Smart West在2月1日报道说,今天清晨,Openai发布了新的推理型O3 Mini。
Openai说,这是其最具成本效益的推理模型。复杂的推理和对话能力已得到显着提高。科学,数学,编程和其他领域的性能超过了先前的O1模型。 ,可以与连接的搜索功能一起使用。
O3-Mini可在Chatgpt和API中使用,公司版本的访问权限将在一周内启动。
显然,DeepSeek到达了美国App Store的顶部,获得了Openai的免费列表。今天,Chatgpt向所有用户提供免费的推理模型:用户可以在Chatgpt中选择“原因”按钮尝试O3 Mini。
CHATGPT PRO用户可以访问无限访问。 PLUS和团队用户的利率限制已从每天的原始O1米尼增加到150条O3 Mini的消息增加。
付费用户还可以选择更高的智能版本“ O3-Mini-High”。此版本需要更长的时间来生成响应。

像O1模型一样,O3-MINI模型的知识截止日期为2023年10月。上下文窗口为200,000代币,最多可以输出100,000个令牌。
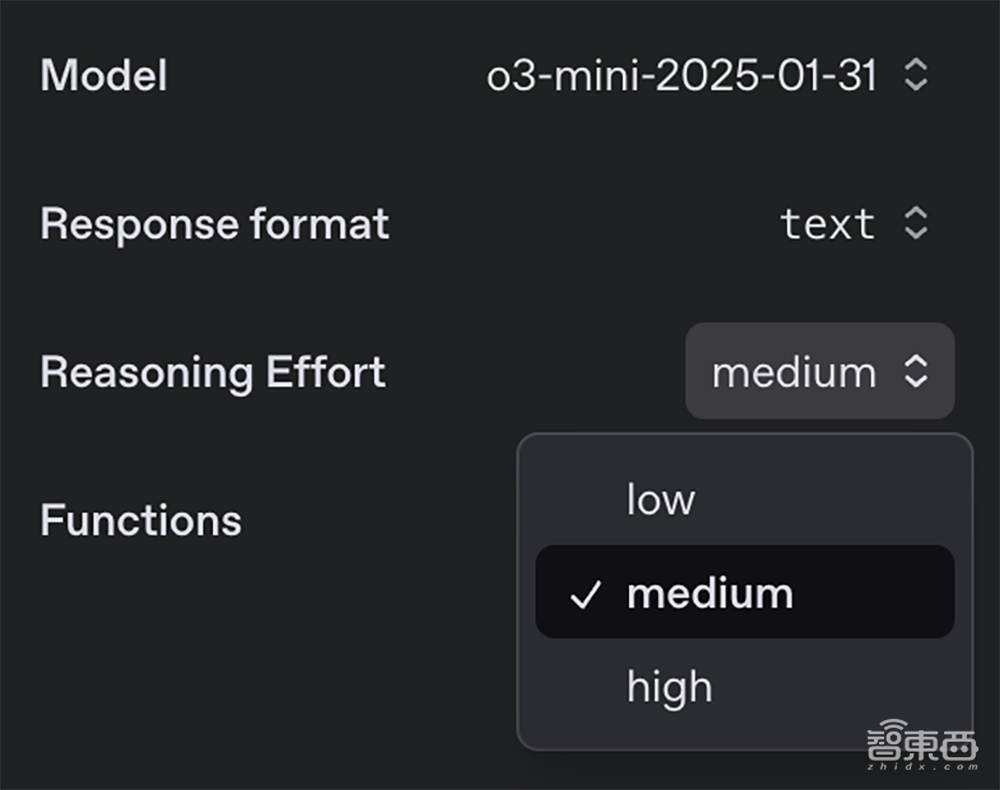
有三个版本的O3米尼,它们是低(低),中和高(高)的三种版本,可用于优化其特定情况。
