春季音乐节更新期间的一轮国内车型使Openai无法坐下。
2月1日,北京时间,Openai紧急在O3 Mini新的推理模型上推出,这是首次开放到Chatgpt。

大型国内模式的竞争力浪潮甚至使一些海外同事担心美国AI的竞争力。
最近,前Openai高管和AI Start -Up巨头人类人类人类人类众多的Dario Amodei很少发表长期的文章。 Ammore认为,DeepSeek-R1模型在特定的基准测试中正接近美国最高水平,他认为DeepSeek的突破更加确认了美国筹码出口控制政策的必要性和紧迫性。
在这一轮国内AI功率中,几乎在DeepSeek发布了DeepSeek-R1型号时,月球的黑暗面也推出了新的Kimi K1.5型号。
以上两个推理模型全面基准了OpenAI O1的完整版本。其中,Kimi K1.5已成为第一个将肩部O1的完整版本与支持文本和视觉推理的特征进行比较的多模型模型。
尽管Openai展示了下一个大型型号的技术演化途径,但是直到DeepSeek-R1和Kimi K1.5发布之前,许多国内模型制造商尚未推出可以针对OpenAI O1的完整版本的模型。它们的外观已成为国内大型模型的另一个优势,以破坏Openai Technology Black Box。
更重要的是,与OpenAI O1模型对付费的限制相比,DeepSeek-R1或Kimi K1.5都支持用户免费的无限通话。

它与OpenAi O1的完整版本的模型性能以及免费电话的差异化竞争优势相媲春节。
在春节阶段的帮助下,以后完成了一项战略调整,它已演变为中国科技公司的预留计划。
在2014年春节的前夕,微信首次推出了Red Invelope功能,但未能引发太多的水。转折点发生在2015年。在春节晚会的帮助下,它花费了5亿元,以“摇晃”的红色信封发射微信。在除夕,微信红信封的总数超过了10亿次,而支架已经在2天之前花费了10年。完成的工作为-2亿个银行卡约束。
后来,阿里内部的马元被称为“偷偷摸摸的珍珠港”的反击,并促使阿里在2016年开始对春季节盛大的赞助,并通过形式洒了红色信封。 “收集五个祝福”。
现在,在DeepSeek-R1和Kimi K1.5的新型号之后,Openai必须调整其新产品以释放节奏。
在快速技术迭代的压力和国内大型模型的模型性能下,即使它是Openai,我也很恐怕它将无法几次站立。 “我们将开发更好的模型,但我们不会像往年那样保持如此巨大的领先优势。” Openai首席执行官Ultraman在O3-Mini的问答环节中说。

一旦发布了DeepSeek-R1和Kimi K1.5的新模型,它们就在海外用户群中引起了激烈的讨论。
NVIDIA AI科学家Jim Fan首次发布了这两种模型的相似之处。他们认为,他们俩都简化了增强的学习框架,提高了推理的绩效和效率,并评估了两家公司发表的技术论文。 “重”水平。
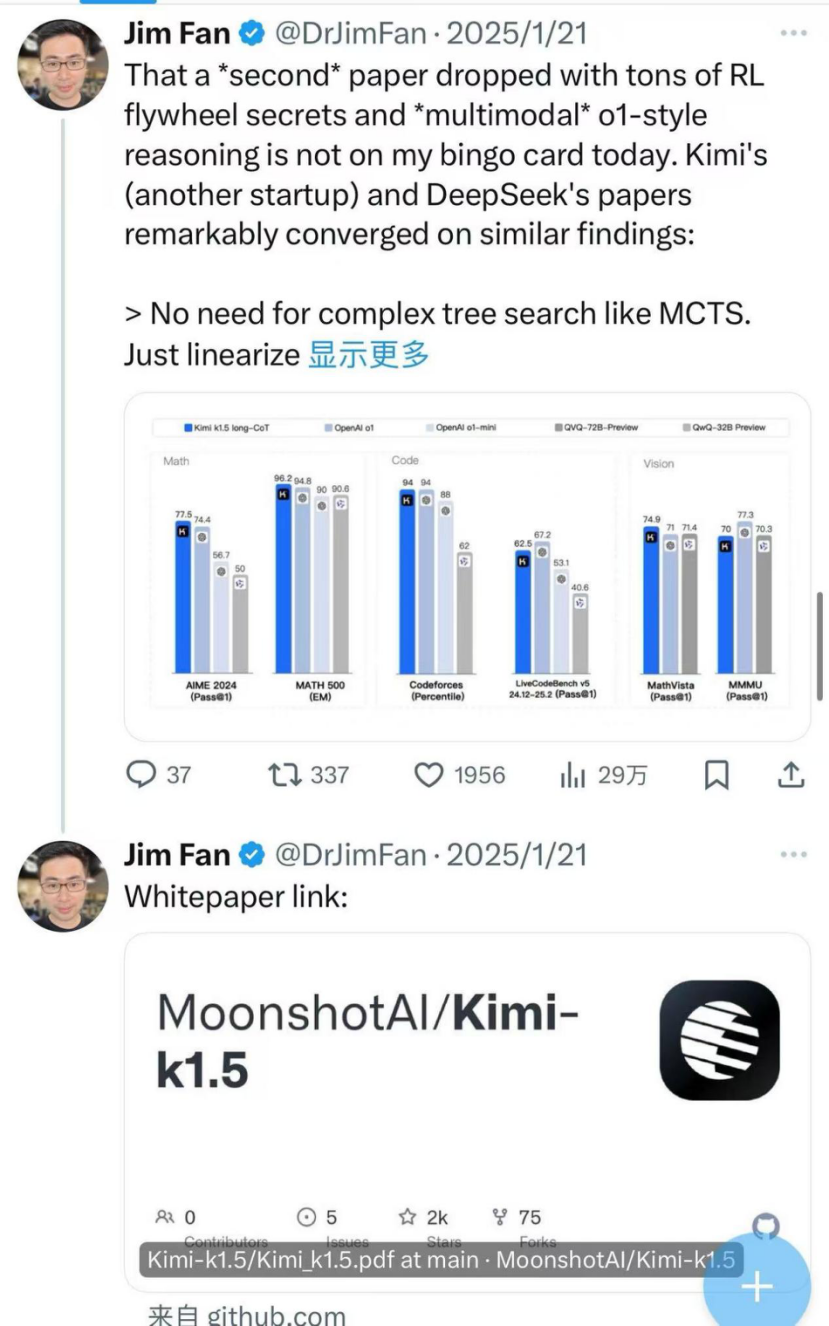
伯克利博士的人工智能,拥抱机器学习科学家内森·兰伯特(Nathan Lambert)和技术大V AK等也尝试了基米(Kimi),许多内部人士对中国的这两种产品进行了评估。

像DeepSeek-R1一样,Kimi K1.5的新模型也显示了一个详细的思维过程。
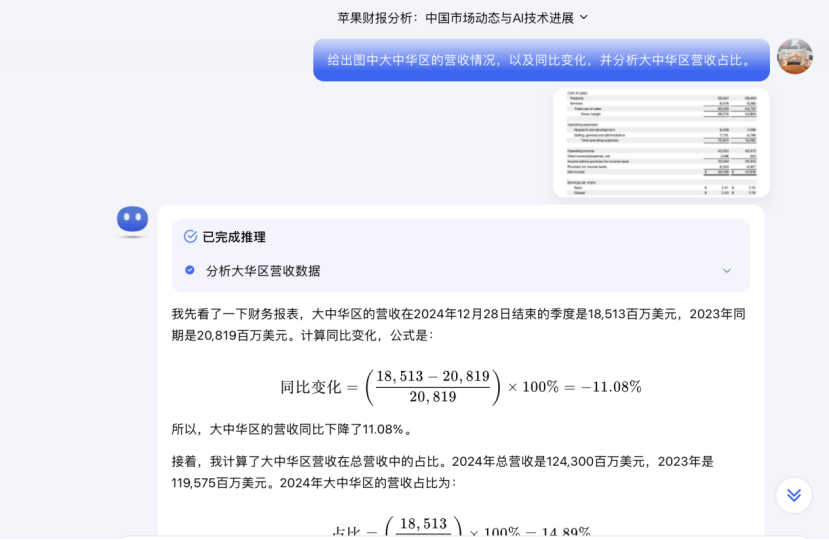
1月31日,北京时间,苹果发布了一份新的四分之一财务报告,以此作为选择Kimi K1.5推理模型的机会,并输入及时的单词“写Apple Financial Report Reports Analyscript。启动Apple AI时国内iPhone。
经过一段时间的思考,基米(Kimi)给了苹果公司在2025财年第一个财政季度的绩效报告数据,并特别指出,大中国的收入为1851.3亿美元,一年一年减少了11% 。
除了在Internet上提供94个Web信息外,Kimi还列出了自己的详细思考过程。

如果大型模型被视为数学家,则在加入推理功能之前,大型模型将证明是一个新的定理,或者解决了一个新的数学问题,只写出答案。出来。但是,随着推理功能的增加,大型模型现在可以介绍数学家心目中最初存在的思维过程,并尽可能完整地介绍它。
Kimi K1.5推理模型的思维过程有点“授予人们比授予钓鱼者更糟糕”,以指导学生学习或协助程序员编写代码。他们都有更强大的实际用途。大型模型非常有用,并且逐渐变得易于使用。
更重要的是,与DeepSeek-R1相比,Kimi K1.5或OpenAI是第一个实现完整O1完整版级别的多模型模型。
在Kimi K1.5推理模式下,上传了苹果最新的季度财务报告的数据图,并提醒您“给予大中国的收入,以及一年的变化,并分析大中国的收入。比较”。
Kimi不仅了解图片中的收入数据,而且还通过列出数学公式准确地计算出了大中国的收入,一年一年,收入比例也从去年同期的17%下降到去年至17%至17%至去年同期17%至17%,至17%至17%至17%至17%至17%至17%,至17%至17%至17%至17%至17%去年同期至去年同期17%至17%。今年15%。
杨Zhilin在一次采访中解释说,从某种意义上说,长文本是很长的原因。 “如果我们想使AI完成一两分钟以完成完成长周期的任务,那么它必须在漫长的上下文(上下文)中,才能真正进一步进一步进步AI。”
在一定程度上加入多模式函数,例如图片识别,也可以将其视为长期文本准确性的提高。将来,通过无损压缩视频的变化也可能会更加修改这种改进。强大的。

对才能和人才的培养的重视已成为DeepSeek和Moon黑暗面的共同特征之一,以使Openai Model O1的第一个模型。
在目前大约150个DeepSeek团队中,其中大多数是顶尖大学,波西,BO和5名未毕业的实习生的新毕业生,还有一些仅毕业了几年的年轻人。
自2023年初成立以来,月球的黑暗面长期以来一直被视为中国主要型号初创企业中技术人才密度最高的球员之一。
在Kimi K1.5中,月球的黑暗露面团队发现了一种原始技术,可以提高推理的效率,即Long2Short的有效思维链。
在O1模型中,OpenAI通常取决于逻辑链(COT)逐渐得出解决方案,这是一种使用时间来交换精确答案的方法。
Long2short技术方法由月亮黑暗面条团队开发,“ Teach”的“ Teach”短思维链(简单有效的推理过程)是长期思维链(复杂的推理过程),结合了两者,并最终针对“短模型”为了增强学习和良好的态度,以达到提高令牌和培训效率的使用的目的。
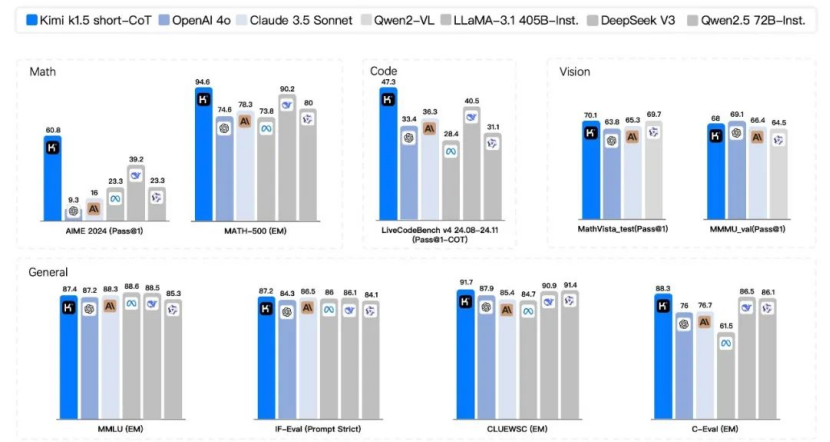
在简短的婴儿床(短文本)模式下,Kimi K1.5的功能也很大程度上带领GPT-4O和Claude 3.5,率为550%。
良好的产品使用经验是将用户增长带到Kimi。根据2024年12月的类似网络的数据,Kimi在网络上排名全球前五名,仅次于Chatgpt,Google Gemini,Claude和Microsoft Copilot。

在DeepSeek和Kimi之间的攻击下,来自Openai等对手的新一轮新竞赛已经在途中进行。
Ultraman Preview O3 Mini的OpenAI模型是紧急在线,甚至新一代的高端语音模型也发布了。为了更快地追求AGI,Ultraman还联合起来了Softbank Sun Justice,并创立了5000个。计算电源开发计划1亿美元。
可以预见的是,追赶的压力可能很快就会再次出现在国内AI的脑海。
但是,通过DeepSeek-R1和Kimi K1.5新模型的新模型的新模型,值得关注的新变化是,国内大型模型越来越多地证明了他们对外界的独立创新能力。真的超越了。
最近,meta的首席AI科学家Yann Lecun再次在达沃斯的“技术辩论”会议上再次提醒,“我认为当前的LLM(大语言模型)范式范式生命周期很短,这可能只有三到五年。在期间。这一年,没有清醒的人会再使用它们,至少它不会成为AI系统的核心组成部分...我们将看到新的AI架构范式的出现。局限性。”
对于任何决心认识AGI的大型模特参与者,追逐Openai绝不是公司的最初意图和目标。 OpenAI和国内模型之间的差距正在逐渐缩小。这是无可争议的客观现实。
斯坦福大学计算机科学系的客座教授,Google Brain的访问教授安德鲁·诺格(Andrew Ng)最近发布了DeepSeek的讨论使许多人认识到一些明显的重要趋势。其中之一是中国在AI一代领域的压倒性。我们

随着Chatgpt于2022年11月启动,美国在AI一代领域领先于中国。该行业在2 - 3年之间考虑了这一领先差距。但是,经过两年的发展,Openai在国内模型中的主要优势已经缩减至6个月。
通过诸如Kimi和DeepSeek之类的模型的持续突破,“中国公司表现出强大的创新能力,甚至在诸如视频产生的特定领域甚至还达到了当地的领导才能。” Wu Enda评论说。
国内大型模型的技术快速迭代能力甚至在O3米尼的问答环节中吸引了Ultraman。
在最终分析中,大型模型中包含的无限技术创新空间为国内大型模型参与者提供了无限的机会。
更广泛的AI创新前景还将在更多的国内大型模型中拥有一个奇怪的时刻。
