
“核心技巧”
一家大型中国模特公司如何采用不同的方法并改变品牌?
作者|周
Xing Yan
在这个春节假期中,无论您是否是科学技术新闻的长期读者,都有可能无法逃脱AI产品相关的信息,称为DeepSeek。
从1月20日开始,中国技术公司深深地要求推出派生的模型DeepSeek-R1,而OpenAI的成本仅为OpenAI的成本达到了同一水平的最新型号GPT-O1的性能。
早些时候,深度启动的DeepSeek-V3仅为558万美元,不到外国公司GPU芯片和培训期限的十分之一,它获得了GPT-4O和Claude Sonnet 3.5培训。顶级模型是相当的性能。该消息迅速激起了全球科学和技术界。
在R1发行后的十天内,DeepSeek在包括中国和美国在内的70多个国家 /地区的Apple App Store下载列表中排名第一。这是第一次有产品首次超过OpenAI。在过去的几年中,AI竞赛的焦虑首先传播给了美国技术公司。
由于DeepSeek关于计算能力的需求是否产生了负面影响的讨论,这也引起了华尔街的恐慌。 1月27日,美国的主要科学和技术股票市场收缩超过1万亿美元,NVIDIA的股价领先于16.86%的潜水率,其市场价值蒸发了5890亿美元,这相当于没有两次下跌两次阿里巴巴。 Oracle下跌了13.78%,Ultra -Micro计算机下跌了12.49%,芯片制造商Broadcom下跌了17.4%,TSMC下跌了13%。
同时,技术股票的股价暴跌,美国技术公司开始研究和模仿中国对手。据报道,元已经成立了四个小组来研究DeepSeek。同时,还有更多问题和围攻。
在过去几年的AI比赛中,中国互联网和技术公司一直是美国公司的追随者。中国公司只能希望使用更多的资源投资对手。自2022年以来,美国政府宣布升级CHIP出口控制。从那时起,它已经反复更新了导出限制列表,以限制高计算功率芯片的导出。中国人工智能公司通常陷入计算能力焦虑症。
DeepSeek的最新模型的出现打破了大型模型发展的行业共识,并成为了一款巨大的资本游戏,并为中国公司提供了一个新的想法,这些公司赶上了行业中的大型美国模型:绕过技术路径首选美国堆叠功率,优化算法和优化算法,优化算法,探索效率。沿途采用“低成本和高输出”,也可以实现曲线超越。
1。如何超越曲线?
在发布这种新模式后,一些外国媒体和投资者曾称DeepSeek为一家陌生的中国公司。此描述不准确。
DeepSeek背后的深度是一家成立于2023年的年轻公司,但其母公司的幻想量化是一家国内量化贸易公司,已经管理了超过1000亿元的资产,并且多年前参与了AI研究。
DeepSeek创始人Liang Wenfeng开始AI研究的最初意图是通过GPU和火车定量交易模型来计算交易位置。从那时起,由于探索AI容量边界的好奇心,他们积累了10,000多个高级GPU芯片来开始训练AGI模型。这些储备金接近国内第一线互联网公司,高于大型型企业家六龙。这为DeepSeek未来的模型进步奠定了基础。
DeepSeek并不是突然的“惊人”。在最近的V3和R1模型推出之前,它引起了国内AI行业国内AI行业的关注。 2024年5月,DeepSeek以近1%的GPT-4-Turbo的价格发布了DeepSeek-V2。
自那时以来的30天内,Bytes,Baidu,Ali和其他公司的主要模型已减少。 DeepSeek每年降低了3次,每次降低了85%以上。
降低价格来自培训和推理成本的持续下降。与Openai及其中国效应相比,他们使用了数亿美元来训练大型模型,DeepSeek选择了更“切割”和“极端”路线。
其新的MLA(一种新的Polyhead潜在注意机制)由研究人员提出的结构与DeepSeek Moesparse(混合专家结构)相结合,以减少其他大型模型中最常用的MHA体系结构的记忆。 -13%。
该行业通常使用数万亿代币(文本单元)培训模型,但是DeepSeek使用“数据蒸馏”技术,也就是说,使用高级精确的通用模型作为老师,而不是使用海上策略来更有效地训练学生来培训学生“模型”和数据的最大计算减少了,只能达到1/5的数据量,从而促进成本下降。
一个受欢迎的例子可以帮助我们理解这一变化。每次处理传统的大型模型时,都需要激活所有参数,而普通用户提出的问题可能不需要那么多资源投资。咨询正常感冒; DeepSeek-R1将首先判断问题的类型,然后将相应的模块数学问题准确地称为逻辑推理单元,而写作诗是由文学模块处理的。该设计使模型响应速度提高了3次,并且能耗较低。
快速速度和较低的能源消耗是基于“低成本,高性能”的初始计划。 DeepSeek通过算法优化大大降低了培训成本。 R1的预培训成本仅为557.6亿美元,并且在55天的2048年NVIDA H800 GPU(用于中国市场的低调GPU)上完成。早些时候,诸如OpenAI之类的培训模型需要数千甚至成千上万的高级A100和H100和其他顶级图形卡,这会花费数亿美元的培训成本。
对于OpenAI或大型中国公司的大型模型开发人员而言,这不是可能制定模块化计划的可能性,而是权衡优势和缺点,并选择更适合其开发的解决方案。
Openai具有资金和计算能力的绝对优势,并优先考虑对“通用情报”的追求。他们花费了数十亿美元,并通过大量参数为培训模型提供培训模型,希望该模型能够实现所有人才的效果。模仿其使用的想法的使用可以确保其大型模型没有明显的缺点,并迅速达到商业水平。
DeepSeek选择从垂直场景中切入,从特定领域开始,并在某些领域(例如数学,代码)中追求性能,然后逐步提高其他领域的能力。
DeepSeek R1和OpenAI O1在数学,代码,自然语言推理的任务下测试得分的官方版本。
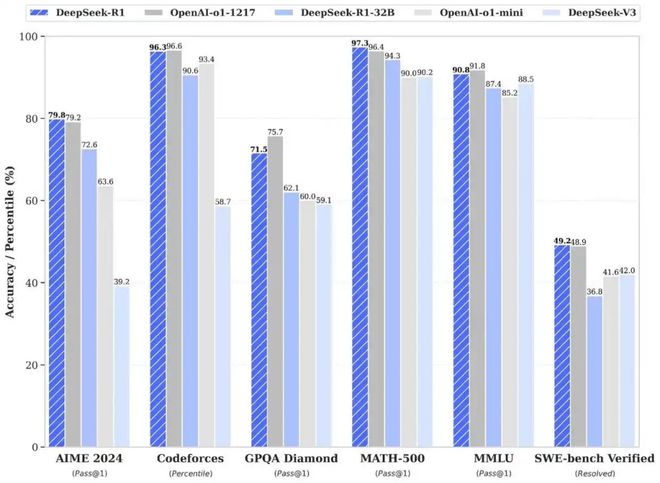
这种方法意味着更加困难和更高的风险。如果将错误(例如将诗歌创造误解为数学问题),则输出质量将会下降;模块之间的知识隔离(例如用数学公式编写情书)可能会导致交叉域任务失败。如果无法开发足够好的模块化模型,则可能会浪费早期投资。大多数公司受到路径依赖或资源限制的限制,很难接受所有人的高风险路线。
这并不容易。 DeepSeek早期的MOE模型错误判断率通常超过15%。团队介绍了增强的学习优化路由决策。在长期训练之后,该模型控制了单位数字低位置的错误判断率。
许多行业人士将DeepSeek理解为“模块化特种部队”,并且在诸如Openai之类的“一般巨人”等比赛中表现出相同的能力,甚至在某些领域略有领先。尽管DeepSeek的整体技术与OpenAI等美国公司之间存在差距,但足以被视为逐渐接近的竞争对手。
更重要的是,DeepSeek跳过了美国开发人员认为这是必不可少的步骤,这意味着,在资金和计算能力芯片的缺点的情况下,中国甚至世界各地的AI初创公司也可能会超越曲线。在大公司的阴影下,垂直领域的集中度也可以帮助它们在特定场景中形成优势,避免与巨人竞争,并找到自己的位置。
2。开源模型,DeepSeek的选择和障碍
DeepSeek引起感觉。除了模型本身的出色性能外,它还来自他们坚持的免费开源声称,以及模型的源代码,权重和体系结构。这意味着个人,开发人员或业务用户都可以免费使用其最新模型,并在此基础上开发更多应用程序。
这一决定受到许多行业专家和投资者的称赞。
NVIDIA的科学家吉姆·范(Jim Fan)评论说:“我们生活在一个时代。一家非美国公司允许Openai的最初意图继续,也就是说,对真正开放性和增强所有人权力的切割边缘研究。”
Silicon Valley Venture Capital A16Z的创始人Marc Andreessen还评论说,DeepSeek-R1是他见过的最令人惊叹,最令人印象深刻的突破。作为开源模型,它将礼物带给世界给世界的礼物。本质
Openai最初是AI领域的AI领域的垄断地位。它旨在通过开源来促进AI技术的发展,并避免在AI领域过度控制Google。因此,它被命名为“ OpenAi”,以反映其开源视野。但是,在收到微软的投资后,在GPT-3发布后,Openai正在考虑考虑培训成本,收入和维持其竞争力。
目前,其他大型模型,例如meta的Llama声称可以选择开源路线,但是许可证需要申请访问权限,限制一些商业用途,并且仅披露了该结构的一些细节。培训脚本。这样的开源很限于AI行业的进步。
大多数由中国主要公司开发的大型大型模型,例如百度的Wenxin,华为Pangu Dapa型号和其他产品都选择关闭源路线。它们通常基于商业化和竞争考虑。平台公司拥有大量用户数据的足够资源,您可以依靠自己的内部流通来完成模型的培训和迭代。结束资源使他们能够保持自己在模型专业知识领域的优势,并避免被竞争对手超越。
DeepSeek对开源的选择不仅是因为传统制造商的技术垄断面临的挑战,而且是基于其自身发展的考虑因素。风险公司可能在资源和计算能力方面处于不利地位,但是通过开源策略,他们可以快速建立生态并获得更多的用户和开发人员的支持。
DeepSeek创始人Liang Wenfeng先前谈到了开源的想法,并成为了更多公司的榜样。即使是一个小型应用程序也可以以低成本使用大型模型,而不是仅在某些人和公司的手中,形成垄断。
他认为,DeepSeek只能负责将来的基本模型和切割边缘创新。其他公司根据DeepSeek建立B和C业务。如果可以形成完整的行业,那么就无需自己应用。
DeepSeek选择的模块化模型设计就像是精确的手表 - 可以复制单个齿轮的过程,但是总体协作需要长期试验错误和生态积累。竞争对手无法通过简单复制来复制其原始模型。用户和开发人员使用它的越多,这意味着该模型是更多的培训。
目前,DeepSeek得到了1000亿个定量基金的支持。 After the worries of the funds from the funds, a path of idealism is selected, that is, only model research, not considering business monetization, attract developers through open source basic models, and gradually gradually gradually gradually gradually gradually gradually gradually gradually gradually gradually gradually逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐逐渐。通过工具链的企业版(例如模块培训平台)来促进商业化。
在当今的AI竞争模式下,对于一家初创公司来说,开源不仅是一种技术策略,而且是参与行业规则制定的关键。将来,模型容量逐渐透明,真正的竞争优势将来自建立数据反馈封闭的能力,以及将技术影响转化为商业生态学的能力。
从本质上讲,这是“标准配方权”的竞争 - 开源协议可以成为行业的事实标准,并且可以在下一代AI基础设施中占据核心地位。中国技术公司与美国技术公司之间的差距不是时间维度,而是创新与模仿之间的差异。
这次,由DeepSeek代表的中国科技公司提供的计划不再模仿 - 遵循,而是创新。
参考材料:
暗浪:揭示DeepSeek:一个更极端的中国技术理想主义者的故事
腾讯技术:DeepSeek在除夕发布了新模型。在多模式中统一的革命是吗?
Leifeng.com:Moe有效培训A/B方面:与魔鬼交易,使用“内存”来更改“性能”
NYT:中国人工智能初创企业DeepSeek如何与硅谷巨人竞争