O3-Mini目前不支持视觉功能,因此开发人员仍然需要使用O1进行视觉推理任务。
从现在开始,O3-Mini将在聊天完成API,Assistant API和Batch API中启动。
Openai表示,与GPT-4的推出相比,每个令牌的价格已降低了95%,同时保持了顶级推理能力。但是,O3-Mini API定价仍然高于DeepSeek模型。
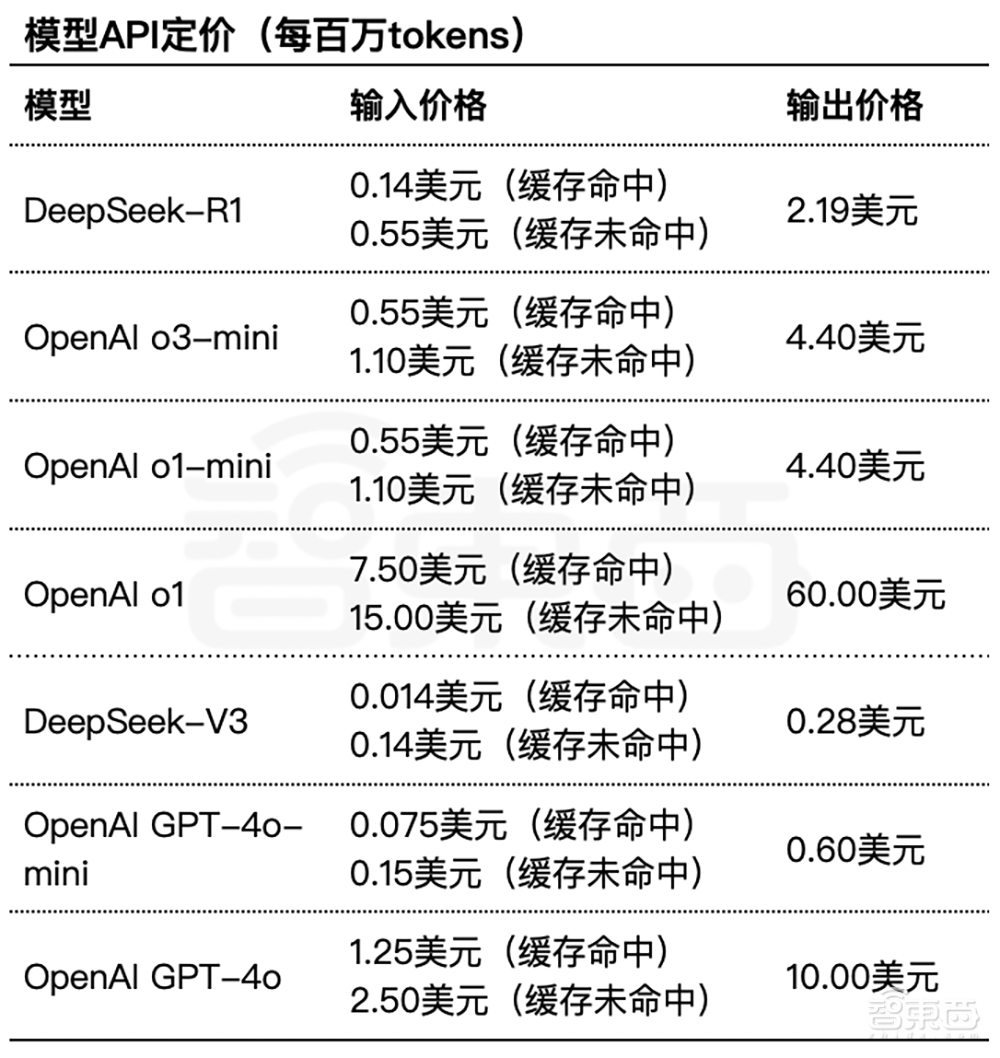
▲OpenAI模型与DeepSeek模型API定价(吉隆Xi图)进行比较
在安全方面,Openai发现O3-Mini在挑战安全和越狱方面已经大大超过了GPT-4O。
1。详细说明O3-Mini:科学和数学编程能力的演变,延迟大大降低
Openai发布了O3-Mini 37的详细报告,涵盖了模型介绍,数据和培训,测试范围,安全挑战和评估,外部红色团队测试,准备框架评估,多语言性能和结论。

O3-Mini在响应更快的响应时优化了科学,数学和编程。
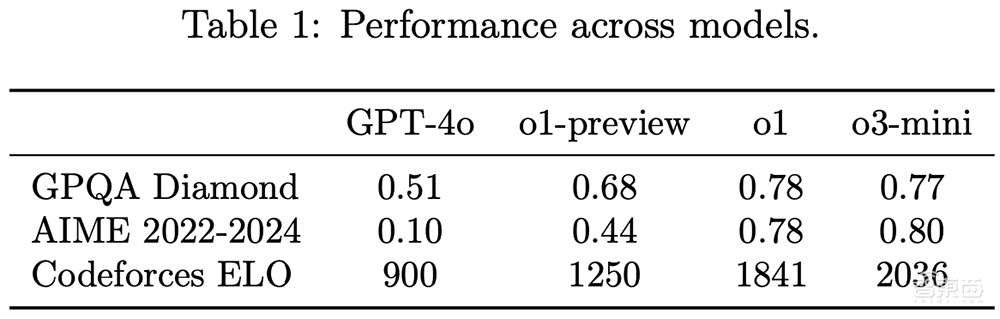
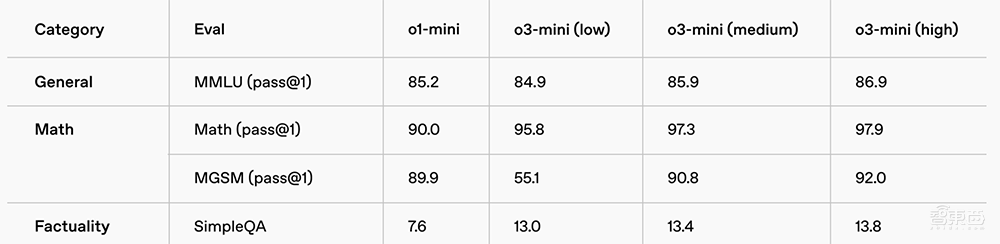
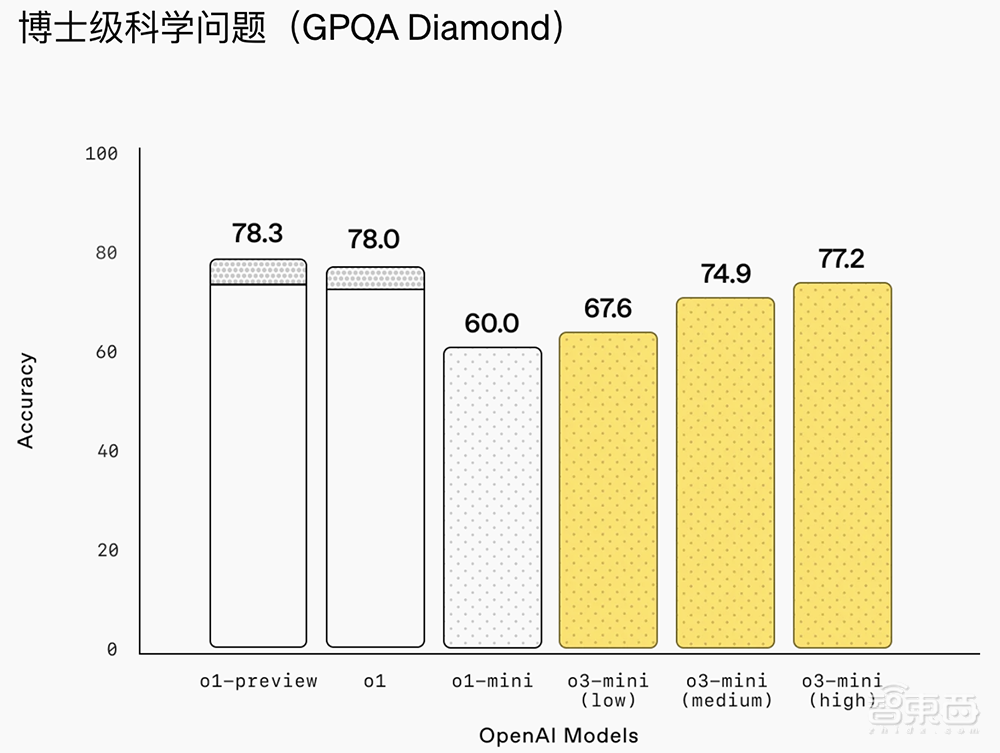
该模型在GPQA钻石(物理),AIME 2022-2024(数学)和CodeForcess ELO(编程)基准测试中。 O3米尼的得分分别为0.77、0.80和2036。
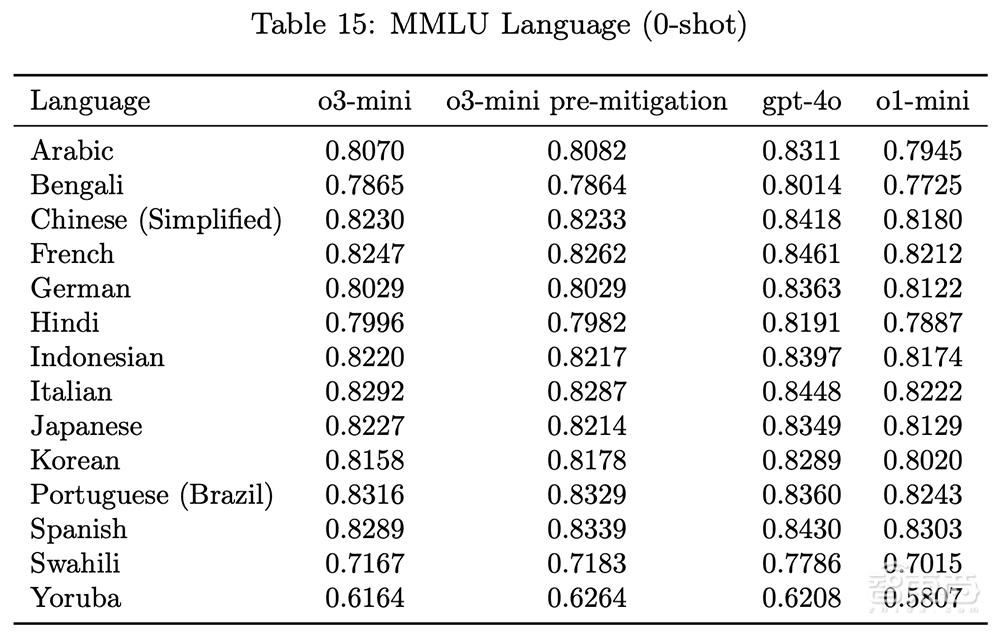
在14种语言的MMLU测试集中,O3-Mini的性能明显优于O1-Mini,显示出其在多语言理解方面的进展。
对外部专家测试人员的评估表明,与O1-Mini相比,O3-Mini的答案更准确,更清晰,并且推理能力更强。
在人类偏好评估中,测试人员更喜欢56%的O3-Mini答案,并且观察到困难现实中的主要错误减少了39%。在中国重点的能力下,O3-Mini在一些最具挑战性的推理和智力评估(包括AIME和GPQA)中的表现等同于O1。
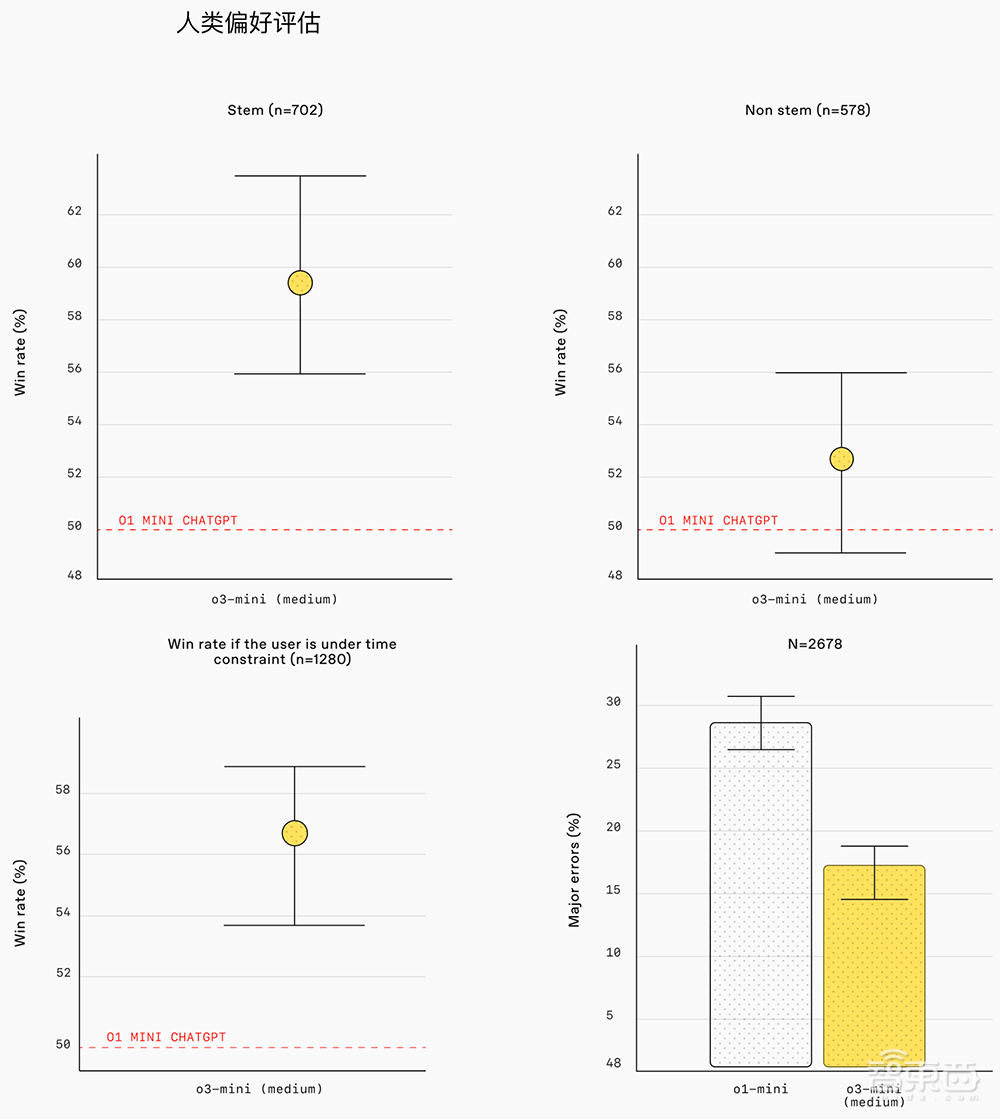
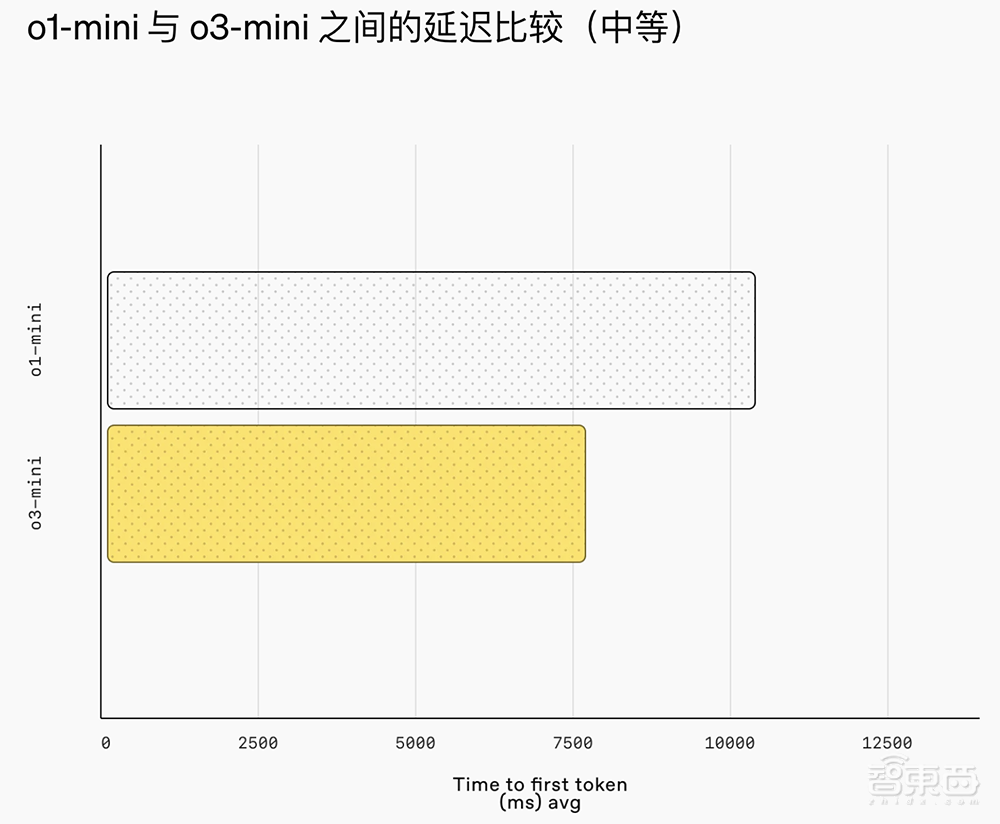
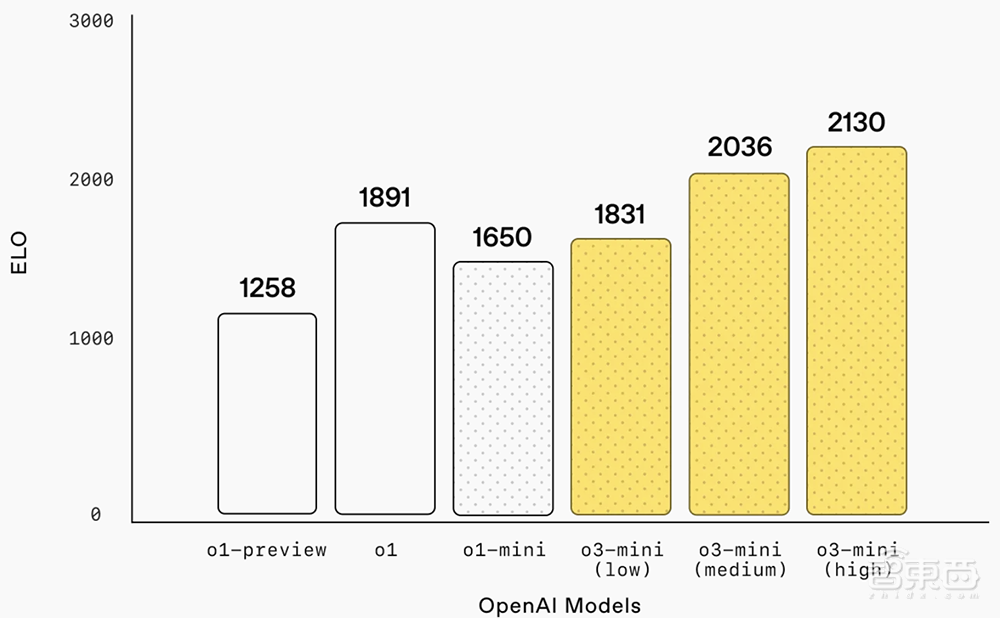
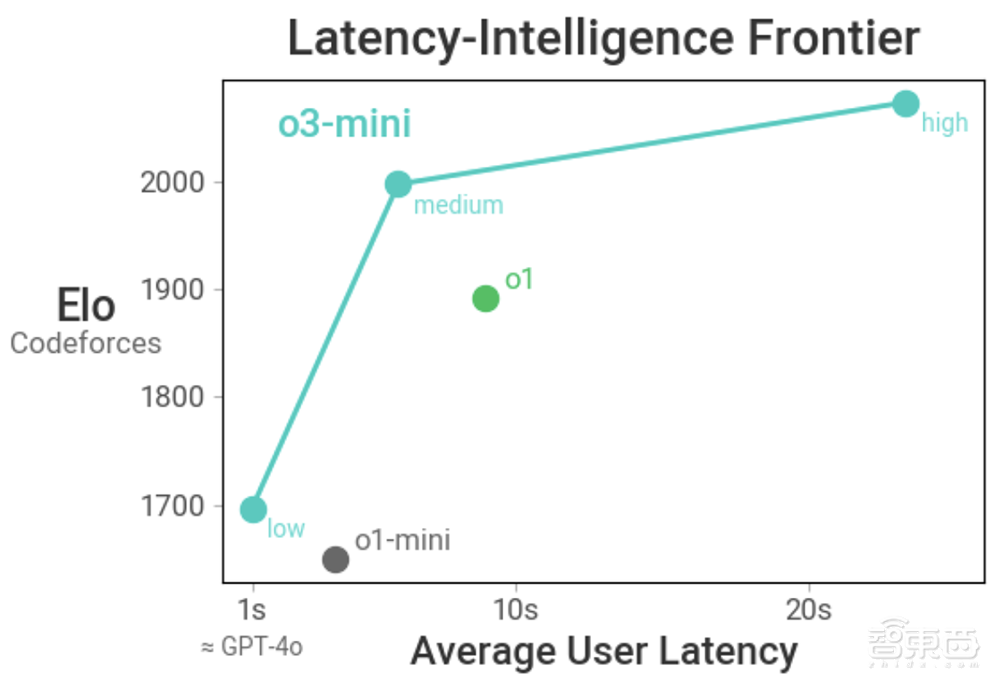
