mingmin来自奥菲寺
量子位|官方帐户QBITAI
用扩散模型替换自动进度,已经解决了大型模型的逆诅咒!
人民代表大会山房人工智能研究所和蚂蚁共同提议的llada(带有掩盖的大语言扩散)。
LLADA-8B在上下文学习中与Llama3-8b相当,并且超过了反向诗歌任务中的GPT-4O。
在大型语言模型的领域中,诗歌反转是一项特殊任务,用于评估该模型在语言模型中处理双向依赖性和逻辑推理的能力。
例如,让大型模型写下上一句话“爬上蓝天的白鹭线”。
通常,自回归模型(例如GPT)是从以下来推断出的上述性能始终不够好的。这是因为自回归模型的原理是使用序列中的先前元素来预测当前元素,即预测下一代币。
LLADA是基于扩散模型的双向模型,它自然可以更好地捕获文本的双向依赖性。
作者在摘要中指出,LLADA挑战了关键LLMS功能与自回归模型之间的固有联系。
这些研究也引发了很多讨论。
有人建议:
我们正在重构面具语言建模吗?
此范式在抹布和嵌入相似性搜索上的表现也更好?

值得一提的是,Llada训练了2.3万亿代币语料库,仅130,000 h800gpu,然后获得了450万个令牌。
前向口罩 +反向预测
本文的核心提出了一个问题:自动估计是实现LLMS智能的唯一途径吗?
毕竟,具有自回旋范式的LLM仍然有很多缺点。例如,一一生成代币的机制导致很高的计算结果,从左到右进行建模限制了反向推理任务中的性能。
这限制了LLM处理更长,更复杂的任务的能力。
为此,他们提出了Llada。通过向前掩盖和反向预测机制,该模型可以更好地捕获文本的双向依赖性。
该研究使用标准数据准备,预训练,监督的微调(SFT)和评估过程,将LLADA扩展到80亿参数。
使用130,000 h800 gpus在2.3万亿个代币上从头开始训练,然后对数据进行微调,以450万。
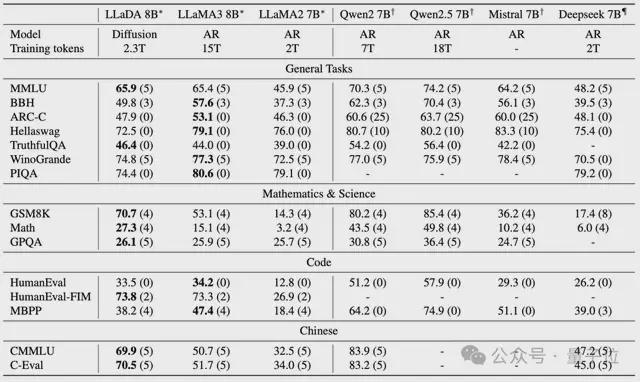
在语言理解,数学,代码和中文等各种任务中,表现如下:
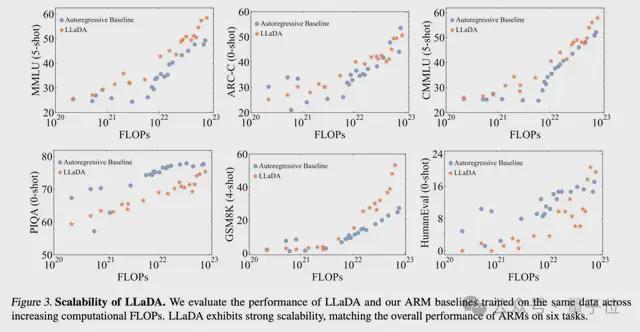
强大的可伸缩性:LLADA可以有效地扩展到10²³Frops计算资源,并且在六个任务(例如MMLU和GSM8K)上,它可以与接受相同数据训练的自我构建自动回归基线模型相媲美。
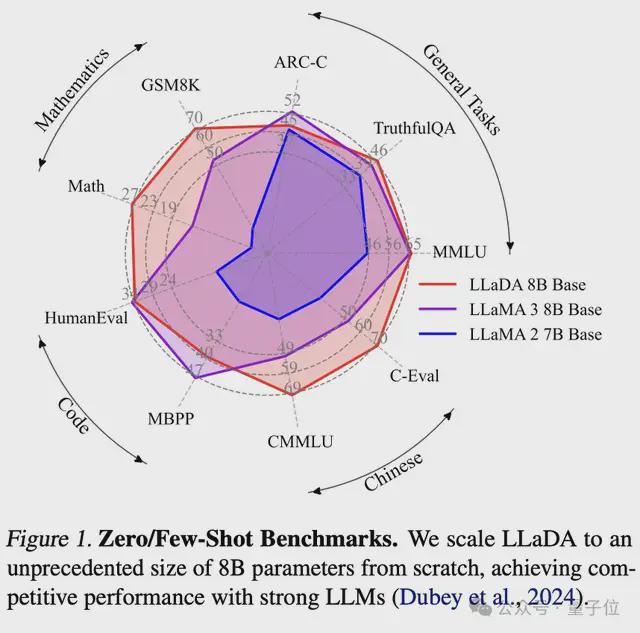
上下文学习:值得注意的是,LLADA-8B在几乎所有15个标准的零样本/小样本学习任务上超过了Llama2-7b,并且与Llama3-8B相当。
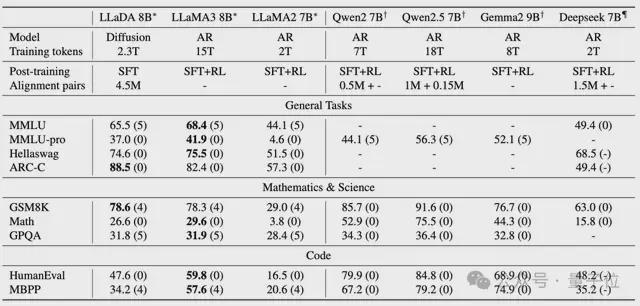
指令以下指令:LLADA显着增强了SFT之后的指示合规性,这在诸如多轮对话等案例研究中得到了证明。
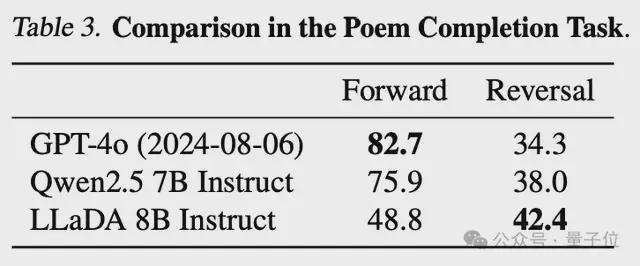
反向推理:LLADA有效地打破了逆转诅咒,并在向前和逆转任务上持续执行。特别是在扭转诗歌完成的任务中,Llada的表现要比GPT-4O更好。
LLADA将变压器体系结构用作掩模预测指标。与自回旋模型不同,LLADA的变压器不使用因果面具,因此可以同时看到输入序列中的所有令牌。
模型参数的数量与传统的大语言模型(例如GPT)相当,但是架构细节(例如多头注意的设置)略有不同,以适合掩盖预测任务。
向前掩蔽过程如下:
LLADA使用随机掩蔽机制随机选择一定比例的标记来掩盖序列X0作为输入序列(掩码),以生成带有部分掩码的序列XT。
每个令牌被掩盖的概率为t,其中t从[0,1]均匀地采样。这与传统的固定掩码比(例如BERT中的15%)不同,Llada的随机掩蔽机制在大规模数据上显示出更好的性能。
该模型的目的是学习一个可以根据部分掩码的序列XT进行预测的掩模图表。在训练过程中,该模型仅计算蒙版令牌上的损失。
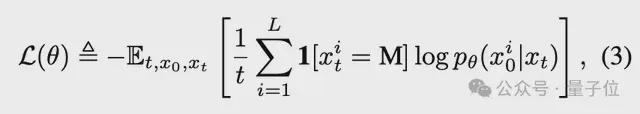
其中1 [·]是一个指示函数,表明仅计算出蒙版令牌的损失。
在SFT阶段,LLADA使用监督的数据(例如对话对,指令 - 响应对)进一步优化模型,以使其在特定任务上的性能更好。
对于每个任务,模型根据任务数据的特征进行微调。例如,在一项关于对话的任务中,该模型学习了如何根据给定的对话历史记录产生适当的响应。
在SFT阶段,该模型根据任务数据的特征选择性地掩盖了响应部分令牌,该数据允许模型更好地学习与任务相关的模式。
在推理部分中,在生成任务中,LLADA通过反向采样过程生成文本。从完全掩盖的序列开始,逐渐预测蒙版的令牌直到生成完整的文本
在抽样过程中,LLADA采用了各种策略(例如随机重新映射,置信度较低和半自动回调的重新映射),以平衡发电效率和质量。
在条件概率评估任务中,LLADA将根据给定的提示和部分掩码的响应评估模型的条件概率。这使Llada能够对各种基准任务进行绩效评估。
在不同基准上进行预训练的LLM的性能如下。
训练后不同基准的性能如下。其中,LLADA仅执行SFT,其他模型执行额外的强化学习对齐。
在逆转诗歌任务中,Llada超过了GPT-4O。
LLADA在多轮对话任务中的表现如下。较深的颜色代表了采样后期预测的令牌,较浅的颜色代表了在采样的早期阶段预测的令牌。

