DeepSeek招募了人们,首先登上热门搜索!
什么?无限的专业和经验,本科新的毕业生每年的薪水数百万。
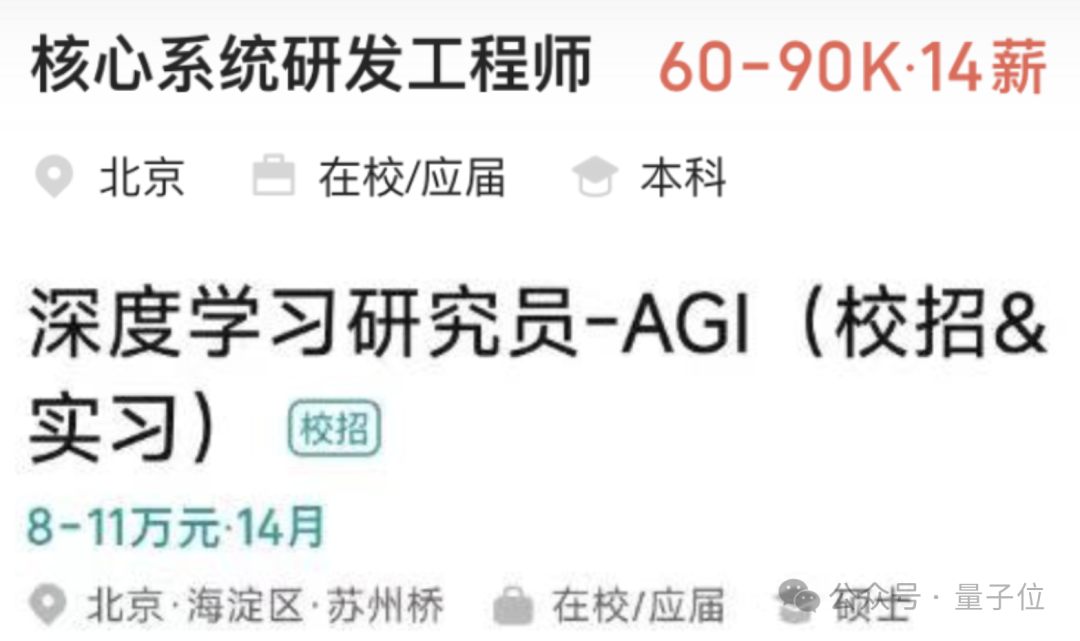
从老板平台的开头,可以看出,最高工资已达到110k×14,最高的本科生也是90k×14。
甚至实习生每天500元。根据每月20天的计算,您每月可以赚取10,000元人民币,每日薪水最多为1,000元。

难怪许多网民流下了嫉妒的眼泪。
有些人一次又一次地叹了口气,AI就像原始的互联网一样,有些人吃了ERA奖金。
但是,截至发稿时,DeepSeek在Boss平台上的招聘职位已被清空,由于特定的原因,尚不清楚。
当然,这不会影响我们的招聘需求和DeepSeek的才能概念。

本科开始的学士学位,您不看经验,只看能力
仔细阅读DeepSeek发布的招聘信息,您会发现其中大多数是本科入学率,除非个人职位需要硕士学位。
而且,英雄都不会要求某种方式,无论是什么专业和工作经验,DeepSeek的门都向您敞开。
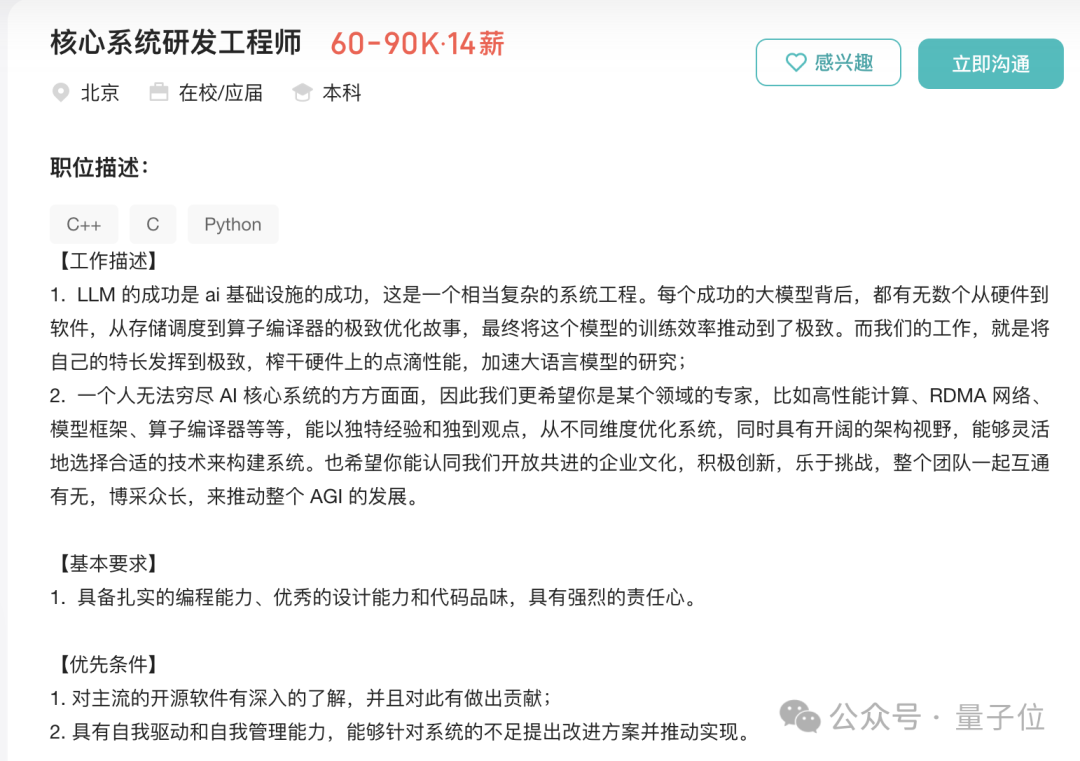
即使这是核心系统的研发工程师,即90K和14薪水,即126万工资,但仍开始本科生。
实际上,不仅新的招聘遵循了这一组合,现有的DeepSeek团队也很年轻。
去年年初,当DeepSeek推出V2时,尽管它不像R1那样受欢迎,但它通常不会被天空溅起,但它在行业中也引起了很多关注。
当时,人类人类杰克·克拉克(Jack Clark)认为,在DeepSeek V2的背后,必须有一群“不可预测的巫师”。
但是很快,DeepSeek的创始人Liang Wenfeng在一次采访中否认了猜测。
没有不可预测的巫师。他们是一些顶级大学的新毕业生,Bo Si,Bo五个尚未毕业的实习生,一些年轻人只毕业了几年。
当前的V3和R1也是如此,新鲜的毕业生和学生,尤其是青比的新毕业生非常活跃。
他们中的一些人于2024年在DeepSeek研究了研究,而新鲜和热门的博士学位论文只是在另一端发表了评论。
对于诸如DeepSeek之类的关键创新,提出了新型的关注MLA(长期关注),GRPO加强学习对齐算法等,它们都是年轻人,毫无例外。
他们中的一些人只是实习了一段时间,并取得了重要的结果。
例如,ICLR 2025收到的论文将通过加强学习和蒙特卡洛树搜索来开发。 GPT-4只有25%。
本文的第一作者是DeepSeek的高级实习生。去年上半年,他在DeepSeek实习。该论文第一次出版只是实习期的结束。现在作者已经开始阅读博客。

这也可以解释为什么DeepSeek愿意给实习生的每日薪水。
DeepSeek大胆地采用了没有经验的年轻人的原因。 Liang Wenfeng还在采访中解释了。
如果您追求短期目标,找到一个经验丰富的人是正确的。但是,如果您长期看,经验并不那么重要,基本的能力,创造力和爱情更为重要。
招募人员的原则是看我们的能力,而不是看经验。
回顾DeepSeek的招聘需求,在表面上找到“三个无限”位置并不难,这实际上并不简单。
您不仅必须对相关编程语言有充分的理解和掌握,而且有些职位甚至需要在知名比赛中获得出版物或奖励。

通过这种方式,尽管DeepSeek团队的年龄和资格较轻,但在能力和结果方面取得了非凡的表现。
正是这支年轻的团队将DeepSeek带到了Openai的同一张桌子上。
实际上,DeepSeek的年轻人不仅体现在年龄上。
没有劳动前的细分,每个人都可以使用计算资源
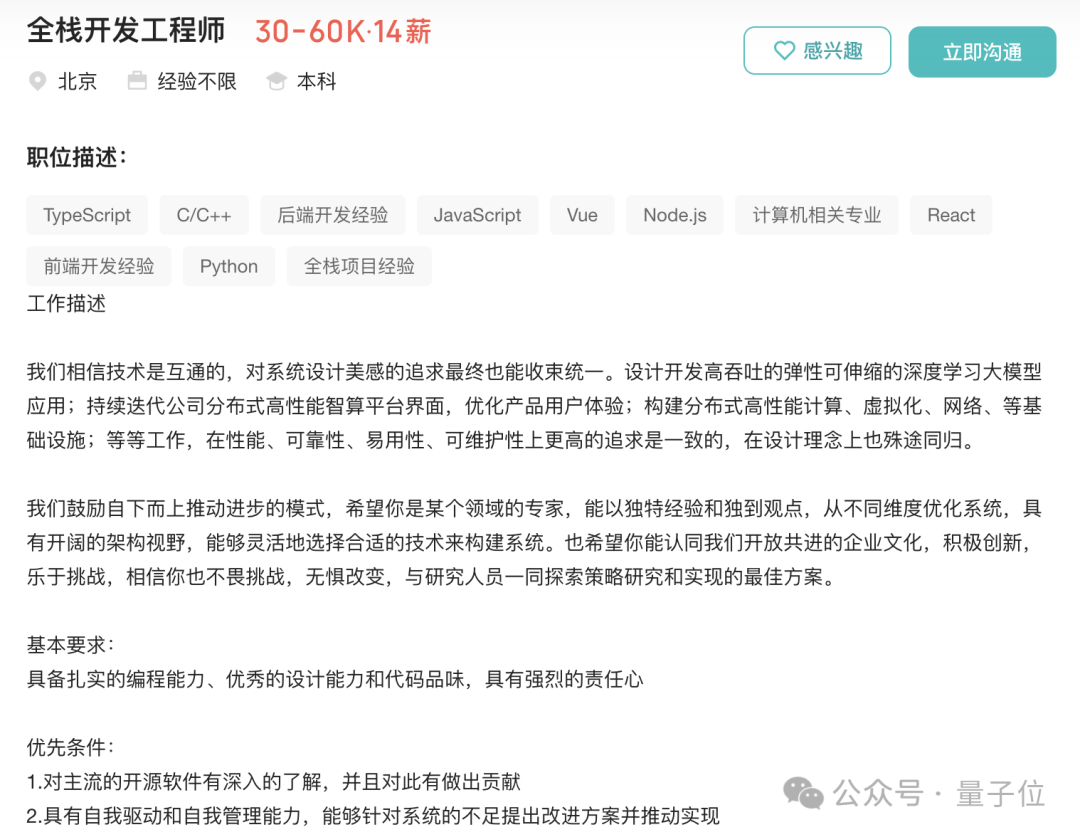
从邮政维度的角度来看,“完整的堆栈工程师”在DeepSeek的招聘清单中占据了相当大的比例。
