeek的创始人Liang Wenfeng透露,该公司以前保留了10,000 A100芯片。这比普通创业公司要强得多。但是,在V3和R1的开发中,由于效率很高,他们没有使用太多的计算能力。
其次,调整诸如NVIDIA之类的芯片股票主要是市场风险的发布。在DeepSeek的主要突破之间,不一定有联系。
由NVIDIA代表的人工智能部门持续增长了几年。尽管中间偶尔会发生波动,但调整还不够。 Nvidia PE在17日关闭后长期超过40次,45次。
1月17日,纳斯达克筹码股票的投资更加由市场情绪释放,这是预期的高估风险期望。
DeepSeek仅提供或触发风险释放的媒介。现在没有证据表明,全球计算能力,尤其是高端计算功率资源,具有过多的。如果在2025年开放人工智能应用程序的空间,计算能力的需求将增加,但是将从更多公司那里学会计算能力的高效率利用。 AI硬件仍然有很大的增长空间,并且计算能力叙事尚未过时。
1月27日,NVIDIA发表声明说,DeepSeek取得的进展表明其在中国市场上的芯片实际价值。将来,为了满足DeepSeek的服务需求,将需要更多的Nvidia芯片。
第三,探索和追赶:中国公司的创新能力正在提高。
梁·温芬(Liang Wenfeng)在去年7月接受媒体采访时说,硅谷习惯了中国人工智能的作用。当一家中国公司以创新的震惊贡献者加入游戏时。
毫无疑问,在大型模型开发路径上,DeepSeek扮演着创新者的角色,即低成本的高效综合道路,较少的计算能力。
作为陷阱,有一个帖子开发优势。 1月26日,在江西安创始人兼首席执行官组织的DeepSeek封闭式讨论中,专家提出,AI相似的跳线功能是Chaser现在计算能力需求的10倍。追逐者的计算能力一直不高,但是探险家仍然必须培训许多型号。
以后的头发可以巧妙地创新。例如。大型模型的开发需要庞大的数据集(数据库)。数据被标记,其准确性也不同。上述专家表明,DeepSeek非常重视数据标签。我听说Liang Wenfeng本人也将标记,这极大地提高了他们的数据准确性。另一个例子,DeepSeek也很擅长进行数据蒸馏(优化的筛选)。当然,如果它正在开发通用模型,则无法进行数据蒸馏。这些是公司培训后更有效的表现。
DeepSeek对国内同事的其他启示还包括大型模型开发也可以探索智力的边界,同时降低成本,寻找变压器外部的其他建筑;在产品中,AI代理在获得大规模应用之前具有许多出色的应用程序。探索空间,在多个领域有商业用途的机会。今年,就多模式而言,可能有一些产品可以挑战ChatGPT表格。
硅谷的一位高级AI工程师告诉《 21世纪的商业先驱报》,DeepSeek以低成本和高效的效率开发了几种令人惊叹的产品,探索了一条新的道路,因此国际同行必须佩服,但是除此之外,我们还必须为此感到自豪,我们必须为此感到自豪。同样,客观地意识到,诸如DeepSeek之类的中国人工智能初创公司没有能力全面挑战Openai和人类的巨人。人工智能的竞争才刚刚开始,前面有无限的可能性。
您使用DeepSeek吗?欢迎评论
内容的一部分来自Zhanjiang Youth和Qianjiang晚间新闻
SFC
本期的编辑江·皮皮(Jiang Peipei)
6月21日阅读
