[文本/观察者网络Chen Sijia]最近,中国人工智能公司(DeepSeek)发布的DeepSeek-R1模型(DeepSeek)在世界上引起了轰动。使用极低的成本达到了匹配美国顶级AI模型的效果,并受到从业者的广泛赞扬。许多研究人员,投资者和西方媒体对中国AI模型震惊硅谷,甚至可能改变大型模型的研发规则。
随着DeepSeek Burst,创始人Liang Wenfeng也受到了公众的关注。作为17岁的“校”,曾在郑安格大学被录取,并在定量投资领域取得了惊人的成就,而Liang Wenfeng始终保持低调,很少出现。许多人很好奇-85企业家如何成功。
数学和人工智能的定量投资
公共信息显示,梁·温芬(Liang Wenfeng)于1985年出生于广东省的扬江市。2002年,Zhejiang University的电子信息工程专业的授予了17年-OREAR -OLD LIANG WENFENG,并获得了2010年信息和通信工程硕士学位。
在学校期间,他对金融市场产生了兴趣。特别是在2008年全球金融危机爆发之后,他带领团队使用机器学习技术来分析市场数据并尝试实现完全自动化的定量交易。这种经验为Liang Wenfeng积累了实践经验,并为他的未来职业奠定了坚实的基础。

DeepSeek创始人Liang Wenfeng
毕业后,Liang Wenfeng首次进入金融领域。 2013年,他和他的同学Zhejiang大学同学Xu Jin于2015年成立了Hangzhou Jacques Investment Management Co.,并于2015年成立了Hangzhou Fangfang Technology Co.,Ltd.。
2016年,幻想定量推出了第一个深度学习模型,并开始将GPU引入计算交易位置。之后,Liang Wenfeng继续扩展AI算法研究团队,将AI技术集成到定量策略中,并逐渐取代了传统模型。 2017年,幻想党声称投资策略是完全AI的。 2018年,魔术队正式建立了AI作为核心的发展策略。
但是,随着业务的迅速扩展,逐渐出现了计算资源不足的问题。 2019年,Liang Wenfeng带领团队开发了“ 1号消防”培训平台。从2020年开始,近2亿元人民币的总投资正式投入使用,配备了1,100 GPU“ Firefly One”。 2021年,幻想党投资了10亿元人民币,建造了“ 2号萤火虫”。
Fantasy在2018年赢得了私人展览会奖,这是中国私人股票证券领域最高的奖项。 2019年,Liang Wenfeng在金牛座奖颁奖典礼上发表了主题演讲“中国定量投资的未来”,这是罕见的公开演讲。
当时,Liang Wenfeng在讲话中说:“定量投资的未来是利用技术来提高市场效率”。
在AI领域很棒
2023年,Liang Wenfeng宣布了进入GM人工智能(AGI)领域的官员,并创立了DeepSeek。据报道,包括创始人Liang Wenfeng在内的DeepSeek只有139名工程师和研究人员。相比之下,有1200名研究人员在开发Chatgpt的发展中开发了OpenAI,还有500多名研究人员开发了Claude模型。
尽管团队的规模并不大,但DeepSeek在一年多的时间内取得了显着的结果。 2024年5月,DeepSeek发布了DeepSeek-V2模型,该模型以创新的模型架构和成本性能引起了人们的关注。 DeepSeek-V2的API价格定价为1元的百万元令牌和2元产量。价格仅占美国OpenAI GPT-4涡轮增压的百分之一。
DeepSeek解释说,DeepSeek-V2使用创新的架构,例如在注意机制和反馈网络中的DeepSeekmoe体系结构中使用MLA(Bulls的潜在关注)来获得更高的经济培训效果和更有效的培训效果和更有效的推理。
根据《 Surging News》的报道,DeepSeek-V2的出现曾经引发了一场大型国内模特“价格战”,而Baidu,Ali和Byte Beating等大型制造商宣布宣布减少大型模型产品。利安格·温芬(Liang Wenfeng)在接受媒体采访时说,DeepSeek并不打算成为行业的cat鱼,而低价后面的背后是昂贵的。
去年12月26日,DeepSeek-V3模型发布了,引起了技术行业的极大关注。 DeepSeek网站发布的信息显示,DeepSeek-V3的许多评估结果超过了其他开源模型,例如QWEN2.5-72B和LLAMA-3.1-405B,甚至可以将其与顶级封闭源模型(例如GPT)进行比较-4o,Claude 3.5-Sonnett介入。
更引人注目的是,DeepSeek-V3使用的成本和计算能力极低。只有计算能力略有弱的NVIDIAN H800 GPU约为557.6万美元。相比之下,OpenAI的GPT-4O培训成本高达7800万美元。这意味着DeepSeek-V3与GPT-4O的比较水平达到了十分之一。
今年1月20日,DeepSeek进一步取得了突破,并正式发布了DeepSeek-R1车型。在数学,代码,自然语言推理和其他任务方面,该模型具有OpenAI O1的官方版本。在验证阶段,大规模使用增强学习(RL)技术的使用极大地增强了模型的模型推理能力,而仅当数据很少被标记时。
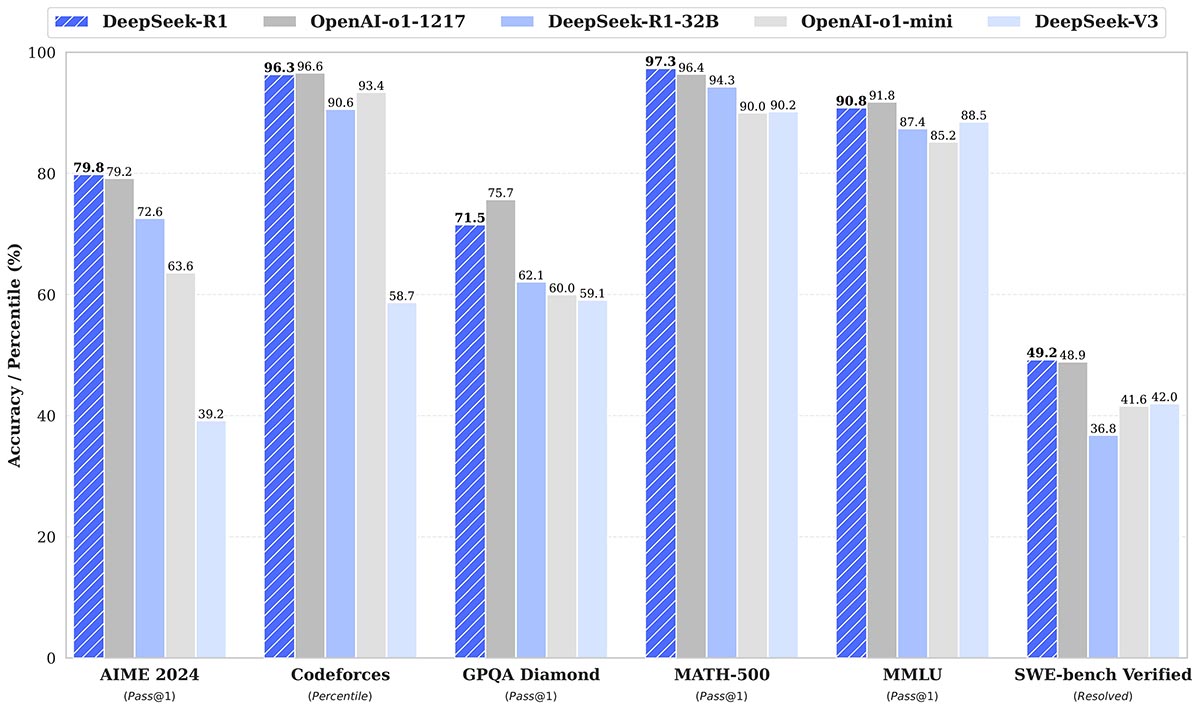
DeepSeek-R1,OpenAI-O1-11-1217和DeepSeek-V3比较DeepSeek微信公共帐户
这一系列成就动摇了全球技术行业。美国Openai的创始成员之一Andrej Karpathy称赞社交媒体:“ DeepSeek在有限的资源下表现出惊人的工程能力。它可能会重新定义大型模型的规则。”
硅谷著名的风险投资家马克·安德森(Marc Andreessen)将DeepSeek-R1与美国总统特朗普释放到白宫。他称赞这是“对世界最令人惊叹的突破之一,也是深远的意义。礼物。
DeepSeek的成功与Liang Wenfeng在团队管理和技术研发方面的独特战略密切相关。他组成了一个由当地年轻的程序员组成的团队,这些程序员不依赖退货或高级技术专家。团队成员大多是年轻人,他们超过5年没有超过他们的工作经验或工作经验。
Liang Wenfeng曾经向媒体承认,该团队“没有不可预测的向导,所有这些都是一些顶级大学的新毕业生,Boshi,Bo五个尚未毕业的实习生,一些年轻的年轻人只毕业了几年。 “他认为“创新需要摆脱惯性,有时经验成为负担。”
低键“技术理想主义者”
从将AI应用于定量投资到AI模型的开发,这不是将Liang Wenfeng从业务中推动的原因。他坦率地说:“在幻想派对的主要团队中,许多人是人工智能。当时,我们尝试了很多场景,并最终陷入了足够复杂的财务,一般人工智能可能会梅,而且可能成为下一个。画。
他说:“许多人认为这里有一个未知的业务逻辑,但实际上,人们很好奇……对AI能力界限的好奇心。”
DeepSeek一直遵守开源路线,并主动与全球开发人员分享核心技术结果。在该行业中的某些人中,Liang Wenfeng实际上是一个低键的“技术理想主义者”。
去年,梁·温芬(Liang Wenfeng)在接受媒体采访时说,面对破坏性技术,封闭消息来源形成的护城河很短。即使Openai关闭,它也不能阻止其他人被超越。 “开源更像是一种文化行为,而不是商业行为。给予它实际上是一种额外的荣誉。公司也将对文化有吸引力。”
Liang Wenfeng认为,随着经济发展的发展,中国也将成为贡献者:“我们习惯于摩尔从天上落下的法律,当我们在家里躺着18个月时,我们将获得更好的硬件和软件。
他还说,当时中国人工智能不能总是遵循该职位。 “许多国内筹码都无法开发,由于缺乏支持技术社区,只有第二次新闻,因此中国必须站在技术的最前沿。”
