鱼和绵羊从奥菲寺(Aofei Temple)在西风中
量子位|官方帐户QBITAI
刚才,香港大学Bytes联手发布了最新的视频生成模型,这使Waiguo网民称其为疯狂。
有些人甚至直接去RIP营销,Tiktok用户和YouTube创作者。

您敢相信以下场景不是来自OPPA电视连续剧,而是来自AI!

创建它的新模型称为Goku,这是一系列基于整流的流动变压器的模型,专为图像和视频的联合生成而设计,并支持Wensheng视频,图片视频和Wensheng Pictures。
还有Goku+,这是视频广告的基本模型。这位官员直言不讳地说:“它可以制作广告视频,比原始视频低100倍。”

Goku手头生成产品广告和捏。无论是展示食物还是化妆品,它都是非常现实和自然的,角色的表情很难看到缺陷:


食物广播产生的以下视频使人们无法说出真相或错误:

取出带有白色背景的皮鞋的照片,然后将它们移到摊位上以展示:

您甚至可以根据一个产品图片 +文本提示来生成具有字符的交互式解释视频。
迅速的:
那个女人站在五颜六色的米妮(Minnie Mouse)产品的后面,她的说话动画时的头轻轻摇摆。她的手放在桌子上,构建了产品,而她的嘴巴则以明显的重点张开并关闭,并传达了她的热情和详细的解释。相机保持稳定,捕捉了她的富有表现力的齿轮以及在她面前的产品的充满活力的设计。表达。她的手放在桌子上,构图,嘴巴张开并闭合,明确地张开了,传达了她的热情和详细的解释。相机保持稳定,捕捉了她的表现力手势,并在您面前对产品的明亮设计。

可以举办各种场景,时装秀没有问题:

在定性和定量评估中,Goku文本对图像生成的遗传学得分为0.76和DPG基座得分83.65;文本到视频一代Vbench得分为84.85,一口气赢得了新的Sota。
网民现在无法坐着,他们都说悟空和悟空+是颠覆性的。
将AI视频推到一个新的水平!
我手中的sora真的不太好吃。
基于流视频的基本模型
根据本文,悟空是基于流的视频生成的基本模型。

具体而言,悟空使用整流的流动变压器来实现图像和视频的联合生成。
它的核心组件包括图像视频关节VAE,变压器结构和校正流程公式 -
首先使用Image-Video将VAE组合在一起,将图像和视频压缩到共享的潜在空间中,然后使用Full Poastion Transformer对潜在表示形式进行建模,以实现统一的图像和视频生成。
校正流程公式基于RF(整流流)算法,并将其应用于Image-Video关节生成,该算法比扩散模型显示出更快的收敛速度和更强的理论特性。
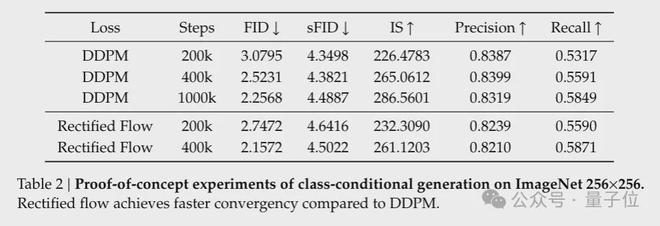
在培训方面,悟空采用了多阶段培训策略。
首先,对图形和文本语义对齐进行预训练,然后对联合图像视频训练进行,最后对不同模式进行微调,以逐渐提高模型的产生能力。
值得注意的是,为了培训悟空,研究人员还为大规模高质量数据集准备了有效的培训基础设施。
在数据方面,研究人员构建了大约3600万次视频和1.6亿张图像的大规模数据集,并使用了各种数据过滤和增强技术来提高数据质量。
为此,他们提出了一个全面的数据处理过程,包括基于审美评分的视频和图像过滤,基于OCR的内容分析和主观评估。
他们还使用多模式的大语言模型来生成信息密集型和上下文一致的标题,以用于视频和图像数据,并继续使用其他大型语言模型来完善它们,以提高其准确性,流利度和描述丰富性。
基础架构优化包括平行策略,细粒度激活检查点技术,容错机制以及由Doubaao Big Model Team和香港大学共同提出的Bytecheckpoint Technology。
与基线方法相比,Bytecheckpoint在保存检查点上的性能提高高达529.22次,加载时的性能提高高达3.51次。
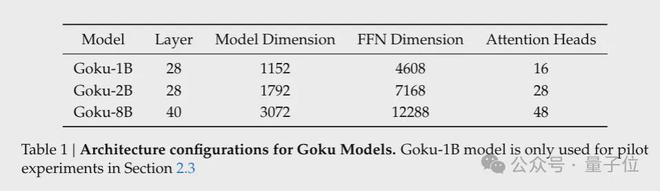
为了满足不同的计算要求和性能要求,研究团队提供了三种规模的模型:用于实验的GOKU-1B,标准版Goku-2b和Goku-8B。
不幸的是,该官员只发布了一份技术报告,并且暂时无法播放。网民等不及了
纸链接:
项目主页:
[1]
[2]
