亨格来自奥菲神庙
量子位|官方帐户QBITAI
刚才,Jieyuexingchen和Geely Automobile Group已经开设了两个多模型!
总共有2个新型号:
多模式卷KING已开始开源多模型,其中Step-Video-T2V使用了最开放和宽松的MIT开源协议,可以随意编辑和商业应用。
(旧规则,github,脸部拥抱,魔术驱动以及文章的结尾)
在两种大型模型的研究和开发过程中,双方在计算功率算法,场景训练和其他领域的优势相互补充,“显着提高了多模式大型模型的性能”。
根据官方技术报告,这两种开源模型在基准测试中表现良好,他们的性能超过了国内外类似的开源模型。
Hug Face官员还转发了中国地区负责人的高评估。
专注于“下一个deepseek”,“巨大的sota”。
哦,是吗?
然后,在本文中,需要将Qubits分开为技术报告 +第一手测试,以查看它们是否值得他们的名字。

目前,这次的两个新开源模型已经连接到Yuewen应用程序,每个人都可以体验到它。
多模式卷King开源多模型是第一次
Step-Video-T2V和Step-Adio是第一个多模式的步进模型。
步骤VIDEO-T2V
让我们看一下视频生成模型step-video-t2v。
它的参数量达到30B,目前是世界上最大的开源视频生成模型。它在本地支持中文和英语双语输入。

根据官方介绍,Step-Video-T2V具有4个主要技术功能:
首先,可以直接生成具有204帧和540p的最大分辨率的视频,以确保生成的视频内容具有极高的一致性和信息密度。
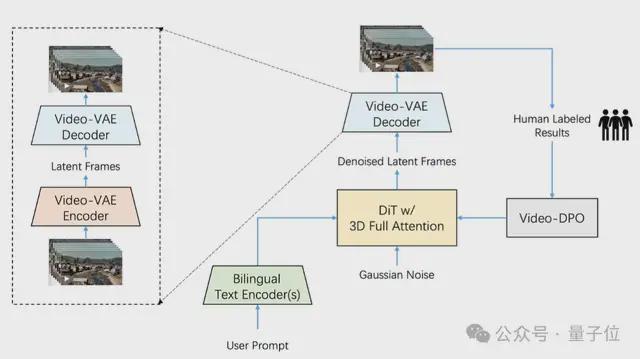
其次,高压比视频VAE是为视频生成任务设计和训练的。在确保视频重建质量的前提下,在空间维度中可以将视频压缩为16×16次,而在时间维度中可以压缩8次。
现在,市场上的大多数VAE车型都以8x8x4压缩。有了相同的视频框架,视频VAE可以额外压缩8次,因此培训和发电效率都提高了64次。
第三,Step-Video-T2V已针对DIT模型的超参数设置,模型结构和训练效率进行了深入的系统优化,以确保训练过程的效率和稳定性。
第四,详细介绍了一个完整的培训策略,包括培训前和培训后,包括培训任务,学习目标以及数据构建和筛选方法。
此外,Step-Video-T2V在培训的最后阶段介绍了视频DPO(视频偏好优化) - 这是用于视频生成的RL优化算法,可以进一步提高视频生成的质量并增强其合理性和稳定性视频生成。 。
最终效果是使生成的视频更加顺畅,更丰富的细节和更准确的命令对齐。
为了全面评估开源视频生成模型的性能,Step-Video-T2V-eval还发布了一个新的基准数据集,用于Wensheng视频质量评估。
该数据集也是开源的〜
它包含128个中国评论问题,旨在评估11个内容类别中生成的视频的质量,包括体育,景观,动物,组合概念,超现实性等等。
在其上的Step-Video-T2V-eval的评估结果如下图所示:
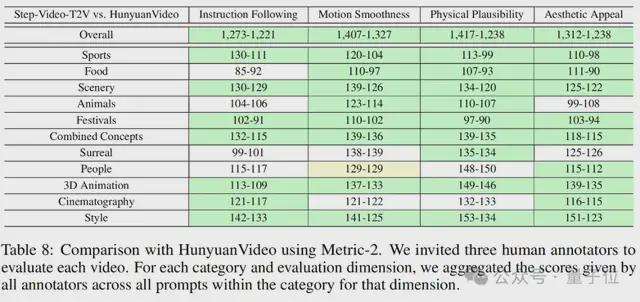
可以看出,在命令合规性,运动平滑度,身体合理性,美学等方面,Step-Video-T2V在以前的最佳开源视频模型中执行超出以前的最佳开源视频模型。
这意味着可以根据这个新的,最强的基本模型来研究和创新视频生成领域。
就实际结果而言,官方引入步骤飞跃:
生成效果,Step-Video-T2V具有强大的生成能力,在复杂的运动,美丽的角色,视觉想象力,基本文本生成,中文和英语双语输入和镜头语言中具有出色的语义理解和指挥合规能力,这可以是有效的。帮助视频创建者实现准确的创意演示。
你还在等什么?实际测试开始 -
按照官方介绍的顺序,第一级是测试Step-Video-T2V是否可以保持复杂的运动。
在以前的视频生成模型中,奇怪的场景将始终出现在各种复杂的运动剪辑中,例如芭蕾舞/国家标准/中国舞蹈,节奏体操,空手道和武术。
例如,突然出现的第三腿,交叉和融合的武器等是如此恐怖。
对于这种情况,我们进行了定向测试,并将其扔给Step-Video-T2V一块propt:
室内羽毛球法院以平坦的观看角度进行了固定的照片,记录了一个男人玩羽毛球的场景。一个穿着红色短裤和黑色短裤,拿着羽毛球球拍的男子站在绿色的羽毛球场中间。网跨场并将田地分为两个部分。该男子挥舞着他的巴掌,撞到了他对面的羽毛球。灯光明亮,均匀,图片清晰。
然后得到:
场景,角色,镜头,光和动作都在线。
一代屏幕包含“美丽的角色”,这是量子位对Step-Video-T2V发起的第二级挑战。
老实说,文学和传记图像模型的水平现在会产生真实的图片。就静态和本地细节而言,它绝对可以是假的和真实的。
但是,当视频生成时,一旦角色移动,仍然存在可识别的物理或逻辑缺陷。
和Step-Video-T2V的性能 -
提示:一个穿着黑色西装的男人,一条深色的领带和一件白衬衫,脸上有疤痕和庄严的表情。特写。
“没有人工智能。”
这是Qubit编辑部门的学生流传后,在视频中对小米的一致评估。
由于它具有直接面部特征,真实的皮肤质地和脸上透明的疤痕的“无AI感觉”。
它也是现实的,但是主角没有空无一人的眼睛和僵硬的表情的“没有AI的感觉”。
以上两个级别都可以使Step-Video-T2V保持在固定镜头位置。
那么,推,拉,摇晃,表现如何?
第三级测试Step-Video-T2V对运动镜的精通,例如推,拉,摇动,旋转和跟随。
要旋转它,它旋转:
要移动和跟随,它使您移动并关注:
不错!我可以在肩膀上携带Stenikon,然后去套装,成为移动镜的主人(不是)。
经过一些测试,结果将给出答案:
Step-Video-T2V确实是评估集的结果,并且具有出色的语义理解和教学合规性功能。
甚至基本的文本生成也很容易掌握:
Step-Audio
另一个开源模型Step-Adio是行业中第一个产品级开源语音交互模型。
在Stepeval-Audio-360基准测试中,Step-Audio获得了逻辑推理,创造力,命令控制,语言能力,角色扮演,文字游戏,情感价值和其他维度。最好的结果。

