机器释放的心脏
机器心脏社论部
在追求人工智能局限的道路上,“更大的手段更强大”似乎已成为共识。尤其是在数学推理领域(被视为人工智能的最终挑战),通常认为需要大量数据和复杂的强化学习来实现突破。但是,上海Jiotong University的最新研究给出了一个令人震惊的答案:只有817个精心设计的样本可以使模型能够超越数学竞争级问题的许多当前最新模型。这一发现不仅挑战了传统的认知,而且还揭示了一个我们可能会忽略的事实:大型模型的数学能力可能总是存在的,关键是如何唤醒它。

1。从规模竞争到范式创新
在Openai推出了O1系列并在推理能力竞赛中发射了第一枪之后,DeepSeek-R1以其惊人的数学推理能力震惊了该行业,引发了全球复发的狂热。主要公司和研究机构遵循相同的范式:使用较大的数据集并结合更复杂的强化学习(RL)算法来尝试“教”该模型如何推理。
如果将完全预先训练的大语言模型与才华横溢的学生进行比较,则主流RL缩放方法就像不断培训和奖励学生,直到他解决各种复杂的数学问题为止。毫无疑问,从Claude到GPT-4,从O1-preiview到DeepSeek-R1,这一策略无疑带来了重大的结果,这是每一个绩效跳跃的背后是训练数据量表的指数增长以及强化学习算法的持续优化。 。
但是,在这场看似无尽的数据竞赛中,上海北大大学的研究团队提出了一个发人深省的问题:如果这个“学生”在培训前阶段掌握了所有必要的知识,我们真的需要它可以进行大量数据集被培训?还是他只能通过细致的指导来激活他的潜在能力?
他们的最新研究,豪华轿车(少于推理)给出了一个令人震惊的答案:只有817个精心设计的培训样本和简单的监督微调,豪华轿车完全超过了仅使用817个精心设计的培训样品的100,000级数据的培训。主流模型,包括O1-Preview和QWQ等顶级玩家。这种现象的“少”现象不仅挑战传统的认知“更大数据=更强的推理”,而且还揭示了一个可能被忽略的事实:在AI推理能力的突破中,方向可能更强大。更重要。
实验结果毫无疑问地证实了这一点。与传统方法相比,在竞争级的美国数学竞赛邀请赛(AIME)测试中,豪华轿车的准确性从6.5%飙升至57.1%(以Numina-Math为例)。更令人惊讶的是豪华轿车的概括能力:它在10个不同的基准测试中实现了40.5%的绝对性能提高,超过了经过100倍数据训练的模型。这一突破直接挑战了传统观点,即“监督微调主要导致记忆而不是概括”,证明高质量的小规模数据可以刺激LLM的真实推理能力,而不是效率低下的大规模培训。
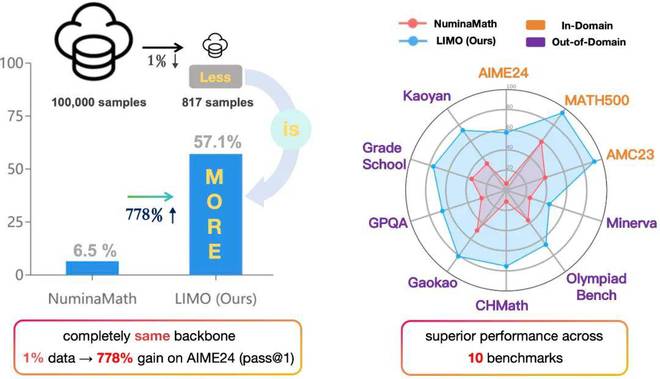
与使用100,000个数据的Numinamath相比,Limo使用不到1%的数据取得了重大进展,并且在各种数学和多学科基准中表现良好。
2。少更多:从一致到推理的飞跃

由于在2023年提出了利马(更少的对齐),因此该行业逐渐意识到,“更少的是更多”不是对齐任务中的空谈。利马只有1,000个高质量的数据,允许大型语言模型学习如何生成与人类偏好相匹配的对话。这一发现颠覆了传统的看法,即“模型培训需要大量数据”。
但是,将这个想法扩展到数学推理领域面临着独特的挑战。与简单的对话格式不同,数学推理被认为是一种复杂的认知技能,需要大量的练习和培训才能掌握。这就像教学生解决问题一样:教他以礼貌的语气说话,而教他解决复杂的数学问题的困难显然是无与伦比的。因此,一个关键的问题是:适用于推理的原则越少吗?
豪华轿车的研究给出了积极的答案,并揭示了实现这一突破的两个核心前提:
基于这两个点,豪华轿车团队提出了一种新的理论观点:大型模型的推理能力本质上是“潜在”而不是“缺少”。传统的RL缩放方法是试图“训练”模型以获得新的能力,而豪华轿车则重点是如何有效地“激活”该模型已经具有的功能。研究人员提出了豪华轿车假设的基于这两个主要基础:
有了足够的合理知识库,只需要几个高质量的示例来通过没有大量数据的推理链来激活模型的潜在推理能力。
如果该模型在训练前阶段获得了大量的数学知识,那么我们可能只需要以少量但精心设计的例子来“唤醒”这些睡眠能力。这就像教授掌握所有必要知识但不知道如何有效应用它的学生一样。
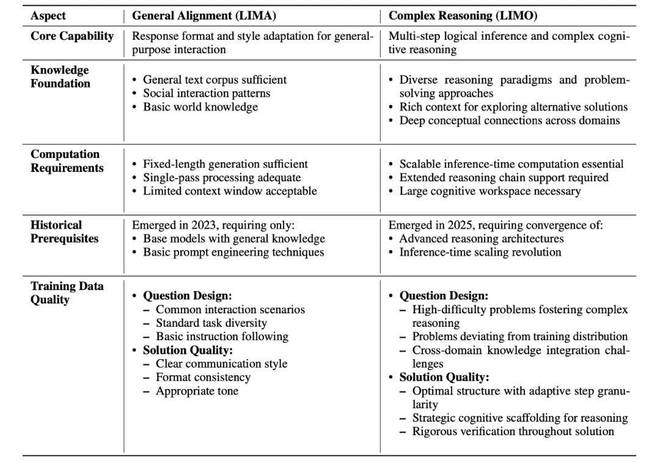
利马与豪华轿车:“较少的是更多”现象的比较分析
豪华轿车与RL缩放:两个推理范例的碰撞
增强学习扩展(RL缩放)
以Openai的O1系列和DeepSeek-R1为例,RL缩放方法通常会通过大规模的增强学习训练来增强模型的推理能力。此方法通常依赖大量数据和复杂的算法。尽管它在某些任务上取得了显着的结果,但它具有局限性:它将推理功能的改善视为需要大量计算资源的“搜索”过程。
豪华轿车的新观点
相比之下,豪华轿车(更多用于推理)提出了一个不同的理论框架,该框架认为推理能力隐藏在预训练的模型中,关键是如何通过精确的认知模板刺激这些内在能力。这种转变将把研究重点从“训练新能力”转变为“激活潜在能力”,从而强调了方向的重要性。
豪华轿车的核心假设是,有了足够的合理知识库,可以使用少数高质量的示例来激活模型的潜在推理能力。该理论不仅重新定义了RL缩放的位置,还将其视为找到最佳推理轨迹的一种手段,还为整个领域的研究提供了一个新的思维框架。
研究意义
目前,由DeepSeek-R1表示的RL缩放方法逐渐成为主流。豪华轿车研究的意义是提供一个更重要的观点:大型模型本身的推理能力在内部存在,关键挑战在于如何找到最佳的路径。
这种洞察力不仅重新定义了RL缩放作为找到最佳推理轨迹的实现,而且更重要的是,它导致了从“训练新能力”到“激活”潜在能力的全新研究范式。这种转变不仅加深了我们对大型模型推理能力的理解,而且还为更有效的能力激活方法提供了明确的方向。
豪华轿车和RL缩放之间的比较揭示了不同的途径和改善推理能力的想法。豪华轿车提供了更基本的理解,并指出了未来研究的方向:不再是无尽的数据堆,但是更多的关注是如何有效地激活该模型已经具有的功能。
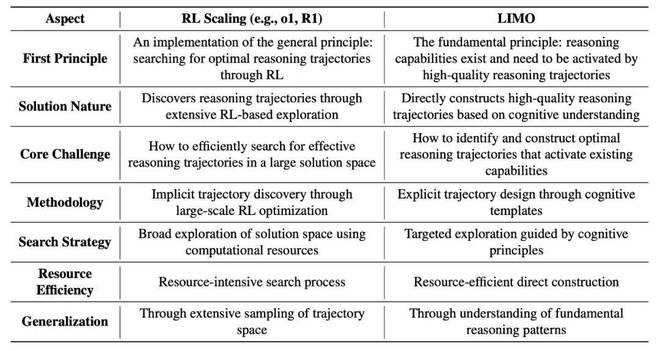
豪华轿车和RL缩放方法的比较分析
实验验证:破坏性结果
豪华轿车的理论得到了实验结果的强烈支持。只有817个数据,豪华轿车超过了主流OpenAI-O1-Preiview和QWQ模型。与自己的基本模型(QWEN2.5-32B-构造)相比,它的性能得到了显着提高,并且已经击败了Opthoughts和Numina Math,它使用了数十万个数据。
豪华轿车在传统评估任务中取得了突破。在数学竞赛级别的AIME24测试中,豪华轿车的准确性赢得了57.1%的精度,远远超过了QWQ的50.0%,O1-Preview的精度为44.6%。在Math500测试中,豪华轿车的惊人得分为94.8%,超过了QWQ(89.8%)和O1-preview(85.5%)。这些数据清楚地表明,少量但精心设计的培训数据确实会导致超出传统方法的性能改进。
豪华轿车的概括能力在各种跨域测试中也很出色。在奥林匹克数学测试(OlympiaDbench)上,豪华轿车的准确率为66.8%,远远超过了QWQ的58.5%。尽管豪华轿车数据集不包含任何中国数据,但在中国大学入学考试数学(Gaokao)测试中也达到了81.0。分数%,比QWQ领先80.1%。这种广泛的适用性使我们发现豪华轿车不仅记住训练数据,而且可以真正掌握数学推理的本质。
总体而言,在所有测试中,豪华轿车的平均准确度均为72.8%,明显领先于O1-preiview(61.1%)和QWQ(66.9%)。这个结果不仅证实了“少更多”的假设的正确性,而且还指出了整个行业的新开发方向:也许我们不需要无休止地堆积数据和计算能力,而且应该更多地考虑如何了解如何激活模型您已经拥有的能力。

在多个基准上的豪华轿车和其他模型的性能比较
3。数据的三重密码
基于豪华轿车假设,我们构建了高质量的数据集,并通过实验揭示了三个关键因素,这些因素通过少量数据提高了大型模型的推理能力,即推理链的质量,问题难度和培训前知识的质量:
推理链的质量:细节决定成功或失败
想象一下,您正在教学生解决问题。如果他只是告诉他答案,他可能永远不会真正理解其背后的逻辑。但是,如果您详细说明每个步骤的推理过程,甚至让他自己验证每个步骤的正确性,他将逐渐掌握解决问题的本质。豪华轿车的研究发现,推理链的质量对大型推理能力具有决定性的影响。
实验表明,高质量推理链(L5)和低质量推理链(L1)之间的性能差距高达15个百分点。高质量的推理链不仅在逻辑上清晰且完整,还包括自我验证链接,以确保推理的正确性。低质量的推理链通常简单地列出了步骤,并且缺乏详细的逻辑推导。这表明,设计良好的推理链不仅可以帮助模型更好地理解问题,而且还可以提高其推理准确性和泛化能力。
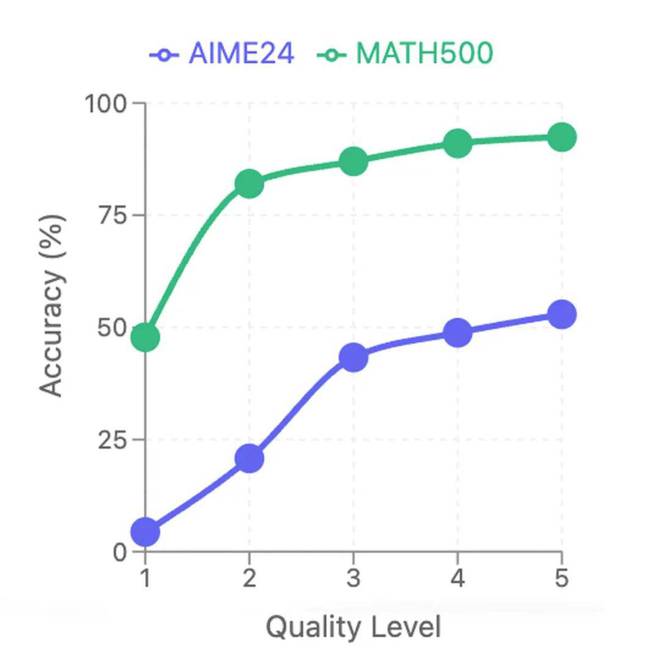
通过在AIME24和MATH 500上通过不同质量水平进行推理链训练获得的模型的性能(1-5)
问题困难:挑战潜力
如果推理链是解决问题的“路线图”,那么问题本身就是刺激模型潜力的“催化剂”。豪华轿车的研究发现,高难题的问题可以显着提高模型的推理能力。研究人员创建了三组不同的难度级别问题:Simple-500,Complex-500和Advanced-500,以为他们和火车模型构建高质量的推理链。实验表明,接受高级500训练的模型(竞争水平问题)的基准准确性比用简单500训练的模型(简单的数学问题)高16%。
背后的逻辑是,更复杂的问题需要更长的推理链和更深入的知识整合,从而迫使模型在推理过程中充分利用其预告片的知识。这就像让学生不断挑战更高级别的问题一样,他的问题解决能力也将相应地提高。因此,选择更具挑战性的培训数据可能是提高模型推理能力的有效策略。
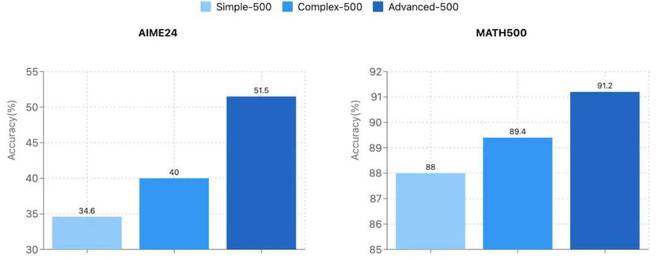
在不同的难度集后,在AIME24和MATH500上训练的模型的性能
培训前知识:基本决定高度
最后,豪华轿车的研究突出了培训知识的重要性。在数学推断任务中,具有相同架构但不同验证的数据质量的两个模型的实验比较表明,QWEN2.5-32B实验(较高的数据质量)的性能明显好于QWEN1.5-32B-。聊天,AIME24的准确率提高了47个百分点。
这表明该模型的推理能力在很大程度上取决于其在训练阶段所掌握的知识。如果该模型在训练阶段已经接触并理解了许多数学知识,则仅需要少量的高质量示例来激活其推理能力。相反,如果预训练知识不足,即使大量数据用于微调,效果可能会受到限制。因此,提高预训练数据的质量和多样性可能是改善未来模型推理功能的关键。

使用豪华轿车数据与具有相同体系结构和不同预训练数据的微调模型,两者之间的性能差异很大
4。案例和定量分析:豪华轿车的出色表现
在特定案例分析中,豪华轿车表现出了出色的推理能力。图5比较了QWEN2.5-32B-INSTRUCT,DEEPSEEK-R1和LIMO产生的响应。尽管豪华轿车只使用了817个训练样本,但其性能与DeepSeek-R1相当,甚至在某些方面更好。豪华轿车不仅能够反思自己,而且在长链推理中保持了高度的精度。例如,豪华轿车在验证其陈述时表现良好:“等待一分钟,24分钟为0.4小时?60分钟是1小时,所以24分钟是24/60,即0.4小时。”在复杂的数学推理任务中,这种自我验证和纠正,豪华轿车的能力特别出色。

在同一问题下的不同模型的推理链和豪华轿车的比较
相比之下,QWEN2.5-32B-INSTRUCT在推理过程中显示出明显的局限性,无法纠正不准确的语句,并且在求解方程时未能交叉验证。这些结果不仅支持豪华轿车假设,而且还表明该模型可以通过少量的高质量训练样本给予强大的推理能力。
在定量分析中,我们发现,随着训练样本的质量提高,该模型会产生更长的响应,更多的行计算和更多的自我反射过渡词,例如在推理过程中(例如,“等待一分钟”,“也许” “, “所以”)。这些高质量的模型可以分配其他计算资源来进行更深入的思考,从而在复杂的数学问题中表现良好。

定量分析不同质量推理链
5。未来前景:更少的无限可能性
尽管豪华轿车在数学推理方面取得了重大成功,但未来的研究仍然具有挑战性和机会。
1。场概括
将豪华轿车假设扩展到更广泛的推理领域是关键方向。尽管当前的研究主要集中在数学推理上,但高质量推理链的原则可能适用于科学推理,逻辑推理和因果推理。了解这些原则如何在范围内移动可能会揭示有效推理的共同模式。该探索需要调整质量评估标准和特定于现场评估框架的发展,以促进机器推理的理论系统。
2。理论基础
对豪华轿车成功的更深入的理论理解也至关重要。未来的研究应着重于形式化预训练的知识,推理计算和推理能力之间的关系。这包括研究有效推理所需的最低预定知识阈值以及数学模型的发展,以预测推理链的质量和数量之间的最佳平衡。这些理论基础可以指导更有效的培训策略,并提供有关机器推理性质的见解。
3。自动评估
开发自动化质量评估工具是另一个重要方向。尽管目前对推理链质量的手动评估有效,但它耗时且难以扩展。未来的工作应致力于创建可以根据我们提出的指标自动评估和提高推理链的质量的系统。这可能包括开发算法以自动增强现有的推理链并以最少的人为干预生成高质量的推理链,从而使豪华轿车的方法更加可扩展和访问。
4。多模式集成
跨模式推理为扩展豪华轿车原理提供了令人兴奋的前沿。由于实际推理通常涉及多种方式,因此研究视觉信息和结构化数据如何增强数学推理能力至关重要。该研究方向需要开发新的多模式推理链质量评估标准,并了解如何有效地整合到推理过程中。
5。实际影响
将豪华轿车原则应用于现实生活中的情况值得特别关注。未来的工作应致力于将这些方法应用于教育,科学研究和工业应用中的实际问题。这包括为特定领域开发专用版本的豪华轿车,并创建工具,以帮助人类专家生成高质量的推理链。这些应用可以显着影响我们如何解决各个领域的问题。
6。认知科学桥
最后,整合认知科学见解可以为改进提供宝贵的方向。了解豪华轿车的推理模式与人类认知过程之间的相似性可能有助于制定更有效的推论策略。这包括研究不同的推理方法如何影响模型的性能和概括能力,并将认知科学原理纳入推理链的设计中。这样的研究不仅可以改善人工智能系统,而且还可以提供对人类推理过程的见解。
这些未来的方向共同致力于加深我们对大语言模型中有效推理的理解,同时扩大其实际应用。通过探索这些路径,我们可以朝着开发更复杂,高效且广泛适用的推理系统方面,以更好地满足各个领域的人类需求。
豪华轿车的研究不仅挑战了传统的认知“更大更强”,而且还揭示了大规模模型推理能力的基本机制。通过少数高质量的训练样本,豪华轿车成功地激活了模型的隐藏功能,展示了“少的是更多”的惊人效果。这一发现不仅指出了未来研究的方向,而且为我们提供了一个新的观点,使我们了解了大型模型的能力。
将来,随着豪华轿车假设的进一步验证和扩展,我们有望看到在各个领域广泛使用的更有效和准确的推理系统。这不仅将促进人工智能技术的发展,而且还将对我们解决复杂问题的方式产生深远的影响。豪华轿车的成功可能只是人工智能推理能力觉醒的开始,而前方的道路充满了无限的可能性。