关键是职位描述没有那么多规则。
DeepSeek的内部管理模式在招聘介绍中也侧重于寒意。
Liang Wenfeng介绍了员工在被DeepSeek录取并给他一个重要的事情后将开始“释放模式”,但没有KPI或干预,以便他可以找到办法并发挥自己的作用。
当然,在此过程中,人员和计算能力的需求将得到满足。
我们每个人都没有动员卡和人的上限。如果您有一个主意,每个人都可以在未经批准的情况下随时致电训练有素的集群卡。同时,由于没有层次结构和交叉部门,只要另一方也有兴趣,您也可以灵活地致电所有人。
前面提到的MLA注意机制就是一个很好的例子。出现的机会是偶然的。
Liang Wenfeng介绍了,在总结了注意建筑的一些主流变化之后,年轻人突然想设计替代方案。
面对这种“事故”,DeepSeek提供了全力支持,因此,一个团队专门组成了一个团队,将这个想法变成了几个月的现实。
如果您继续深入研究,DeepSeek的内核看起来也年轻和理想主义。
Liang Wenfeng说,DeepSeek的目标非常明确,这不是进行垂直类别或应用,而是进行研究和探索。
在许多大型企业家指导应用的一般趋势下,这种选择可能很困难。
但是,从DeepSeek的角度来看,大型模型不能总是依靠给予者来赚钱,而是促进真正的技术创新。
这解释了DeepSeek团队从另一个角度年轻的主要原因 -
如果经济利益不给予优先考虑,创新需要信仰作为支持,而年轻人无疑是最自信和充满活力的团体。
拥有数万GPU并不罕见,价格并不罕见
当然,有了理想,您必须对此进行投资。实际上,DeepSeek在才能和计算功率资源方面非常有效。
我们之前还提到,DeepSeek已经建立了一个迹象,即每个人都可以用于计算资源,并且在招聘中也清楚地提到了相关的计算能力支持。

那么,DeepSeek实际上有多少计算电源资源?
通过挖掘著名的半导体研究机构半分析发布的分析报告,我们可以进一步学习:
(根据该报告,DeepSeek拥有大约50,000个Hopper GPU,其GPU投资超过5亿美元。
(Hopper GPU是下一个代表NVIDIA进行高性能计算和AI的新代数据中心gpu架构。其名称是纪念已故的计算机科学家Grace Grace Hopper))
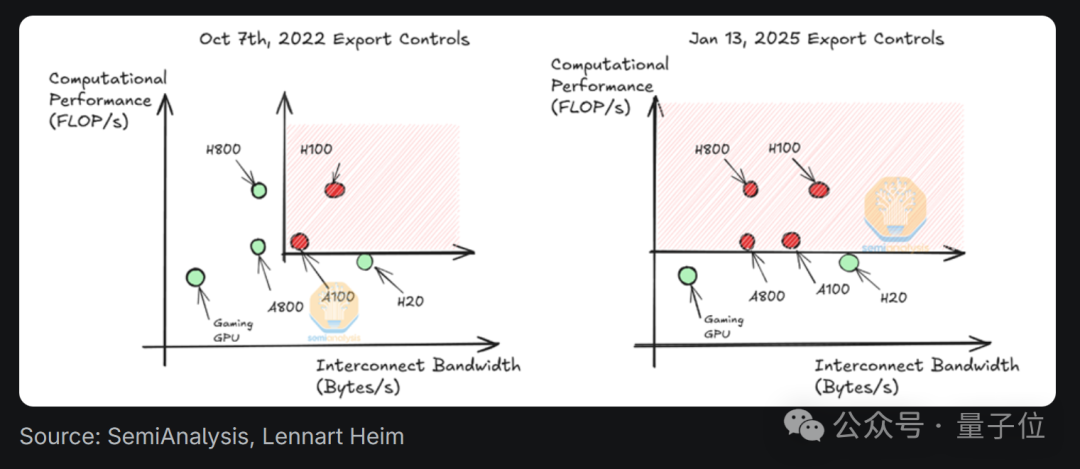
但是,该报告还提醒50,000个料斗GPU≠50,000 H100。
具体而言,该报告推测DeepSeek的大约10,000 H800和10,000 H100,还订购了更多的H20。
这些GPU将在公司的量化(在公司后面)和DeepSeek之间共享。
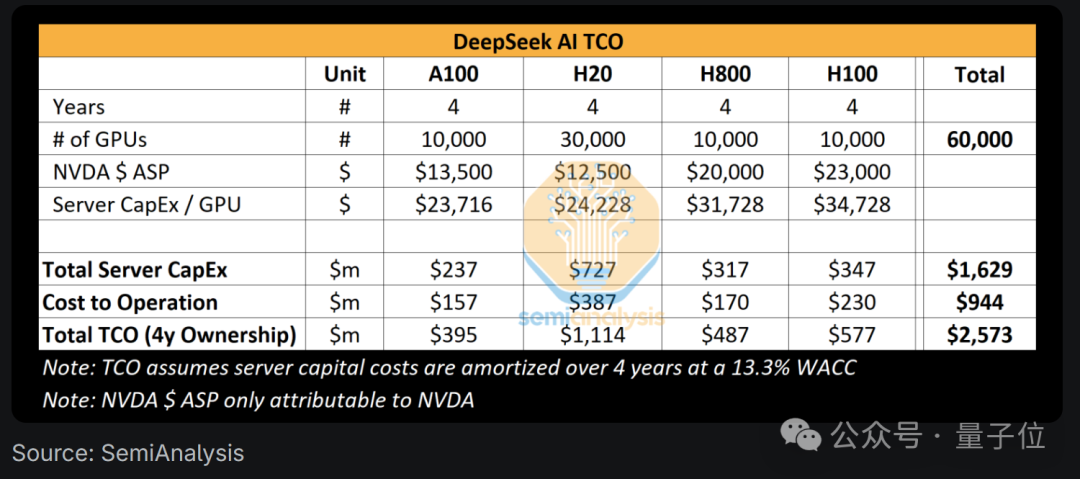
同时,报告还解释了先前的“ DeepSeek V3培训成本仅为600万美元”。
这个数字实际上是一个。这只是GPU在培训过程中的成本,仅是模型总成本的一部分。
不包括重要部分,例如研发成本和硬件本身的总体所有权。
具体而言,报告分析认为,在硬件上的DeepSeek的支出远远超过5亿美元,为了开发新的结构,团队需要花费大量资金和计算能力。
例如,DeepSeek成本降低的MLA机制,在早期阶段投入了大量的人力和GPU计算的时间,这花费了几个月。
当然,这项投资也得到了奖励。在随后的研究和开发中,每个查询所需的KV缓存降低了约93.3%。
因此,即使使用了前面提到的硬件和人工成本,DeepSeek在成本效益方面仍然具有很多想象力。
不,春节假期尚未结束。最近几天,主要的云计算(例如腾讯云,阿里巴巴云和百度智能云)一直在抢走DeepSeek模型。
能够打开天空价格的价格并不奇怪。

参考链接:
[1]
[2] 〜.html?ka =公司 - 乔布斯
[3]
