
聪明的东西
作者Xu Yu
编辑Moying
在深深时代的时代,“开源”和“自由”已经超过了“参数数量”和“模型架构”之间的争议,并成为大型模型圈的新风暴中心。
Zhidongxi在2月15日报告说,在不到一个月的时间内,Baidu,DeepSeek,OpenAi,Google,Google,XAI等主流大型制造商强烈宣布,其封闭消息的高端AI型号将转向开放源计划免费。用户打开。这不仅表明大型模型竞赛已经进入了新的白热阶段,而且还是AI技术接近普通人的关键节点。
Baidu和Openai处于动荡状态,下一代新型号,深入搜索功能,免费提供的生成AI工具以及开源计划的破坏者。
2月14日,百度宣布将在接下来的几个月内推出Wenxin Mockup 4.5系列,新一代的Wenxin Mockup将从6月30日开始开源。这也是Baidu的大型模型首次开放来源。同时,有市场报道说,百度还将发布今年Wenxin的大型模型的5.0系列。
前一天,百度正式宣布,从4月1日开始,Wenxin Yiyan将是完全免费的,用户可以通过PC和App免费使用最新的Wenxin系列模型。同一天,OpenAI首席执行官Altman在X上发布了一篇长期文章,正式宣布他计划在几周或几个月内发布新一代型号GPT-4.5(内部代号为“ Orion”)和GPT-5系统。
阿尔特曼(Altman)在文章中还写道,其免费的chatgpt层也将包括对GPT-5的无限聊天访问。换句话说,用户不仅可以免费使用Chatgpt的搜索功能,还可以免费使用OpenAI的最高级模型。
本月初,Google还宣布将开设其最新的Gemini 2.0系列模型。马斯克在2月14日的一次采访中说,它计划在一到两周内推出新一代AI Model Grok 3,其性能可能会超过GPT系列,并且很可能会继续其开源战略。可以说,上述大型模型制造商已经全力以赴,并准备在这个关键时刻进行大型战斗,没有人会屈服于其他任何人。
此外,百度和OpenAI都计划逐渐打开与搜索相关的功能。
Openai表示,深入的研究功能最初将为每月两次提供免费使用机会,每月10次,所有Pro用户都可以在移动和桌面应用程序上使用此功能。 Baidu Wenxin Yiyan的深入搜索功能现已在PC侧可用,并且将于4月1日免费提供,并且该应用程序将很快启动。
直到今天,大型模型的自由,开源和开放的能力与技术突破带来的培训和推理成本的降低是不可分之的。
2月11日,百度创始人罗宾·李(Robin Li)在阿联酋迪拜的世界政府峰会上分享了“过去,当我们谈论摩尔法律时,每18个月一次,绩效水平或价格被削减了一半。谈论大型语言模型,可以说推论成本每12个月降低了90%以上。”
Openai首席执行官Altman最近在他的博客上也表达了类似的看法。根据他的观察,AI价格的下跌显着刺激了AI使用的增加。阿尔特曼说,使用AI的成本急剧下降,比上一年便宜90%,这也将帮助AI普及更多的用户。
使用大型模型越来越便宜,这不仅使小型和中型企业较低的本地部署大型模型的价格门槛较低,而且还可以开发出更合适的大型模型衍生品;它还将帮助公众使用AI产品。每天成为一个个性化的AI工具,AI产品和AI代理,并最终继续将活力注入整个AI生态系统。
那么,为什么敢于免费开放大型模型,如何提供具有成本效益的AI计算能力,而高级模型的能力是什么?通过拆卸百度的许多大型模型开发经验,我们找到了四个主要答案:自我开发的芯片,数据中心,AI计算平台以及对推理技术体系结构的深入优化。
1。Wenxin系列率先,深入的搜索功能将很快完全启动
半年多后,百杜·韦克森(Baidu Wenxin)的大型模型将不断升级。根据百度的最新消息,Wenxin Mockup 4.5系列将在接下来的几个月中连续推出。根据最近的市场新闻,Wenxin Big 5.0系列也将在今年内发布,这可能是今年下半年。
2023年10月,百度发布了Wenxin Mockup 4.0;去年4月,启动了Wenxin模型4.0工具版本;去年6月,在市场上正式推出了在4.0系列中表现出色的WENXIN MOCKUP 4.0 TURBO。根据4.0系列的发行速度,也许百度证实了罗宾·李(Robin Li)用实际行动所说的“创新本质”所谓的“创新本质”。他认为,创新的性质基本上遵循“如果您可以将成本降低一定数量,一定百分比,那么这意味着您的生产力增加了相同的百分比。”
一些内部人士破坏了Wenxin的大型型号4.5和5.0将显着提高其多模式功能。 OpenAI选择将各种AI技术和功能(例如O3推理模型)集成到即将到来的GPT-5 AI系统中。
同时,Wenxin的大型模型的视觉智能能力也是其主要特征之一。基于此,百度可以取代OpenAI和Google接管国内iPhone中Apple Intelligence的视觉智能。根据2月14日的外国媒体报告,百度将负责“国家版本”苹果情报公司提供的图像识别,检索和其他功能。
目前,Baidu的自发IRAG(基于图像的检索生成一代,基于图像的检索增强生成技术)结合了搜索增强(RAG)技术和视觉智能,可以检索,比较和参考大量图像资源从百度的搜索引擎,然后通过文本产生更高的质量和更现实的元素,以减少容易发生传统文学和传记技术的“幻觉”现象。
实际测量表明,具有IRAG功能的Wenxin Movie 4.0的生成字符和动作更符合文本描述和物理逻辑。此外,Wenxin Mockup 4.0支持一次生成多个AI图像。
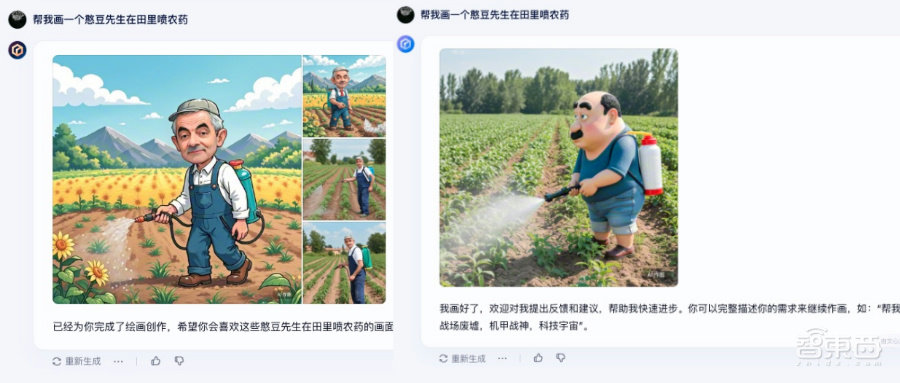
▲左图由Wenxin Mockup 4.0生成,右图像由Wenxin Mockup 3.5生成(照片来源:BAIDU)
从仅搜索增强的角度来看,就网络搜索的准确性和详细的内容描述而言,百度的生成AI工具Wen Xinyan比Openai的AI聊天助手Chatgpt更好。
让我们用唯一的解决方案给他们一个问题:“ 2025年中国的合法假期是什么?”

温辛发现今年是中期节日和国庆节假期,但雅特格普(Chatgpt)误解了中期节日的日期,并且没有发现连续度假的任何特殊情况。

让我给他们一个公开的问题:“在Nezha 2中,Nezha在制作Lotus Root Powder的过程中感到不舒服?”
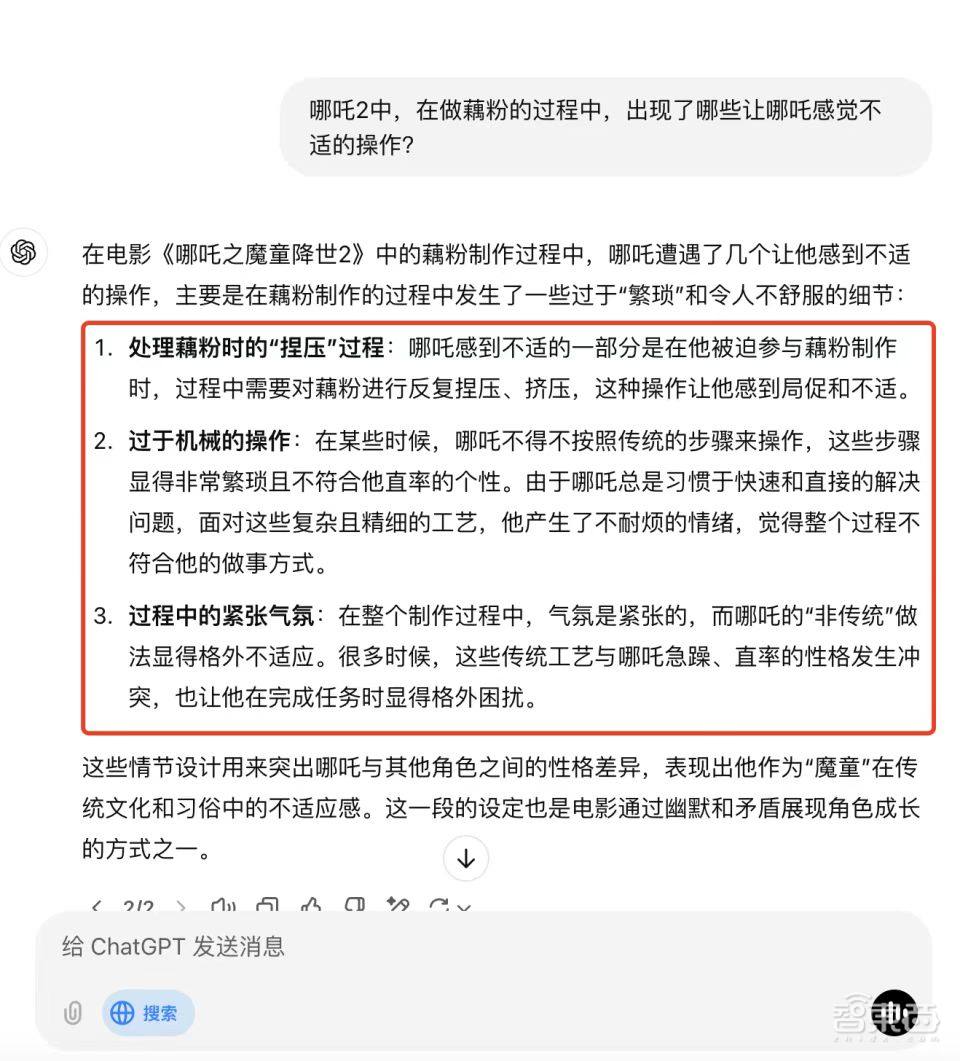
Chatgpt的在线搜索后产生的答案部分偏离了视频的事实,Wen Xinyiyan更准确地描述了视频的详细信息。
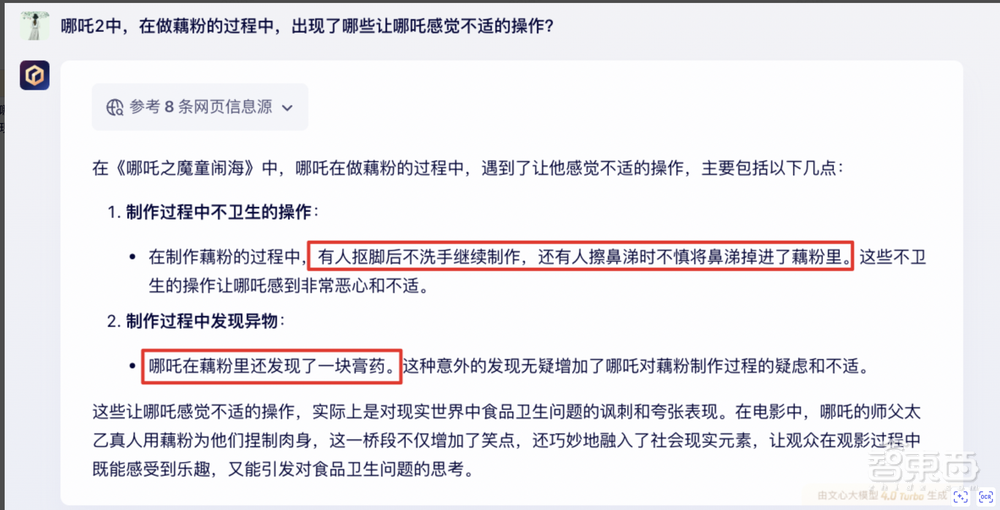
今年,Wen Xinyiyan预计将有能力获得一些专业和行业领先的内容。 2月13日,百度正式宣布,深入搜索功能是在Wenxin Yiyan Web版本上启动的,应用程序将同时升级。
基于此深入的搜索功能,Wen Xin Yiyan可以处理专业的咨询问题,例如人们的生计,企业家精神和经济分析。预计内容响应将达到专家级别,在一定程度上,这些响应会突破过去的利基搜索渠道和专业领域的分析。 AI搜索瓶颈,例如困难。
除了增强搜索功能外,百度还透露,Wen Xinyiyan的思想,计划和反思能力得到了进一步提高,因此他可以使用各种工具来更加“巧妙地”解决复杂的任务。
例如,当遇到无法简单处理的问题时,Wen Xinyiyan可以首先“读取”并“理解”用户上传的文档,然后搜索和分析相关内容,最后全面考虑私人领域资源和公共领域资源。信息以获得结果。
2.支持“核心”能力,大大提高了模型培训的效率
目前,尽管大型型号及其产品的性能得到了增强,但必须控制和减少开发和使用成本,以作为用户和免费的开源。这与整体计算能力结构的改进和优化是不可分之的。
第一个是计算能力“油门”,即芯片。
Baidu的自我开发的AI芯片“ Kunlun Chip”着重于大规模的模型培训和推理优化,推动了一系列文学和心脏模型,以缩短训练周期并降低发展成本。
现在已将其升级到第三代Kunlun Core P800。芯片采用XPU体系结构(可扩展的处理单元,可扩展处理单元),该架构比传统的CPU(中央处理单元)和GPU(图形处理单元)更灵活,并且可以基于特定的需求和应用程序。方案进行扩展和定制,从而减少浪费计算能力并提高计算任务的处理效率。
同时,Kunlun芯片P800的视频记忆规格比类似类型的主流GPU的视频记忆规格高20%至50%,这些类型的视频记忆规范可以更好地适应Moe(专家的混合)体系结构,节省计算功耗,并减少计算整个开发成本。
该芯片还支持8位量化技术,占据较少的视频记忆并保持高推理准确性。这意味着Qianfan DeepSeek多合一的单基机8卡还可以驱动大型型号,其中有671B的全型DeepSeek参数量。
第二个是计算能力“燃油箱”,即数据中心。
本月,百度智能云宣布完成Kunlun Core的第三代Wanka集群的建设,并计划将Wanka量表进一步扩大到30,000 kcal。
这个自发开发的Wanka群集可以形成比例效应,通过多任务并行处理,弹性计算电源管理等来降低闲置计算能力,以提高计算资源的利用率,从而降低总体计算能力成本模型培训。
将来,如果按计划将其规模从Wanka扩展到30,000卡路里,则规模效果将加剧,Baidu的云计算服务总成本可能会进一步降低。
下一步是计算功率“汽车基础”,即AI计算平台。
Baige平台是由Baidu Intelligent Cloud启动的高性能AI计算平台,该平台主要用于支持大规模的深度学习。它通过提高带宽有效性,降低耗散耗散能量,优化模型训练效率等来降低模型培训的总体成本。
根据百度的最新数据,Baige 4.0的带宽有效性已增加到90%以上。训练主流开源模型(通常使用MFU代表GPU的有效利用率)的群集MFU已增加到58%;模型训练的故障恢复时间已从小时水平降低到分钟水平,群集的有效训练率达到98%。
3。多平台创新,拉动模型推理成本以折断骨头
培训和推理都是模型开发及其应用中的关键链接,因此不足以减少模型培训的开销。模型推理的成本还需要通过优化的推理技术进一步控制。
截至发稿时,开源社区拥抱面孔的喜欢数量排名第一,这是国内模型DeepSeek-R1。 DeepSeek-R1是一种基于DeepSeek V3基本模型训练的高性能推论模型,重点是提高推论能力。
当主流大型模型制造商连接和蒸馏DeepSeek-R1和DeepSeek V3模型,并计划开源自己的高级模型,因此可以重写此模式。
但是,致电DeepSeek-R1和DeepSeek V3的价格很高。
目前,包括DeepSeek自己的平台,包括DeepSeek自己的平台,最便宜的价格是Baidu Smart Cloud Qianfan Big Model Platform。 R1的呼叫价格是官方DeepSeek问题的一半,V3的呼叫价格享受了官方DeepSeek发行价格的30%。
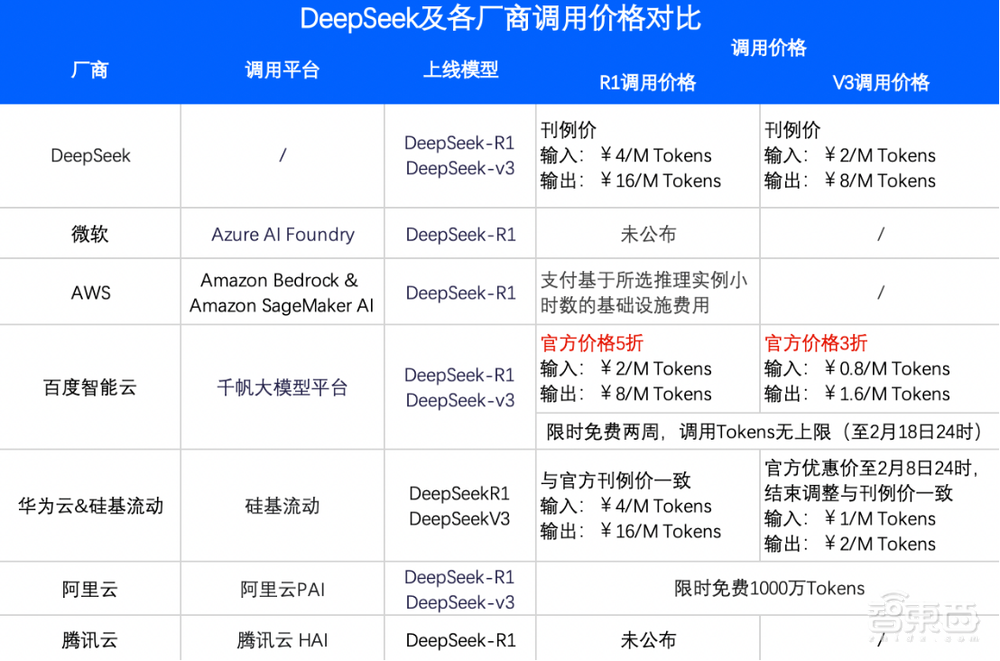
通常,百度主要通过优化以下三个主要部门的推理技术来降低推理成本。
1。Baidu智能云Qianfan Big Model Platform对DeepSeek Model MLA结构(多层次关注)进行了深入优化。一方面,它可以同步推理计算,通信和内存资源,另一方面,它在推理之前使用预填充/解码分离的推理体系结构预处理数据,以便该模型符合低潜伏期标准,可显着改善吞吐量并减少吞吐量并减少推理成本。
2。BaiduSmart Cloud Qianfan Big Model平台还通过增强系统容忍度,减少多回合对话和其他场景中的重复计算以及增强安全护栏的重复计算,从而降低了推理成本。
3。一些行业内部人士分析了百度桨式的深度学习框架,以及百度桨帕德尔的自我开发的平行推理和与定量推理相关的技术可以迁移到Baidu的AI工具(例如Wenxin Yiyan),以降低这些AII的aii ai Yiyan,以便降低这些AII的范围成本工具。
结论:国内和外国大型模型探索了人工智能的增量,情报加速了普及
作为免费开设AI模型的第一批大型模型制造商,Baidu和其他竞争对手开始了一轮新的大型Price War。但是这次,“节省成本”不仅是针对大型制造商本身的运营,而且更专注于促进AI技术。
Baidu继续探索芯片,模型培训和模型应用。通过技术创新,AI逐渐移至每个人都可以使用它的舞台,每个人都可以负担得起,每个人都可以很好地使用它。
将来,无论公司或个人是否从事AI行业,他们都将有机会在日常生活中获得AI技术,AI工具和AI模型的明智经验,然后加入AI作为AI的一部分,挥手挥舞着AI硬件开发人员,大型模型制造商,云服务提供商,个人和其他实体共同促进了AI生态系统的开放开发。