O3-Mini的智能与O1相当,提供更快的性能和更高的效率。在中央推理能力下,该模型在其他数学和事实评估中仍表现良好。在A/B测试中,O3米尼的响应速度比O1-Mini快24%,平均响应时间为7.7秒,而O1-Mini为10.16秒。
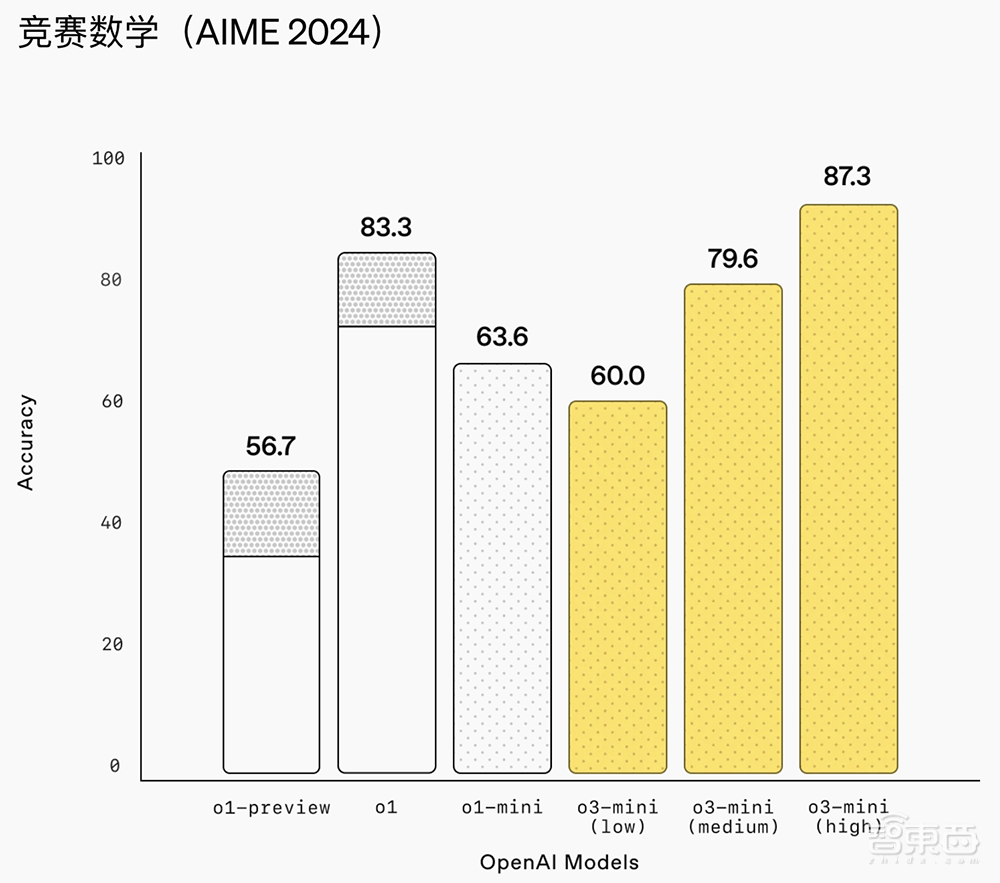
就数学而言,在低推理能力下,O3-Mini的性能等于O1-Mini,并且在推动推理的能力下,O3-Mini的性能等效于O1。同时,在高推理能力下,O3-Mini的性能优于O1-Mini和O1。
在Frontiermath上具有高管理功能的O3米尼比上一代更好。
在Frontiermath测试中,当提示使用Python工具时,具有高量值容量的O3米尼在第一次尝试中解决了超过32%的问题,其中包括超过28%的挑战性(T3)问题。
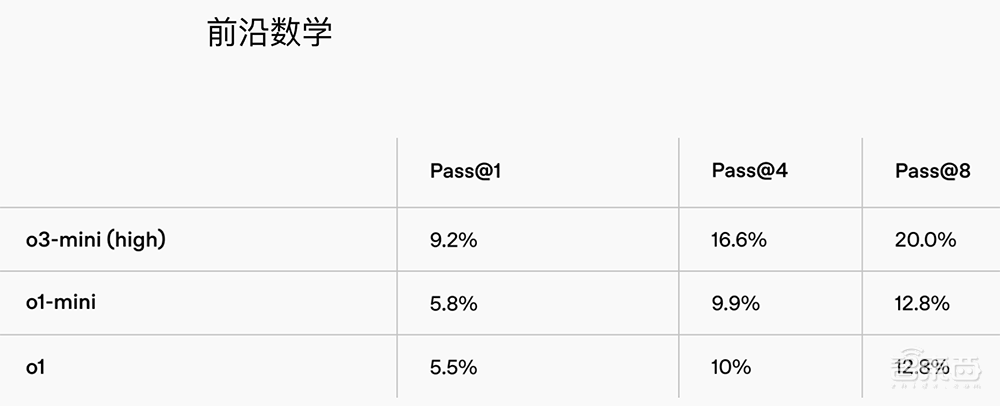
O3-Mini随着推理能力的增加逐渐获得了更高的ELO评分,所有这些都比O1米尼更好。在推理能力下,其性能等同于O1。
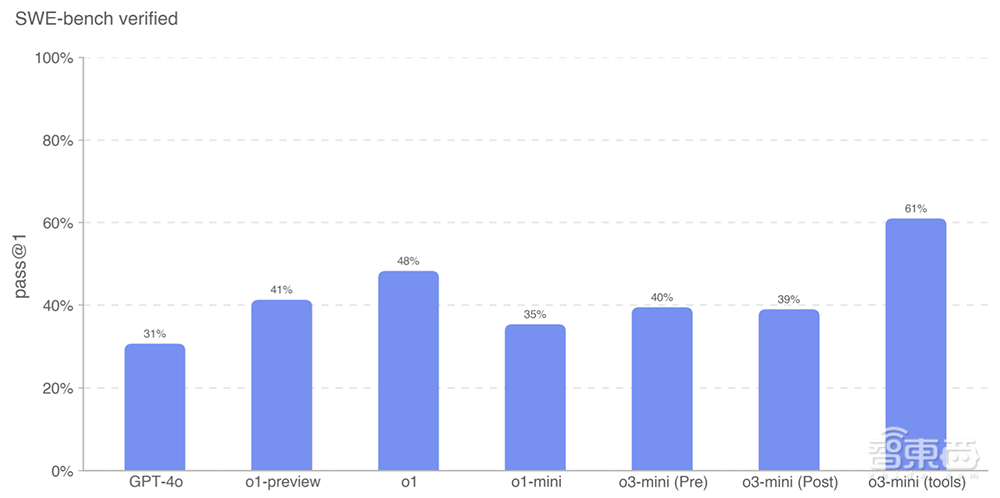
O3-Mini是SWE Bench验证中OpenAI的最佳模型。
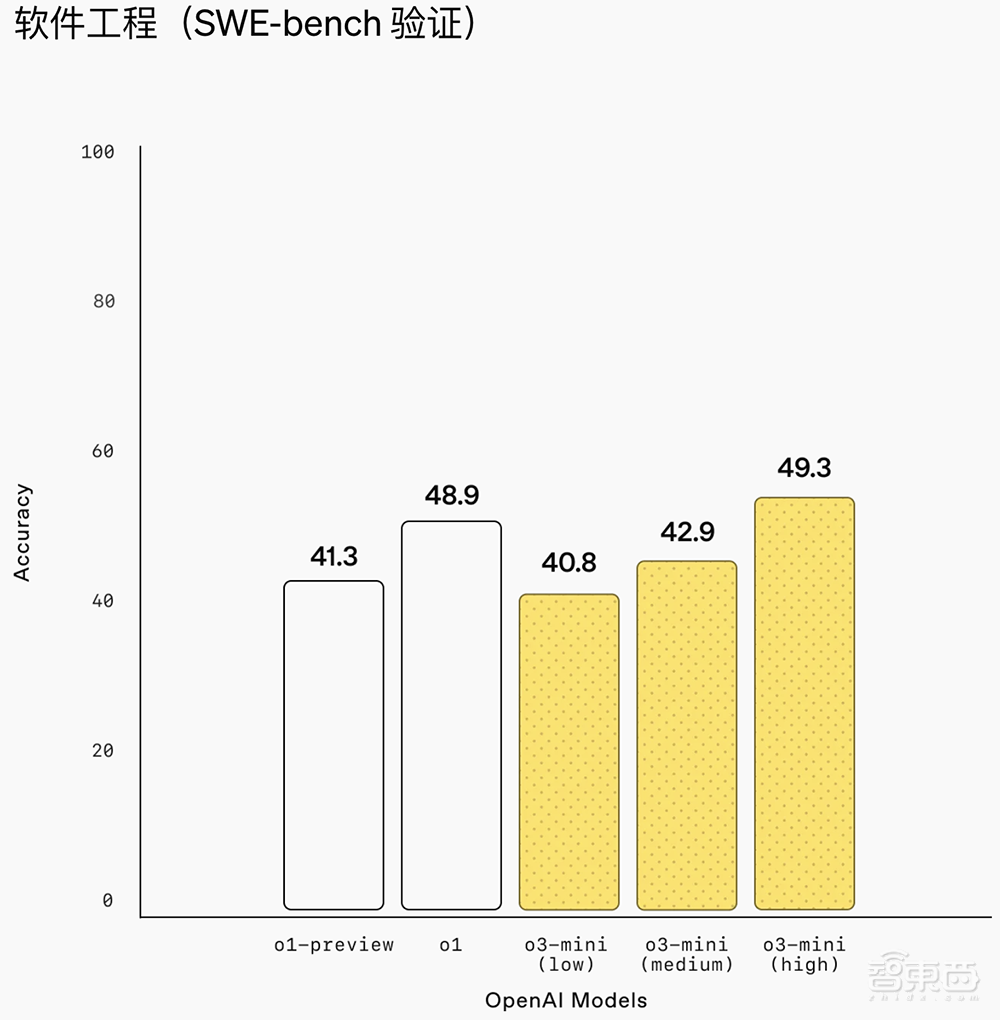
下图显示了有关SWE基础验证结果结果的更多数据。 O3-Mini(工具)是61%的最佳性能。 O3-Mini使用无代理的候选产品列出了候选产品,而不是内部工具得分为39%。 O1是第二好的车型,得分为48%。
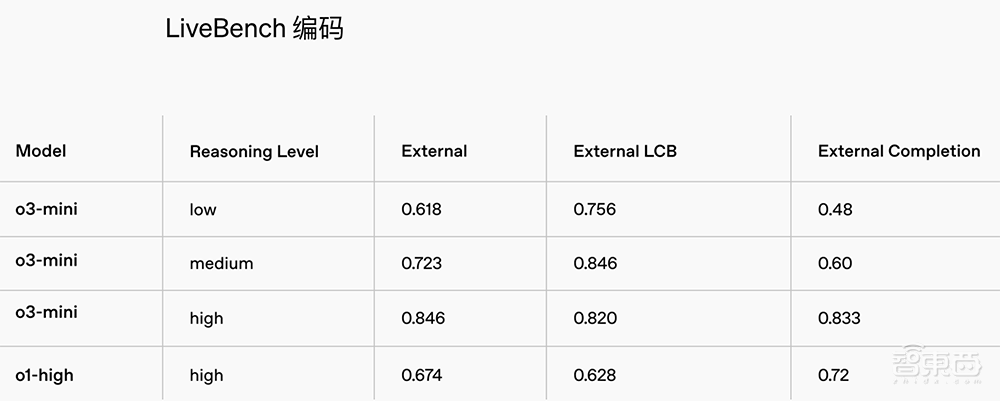
在LiveBench编程测试中,高推理能力的O3-MINI得分超过O1高。
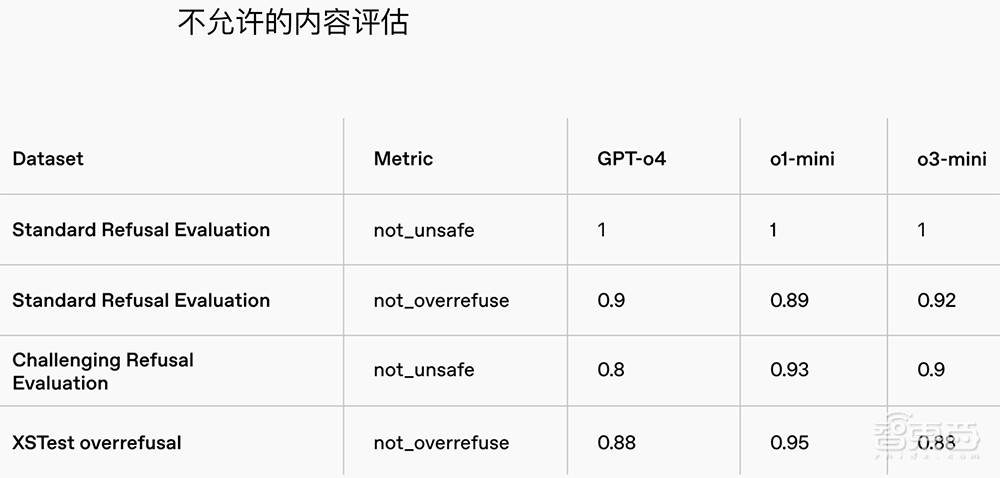
第二,许多安全评估超过GPT-4O
Openai还详细介绍了O3-Mini的性能,称O3-Mini在挑战性安全和越狱评估方面大大超过了GPT-4O。
在不允许的内容评估中,与GPT-4O相比,在标准排斥评估和挑战排斥评估中,O3-MINI的执行方式相似,但略低于Xstest。
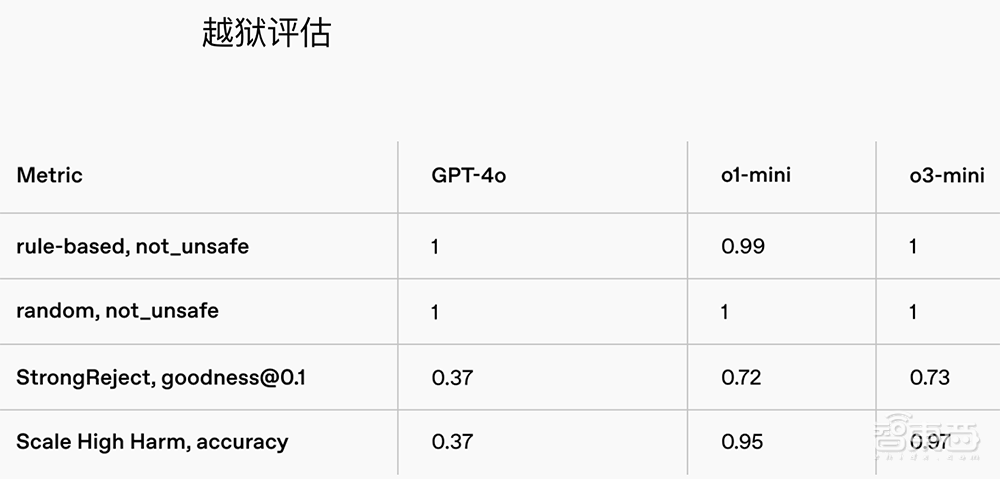
在越狱评估中,与O1-Mini相比,O3-Mini在越狱评估,越狱增强的例子,强调和人类来源方面同样表现出色。
在幻觉评估中,PersonQA数据集,O3-Mini的准确性为21.7%,幻觉率为14.8%。与GPT-4O和O1-Mini相比,它的性能相当好。

在公平和偏见的评估中,烧烤评估中O3-Mini的性能类似于O1-Mini,但是处理模糊问题时的准确性略有下降。

外部红色团队测试表明,与O1相比,O3米尼的表现相当,并且两者都明显好于GPT-4O。

在Gray Swan Arena的监狱测试中,O3-Mini的平均用户攻击成功率为3.6%,略高于O1-Mini和GPT-4O。
准备框架评估涵盖了四个风险:网络安全性,CBRN(化学,生物学,放射性,核),有说服力和模型自治。 O3-Mini在网络安全中被评为“低风险”,在CBRN,有说服力和模型自主权中被评为“中等风险”。产生生物威胁的表现已达到“中间风险”阈值。开发核和放射性武器的能力是有限的。

根据其评级,只能部署“中等”或以下评分的模型,并且可以进一步开发得分“高”或以下的模型。
3。O3基准测试成本可能超过3000万美元。 Openai正在为2900亿元人民币谈判新融资
自去年9月发布以来,Openai一直在迭代其推理模型。去年年底发布的O3模型是其最新一代的AI推理模型。
O3模型的高端版本旨在用于高计算应用程序,而O3-Mini满足了需要考虑经济和高效效率的用户的需求。这反映了OpenAI平衡可访问性和高级付费产品的策略。
我不知道过去两天我对DeepSeek感到焦虑,还是要预热O3 Mini,OpenAI联合创始人兼首席执行官Sam Aldman在社交平台上非常活跃,令人印象深刻,这也令人印象深刻提供更好的模型,重要的是要强调更多的计算。
昨天,他还宣布了很多宣布,第一个完整的8架GB200 NVL72服务器正在微软的Azure运行。

印度政府周五发布的“ 2024 - 2025年经济调查”报告显示,Openai可能花费了超过3000万美元来测试最新的AI推理型号O3。
该报告写道,OpenAI O3模型处理能力的突破付出了很高的价格。 ARC-AGI参考测试被认为是最具挑战性的AI任务之一,OpenAI效率低下的配置模型将带来200,000美元。高效率模型的成本是高效型号的172倍,约为3440万美元。

几天前,奥尔德曼还与微软主席兼首席执行官萨蒂亚·纳德拉(Satia Nadella)合影,称微软和Openai的下一阶段将比任何人想象的要好得多。
但是,作为Openai最大的投资者的微软可能会被日本软银集团带走。
最近,软银集团的创始人兼首席执行官Sun Zhengyi已变得更加接近Aldman。上周,宣布将联合起来建立AI巨头项目“星际之门”。在接下来的四年中,它已经投资了5000亿美元(约36万元人民币,约3.6万亿元。巨大的融资。
根据外国媒体的报告,OpenAI正在进行初步谈判,以在一轮融资中筹集高达400亿美元(约合291亿元),估值将达到3000亿美元(约2.18万亿英里)。日本软银集团将投资于这一轮融资,并谈论150亿至250亿美元的投资。其余资金将来自其他投资者。
此外,软银承诺在“星际之门”之前将投资超过150亿美元,最后软银可能与OpenAI合作投资超过400亿美元。这将成为软银最大的投资之一。
结论:疯狂的卷发成本 - 有效,高质量AI推理模型很受欢迎
早些时候,像马斯克这样的科学和技术领导者已经公开质疑如何承担建造“星际之门”的巨大成本。在DeepSeek高性能和低成本的开源模型的影响下,美国AI行业和华尔街投资者对其他美国AI开发人员(例如OpenAI)的大型手机支出策略更加可疑。
OpenAI推出的最新O3米尼也被视为反对DeepSeek模型影响的最新措施,这使该行业特别关注。
Openai的发行在新闻稿中说,O3-Mini的发布标志着该公司的任务又一步,即突破高具有成本效益的情报边界,以便高质量的AI可以进行更良好的态度。 Openai致力于前沿,并建立智能情报以平衡情报。 ,效率和安全性的大型模型。