在诸如Llama问题和Web问题之类的五个主要主流公共测试中心中,Step-Audio的绩效超过了该行业中相同类型的开源模型,排名第一。
可以看出,它在HSK-6(中国能力考试CET-6)中的性能特别出色。
实际测试如下:
根据Step-Audio团队的说法,Step-Audio可以根据不同方案需求生成情感,方言,语言,唱歌和个性化样式的表达方式,并且自然可以与用户进行高质量的对话。
同时,它产生的声音不仅具有逼真的和自然的特征,高情绪智力等,而且还可以实现高质量的音调复制和角色扮演。
简而言之,在电影和电视娱乐,社交网络和游戏等行业方案中的应用需求得到了极大的满足。
踏上开源生态系统,滚雪球
如何说,这只是一个词:音量。
步骤是真实的,尤其是在他们自己的专业多模型方面 -
自出生以来,其步骤系列中的多模式模型一直是国内外主要权威审查,竞技场等的第一个经常游客。
我只看了过去的三个月,几次赢得了排名第一。

其次,步骤多模式不仅具有良好的性能和良好的质量,而且还具有很高的研发迭代频率 -
截至目前,Jieyuexingchen发布了11个多模式大型型号。
上个月,在6天内发布了6款模型,涵盖了语言,语音,视觉和推理的整个轨道,并进一步加强了多模式之王的标题。
本月,开源又有两个多模式。
只要您稳定这种节奏,就可以继续证明自己的身份是“家庭桶级的多模式播放器”。
自2024年以来,具有强大的多模式强度,市场和开发人员已经认识并广泛访问了步骤API,形成了庞大的用户群。
大量的消费产品,例如茶,数百种,已允许全国数千家商店与对大型Step-1V的多模式了解,探索大型模型技术在茶水饮料行业中的应用,并进行智能检查和AIGC营销。
公共数据表明,在大规模智能检查的保护下,平均而言,将数百万茶水交付给消费者。
步骤1V可以为每天平均每天的自我检查和验证时间占茶百卫主管的75%,从而为消费者提供更多的心态和优质服务。
独立开发人员,例如互联网名人AI应用程序“胃包”和AI心理治疗应用程序“ Linjian Chat and Healing Room”,最终选择了大多数国内模型的AB测试后选择了步骤多模式模型API。 。
(默默地:由于使用它,付款率最高)
具体数据表明,在2024年的下半年,踏步多模式API的调用数量增加了45倍以上。

让我们再次谈论它,这次,开源是Jieyue最好的多模式模型。
我们注意到市场和开发人员的声誉和数量已经累积。这次,此开源正在考虑随后从模型侧进行深入的访问。
一方面,Step-Video-T2V采用了最开放和最松散的开源协议,可以随意进行编辑和商业应用。
可以说“没有隐藏”。
另一方面,Jieyue说:“为了降低工业通道的门槛,一切努力”。
以Step-Audio为例。与市场上需要重新部署和重新开发的开源解决方案不同,Step-Audio是一组完整的实时对话解决方案,只要简单地部署它,它就可以直接进行实时通信。
您可以在零框架上享受端到端的体验。
经过一系列动作,围绕恒星和手中的多模式ACE的步骤最初形成了属于该步骤的开源技术生态系统。
在这个生态系统中,技术,创造力和业务价值是交织在一起的,共同促进了多模式技术的发展。
此外,随着步骤模型的持续研发和迭代,开发人员的快速和持续访问,生态伙伴的支持和共同努力,步骤生态系统的“滚雪球效应”已经发生并且正在增长。
中国的开源力量正在与力量并肩作用
曾几何时,当人们谈论开源大型模型领域中最好的东西时,他们脑海中出现的是梅塔(meta)的骆驼(Albert Gu)的Mamba。
现在,毫无疑问,中国大型型号行业的开源力量在世界范围内照亮,以其实力重写“刻板印象”。
1月20日,在蛇年春季前夕,是国内外大型众神的一天。
最引人注目的是,DeepSeek-R1是在这一天推出的。它的推理性能与OpenAI O1相当,但其成本仅为1/3。
影响力是如此巨大,以至于Nvidia在一夜之间蒸发了5890亿美元(约42.4万亿元人民币),创造了美国股票单日下降最大的记录。
更重要的是,R1升至成千上万人感到兴奋的高度不仅是出色的推理和价格合理的价格,而且其开源属性。
一块石头引起了一千个感觉。即使是OpenAI首席执行官Ultraman的首席执行官,也反复发表公开声明。
Ultraman说:“就开源加权AI模型而言,我们处于历史的错误方面。”
他还说:“世界确实需要开源模型,它们可以为人们提供很多价值。我很高兴世界上已经有一些出色的开源模型。”

现在,Step Leap还开始在开源的手中开放新的ACE。
开源是原始意图。
官员们说,开源Step-Video-T2V和Step-Adio的目的是促进大型模型技术的共享和创新,并促进人工智能的包容性发展。
Kaiyuan出现后,他在多个评论情节中展示了自己的技能。
在当前的开源大型型号桌子上,DeepSeek具有强大的推理,步进台阶重型模式以及各种不断发展的玩家...
它们的强度不仅是开源圈中最好的,而且整个大型型号也非常好。
- - 中国的开源力在出现后正在进一步。
以Jieyue的开源为例,正在突破的是多模式领域中的技术并改变了全球开发人员的选择逻辑。
许多具有活跃的开源社区(例如Eleuther AI)的技术VS已采取了主动性来测试“感谢中国开源”的逐步模型。

拥抱脸的头中国的负责人王·特岑(Wang Tizhen)直接指出,步骤将是下一个“ DeepSeek”。

从“技术突破”到“生态开放”,中国大型模型的道路越来越稳定。
话虽如此,这次Jieyue的开源双重模型可能只是2025年AI竞赛的脚注。
更深入地,它证明了中国开源力量的技术信心,并发出了信号:
在将来的AI模型世界中,中国的权力将永远不会缺席,也不会落后于其他人。
sep-video-t2v】】
Github:
拥抱面孔:
模型范围:
技术报告:
经验入口
【步骤原告】
Github:
拥抱面孔:
模型范围:
技术报告:
