
头图由豆袋生成。提示:一条大鲸,网络朋克,金属发光。
作者wang Zhaoyang
DeepSeek V3出现在一个月前,其背后的“能源” DeepSeek R1系列正式发布。
1月20日,DeepSeek上传了有关Huggingface的R1系列的技术报告和各种信息。
根据DeepSeek的说法,它这次发布了三组模型:1)DeepSeek-R1-Zero,它直接应用RL对基本模型,而无需任何SFT数据,2)DeepSeek-R1,它通过数千个长度通过了数千个长度长度是思想链(COT)的微调检查点开始使用RL,3)从蒸馏的推理功能到DeepSeek-R1的小型强度模型。
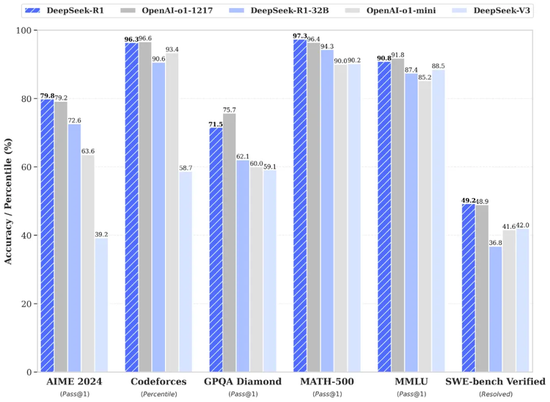
DeepSeek-R1获得了AIME2024的79.8%,略高于OpenAI-O1-1217。在Math-500上,它取得了97.3%的惊人分数,这相当于OpenAI-O11-1217,并且比其他型号要好得多。在与编码相关的任务中,DeepSeek-R1显示了代码竞争任务中专家的水平。 2029年的ELO评级是在Codeforcess上获得的,并且在比赛中的参与者占96.3%。对于与工程相关的任务,DeepSeek-R1的性能稍好于OpenAI-O1-1217。
“ RL就是您所需要的”
本技术报告中披露的最惊人的技术路线是R1零的培训方法。
DeepSeek R1放弃了过去的培训技术,这对于预训练模型-SFT至关重要。简而言之,SFT(细调)是使用大量手动标准数据来训练,然后通过增强学习进一步优化机器。简而言之,RL(增强学习)本质SFT的使用是Chatgpt成功的关键。如今,R1零通过增强学习完全取代了SFT。
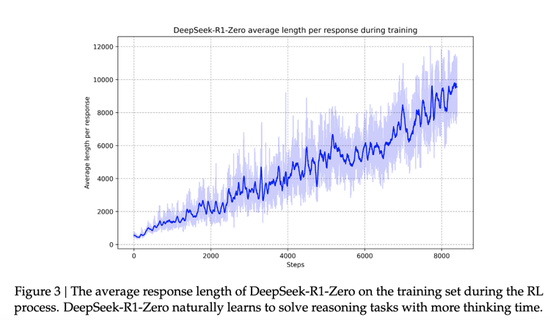
而且,效果看起来不错。该报告表明,随着增强学习培训过程的发展,DeepSeek-R1-Zero的性能稳步改善。例如,“在Aime 2024上,DeepSeek-R1-Zero的平均得分从最初的15.6%跃升至71.0%,达到71.0%,达到了与OpenAL-O1-0912相同的性能水平。这一重大改进突出显示了我们的RL算法在优化模型性能方面的有效性。
但是R1零本身存在问题,因为根本没有人类监督数据的干预措施,因此在某个时候似乎会感到困惑。为此,DeepSeek使用冷启动和多阶段RL来改善训练过程,以R1零培训更多的“人类” R1。这些技术包括:
冷启动数据介绍 - 阅读和语言混合问题的DeepSeek-R1-Zero,DeepSeek-R1最初通过引入数千种处理能力来微调;
增强学习的两个阶段 - 模型通过两轮加强学习,不断优化推理模式,同时使人类偏好保持一致,从而改善了多任务处理的普遍性;
增强的监督和良好的态度 - 当增强学习接近融合,结合拒绝采样和多个领域的数据集,该模型进一步增强了非畅通容量,例如写作,问答和角色扮演。
可以看出,与“监督数据”相比,R1系列甚至Openai的O-系列似乎更具侵略性。但是,这也是合理的。当模型的焦点从“与人的互动”变为“数学逻辑”时。前者有很多准备好数据,但是后者的许多是抽象的思维,这些思想一直留在您的脑海中。没有准备好的数据。它可以使用,并逐一找到奥运会大师,并在他们的脑海中标记出解决问题的想法显然是昂贵且耗时的。这是一种合理的方法,可以让机器生成一些数据链,这些数据链也存在于其自己的脑海中。
本文中的另一个非常有趣的地方是,在R1零训练过程中,出现了一瞬间。 DeepSeek称他们为“ AHA时刻”。
如技术报告中所述,DeepSeek-R1-Zero在自我进化过程中显示出重要的特征:随着测试阶段的计算能力的增加,复杂的行为将自发出现。例如,该模型将“反映”,即重新检查并评估先前的步骤,并探索解决问题的替代方法。这些行为不是通过明确编程来实现的,而是模型的自然产物和加强学习环境互动,从而大大增强了其推理能力,并使它们能够更有效,更准确地解决复杂的任务。
“它突出了增强学习的力量和美丽:我们只需要提供正确的激励措施,而不是明确教授如何解决问题,而是需要独立地制定解决高级问题的解决策略。提醒潜力,可以增强学习释放新级别的学习人工智能,为将来的自主和更适应性的模型铺平了道路。
碎片,蒸馏,欢迎大家一起延伸
在DeepSeek的官方推文中,所有焦点介绍不是R1模型技术或R1模型列表得分,而是蒸馏。
“今天,我们正式发布了DeepSeek-R1并同步开源模型的权重。DeepSeek-R1遵循MIT许可证,并允许用户使用蒸馏技术使用R1来训练其他型号。模型='DeepSeek-Reasoner'可以称呼。
这是它发布的前几个单词。
在R1的基础上,DeepSeek使用Qwen和Llama来蒸馏几种不同的型号,以适应市场上模型大小的最主流需求。它本身并不是这样做的,而是使用两个最强大,最强大的开源模型体系结构。 QWEN和LLAMA的结构相对简单,它提供了有效的权重参数管理机制,该机制适用于大型模型(例如DeepSeek-R1)上的高效率推理能力蒸馏。蒸馏过程不需要修改模型体系结构,从而降低了开发成本。此外,与从一开始训练相同规模的模型相比,直接对QWEN和LLAMA进行的蒸馏培训可以节省大量计算资源,与此同时,您可以重复使用现有高质量参数的初始化。
这是对DeepSeek的良好计算。
而且,效果同样好。
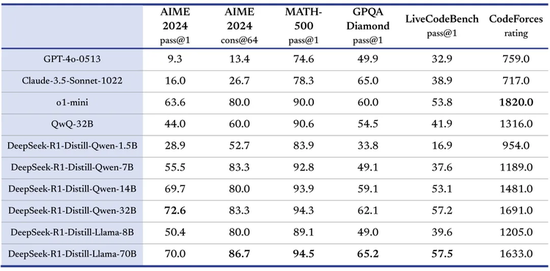
“当我们开源DeepSeek-R1-Zero和DeepSeek-R1两种660B型号通过DeepSeek-R1的输出,6个小型模型开源蒸馏到社区中。其中,Openai O1-Mini的效果。
此外,在技术方向上,这也启发了该行业:
对于小型模型,蒸馏比直接增强学习要好:在多种推理基准(例如Aime 2024和Math-500)中从DeepSeek-R1蒸馏获得的小型模型比直接增强小型模型要好。大型模型学到的推理模式可有效地通过蒸馏。
DeepSeek比Openai更有活力
如果您简单地总结了R1系列的发布,DeepSeek已经培训了具有巨大的计算能力和各种资源的强大基础模型 - 该模型称为R1 Zero,该模型在培训过程中直接放弃了GPT系列SFT,依此类推。预培训技术,几乎所有人都依赖于加强学习,创造了一种具有普遍反思自己能力的模型。
然后,由于这是从“自我反思”中学习的所有能力,因此R1零有时似乎有些杂项和令人困惑。为了使人们变得更好,DeepSeek利用自己的一系列技能来制作它,而真实的场景是对齐的,并且R1进行了转换。
然后,在此基础上,它不是您自己的小型模型,而是最受欢迎的开源框架,其中有几个最受欢迎的开源框架。所有这些都是用于外部参考和使用的开源。
在整个过程中,DeepSeek展示了强大的技术途径和自我制作派系的风格。这条路线与Openai对抗。
OpenAI的O系列以前曾经报道过培训方法,这基本上是GPT系列的“对齐”的风格。负责培训和对齐人对齐方式的先前的OpenAI研究人员实际上与提高模型能力相同。但是,随着O3的预览,同时,这些人类安全一致性机制的研究人员的集体辞职。这也使公司的创新掩盖了,并且似乎减慢了外部,并降低了活力。
这种对比也使DeepSeek在此阶段的出现更加期待。它比Openai更有活力。
从DeepSeek R系列的角度来看,其对齐方式处于R1模型的训练阶段,R1零更像是追求最重要的强化学习方法来发展强大的逻辑能力本身。人类反馈说他喜欢与否,此信息与最初的R1零培训不太混杂在一起。
这继续将“基本模型”功能和实用模型分开。最初,GPT3和指令实际上是这样的想法。但是,强调实践表现和成本效益的偏好。这就是为什么以前发现V3缺乏能力的原因。
因此,与“捕获O1”相比,DeepSeek R1零证明的能力,V3蒸馏V3的惊人能力以及这次显示用Llama和Qwen蒸馏出的几个小参数模型的能力,是这一系列动作的关键。
在与人类的互动方面,Chatgpt在GPT4提供的基本能力之后取得了突破,但Openai选择立即关闭源,因此只有它才能突破。在强大的数学推理能力的概括方面,DeepSeek V3取得了突破,因为DeepSeek R1的强烈出现,DeepSeek开放了它的来源,并选择使每个人共同突破。
DeepSeek对Openai的威胁是真实的,下一个“竞争”将变得越来越有趣。

大量信息和准确的解释,全部在Sina Finance应用程序中
