心脏报告
心脏社论部
春节假期不到一半,DeepSeek引起的巨大浪潮仍在影响与人工智能有关的所有领域。
我今天醒来后,DeepSeek R1模型正式加入了Azure AI Foundry和Github模型目录。开发人员可以快速进行实验和迭代,并将这种流行的模型整合到他们的工作流程中。
这使每个人都有情感:没有永恒的竞争者,也没有永恒的伴侣,每个公司都应迅速接受变化。
毕竟,微软仍在说昨天:DeepSeek非法偷走了Openai的知识产权。今天的Microsoft:DeepSeek现在在我们的AI平台上启动,欢迎大家尝试。
Microsoft人工智能平台副总裁Asha Sharma表示,DeepSeek R1进行了严格的红色团队和安全评估,包括自动评估模型行为和广泛的安全性审查,以降低潜在的风险。
同时,DeepSeek的R1和V3已在AI代码编辑器光标上可用。
亚马逊云技术还宣布,企业和开发人员可以在Amazon Bedrolk和Amazon Sagemaker AI中部署DeepSeek-R1车型。此外,他们还可以使用AWS Trainium和AWS地狱来通过Amazon Elastic Compute Cloud(Amazon EC2)或。 Amazon Sagemaker AI部署了DeepSeek-R1-Distill模型。

亚马逊首席执行官安迪·贾西(Andy Jassy)。来源:
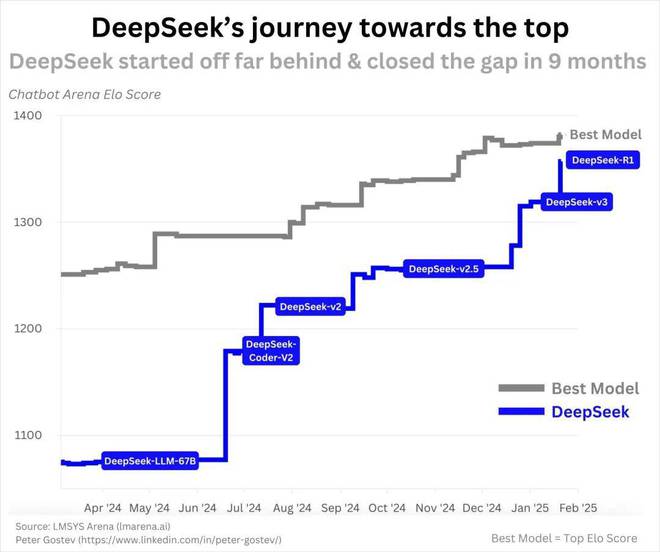
DeepSeek R1爆炸了AI圆圈仅十天。这些技术公司的反应速度再次证明了在国内外的令人震惊的深处。
它甚至使Openai的高级官员首次对其他公司的模式发表了评论,这很少见:
来源:
首先,DeepSeek模型的进步再次表明,2025年人工智能竞赛将非常激烈,例如从V3到R1的迭代仅几周。
其次,DeepSeek颠覆了人们对AI成本的看法。
Openai前政策研究员Miles Brundage说,R1使用两种关键优化技术:更有效的培训和思维链推理增强了学习。这种组合使模型能够实现O1级别的性能,同时使用较少的计算能力和资金。
DeepSeek的成功使人们认为,要赢得人工智能竞赛,这确实需要数十亿美元才能计算。传统观点认为,大型技术公司的下一步仅仅是因为它有足够的“休闲资金”,因此会主导人工智能。现在,大型技术公司似乎只是在燃烧资金。计算这些模型的实际成本有些棘手。由于制裁,DeepSeek可能“不能诚实地说出哪种类型的GPU以及它具有多少GPU。”
但是围绕DeepSeek的争议可能才刚刚开始。
一方面,Openai和Microsoft目前正在研究中国竞争对手是否使用OpenAI的API来训练DeepSeek模型。彭博社在本周早些时候报道说,微软的安全研究人员在去年年底通过OpenAI开发人员帐户检测到大量数据,这可能与DeepSeek有关。
另一方面,根据彭博社的说法,美国正在调查DeepSeek是否已经通过新加坡的第三方购买了高级NVIDIA芯片,以避免相关限制。

来源:
DeepSeek真的违反了上述限制吗?在长篇文章中,著名的分析师本·汤普森(Ben Thompson)说,从DeepSeek发布的每一代模型的开发细节的角度来看,大量创新方法旨在克服H800所暗示的不足的记忆带宽的问题,而不是H100 。
“ DeepSeek实际上对每个H800的132个处理单元中的20个编程了,该单元专门用于管理交叉交流。这实际上在CUDA中是不可能的。这是NVIDIA GPU的低级别指令集,这基本上就像是一个装配语言。
“ DeepSeek在设计此模型时做出的决定仅受H800的限制;如果DeepSeek可以使用H100,则可能会使用更大的训练集群,并且对于克服宽度而言,它的优化程度要少得多。”“”“”“”“”。
“我在上面提到,如果DeepSeek可以使用H100,他们可能会使用较大的群集来训练模型,因为这将是一个简单的选择;实际上,它们没有,并且带宽是有限的,这会促进他们促进许多人。模型架构和培训基础架构的决定。可行的:大量优化可以在较弱的硬件和较低的内存带宽中产生重要的结果;
在文章中,本·汤普森(Ben Thompson)还强调了DeepSeek R1对所有技术巨头带来的长期影响:
从长远来看,该模型的商业化和更便宜的推理(DeepSeek也证明了这一点)对大型技术公司非常有益。
如果微软可以以非常低的成本为客户提供合理的服务,这意味着微软在数据中心和GPU上的支出将减少,或者考虑到推理成本要低得多,使用率可能会大大增加。
另一个最大的赢家是亚马逊:如果有很高的开源模型,他们可以以远远低于预期的成本提供服务。
苹果也是一个大赢家。推理所需的记忆需求大大减少,使边际推理更加可行,并且Apple拥有最好的硬件。 Apple Silicon使用统一的内存,这意味着CPU,GPU和NPU(神经处理单元)可以访问共享内存池;这意味着苹果的高端硬件实际上具有最好的推理消费者芯片(Nvidia Game GPU为32GB 32GB,苹果的芯片最大RAM为192 GB)。
同时,meta是最大的赢家。去年秋天,我详细阐述了如何在元业务各个方面从人工智能中受益;意识到这一愿景的主要障碍是推理的成本,这意味着要考虑到元位需要保持领先地位,大量参考成本和培训成本的大幅降低将使这一愿景更容易实现。
同时,Google的情况可能会更糟:减少硬件要求削弱了Google TPU的相对优势。更重要的是,一个零成本推理的世界增加了更换搜索产品的可行性和可能性。当然,Google的成本也降低了,但是任何改变现状的行为都可能为负。
在这场战斗之后,今年的大型模式将如何发展,您如何看待?