网民:我希望可以使用它
研究小组还发布了Llada的一些实际表演。
它可以解决普通的数学推理问题。

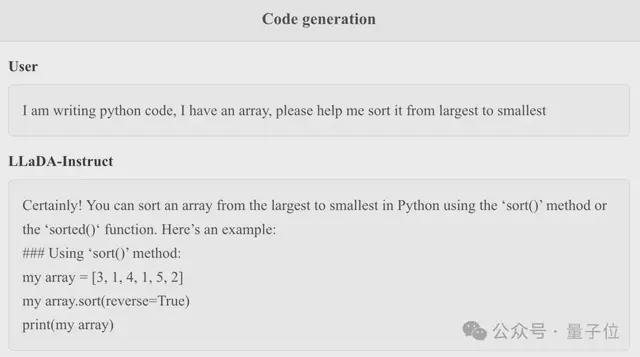
编程问题还可以。
一些外国网民说:这肯定会推动中国的AI研究,以更多地关注小型模型。但这并不意味着他们放弃扩大规模。

同时,有些人还评论说,这可能打开了一些混合模型。
有人提到,元与变压器和扩散相结合的工作也有类似的工作。

当然,有些人担心。以前提出了许多超越变压器的建筑,但是学术/工业社区都没有真正采用它们。
让我们期待跟进。

这项研究是由人工智能和蚂蚁小组的人民国会山丘陵学院共同提出的。相应的作者是李·宗教(Li Chongxuan),他目前是人民人大学希尔豪斯人工智能学校的副教授。当前的焦点是深入的生成模型,了解现有模型的功能和局限性,并设计有效且可扩展的下一代模型。
纸张地址:
项目主页:
