DeepSeek完全使世界无法坐下。
昨天,马斯克以“地球上最聪明的AI”的现场直播 - 戈克3,声称他的推理能力比目前所有已知的模型都要多”。就推理测试时间分数而言,它也比DeepSeek更好R1和Ophai。由外界相信改变AI搜索字段。
如今,许多全球技术制造商,例如Microsoft,Nvidia,Huawei Cloud和Tencent Cloud,已连接到DeepSeek。网民还开发了新颖的方式来发挥巨大的讲述和预测彩票,他们的受欢迎程度直接转化为真钱,这帮助DeepSeek的估值一路上升,最高达到1000亿美元。
除了自由和易于使用外,DeepSeek还培训了DeepSeek R1型号,该车型与OpenAI O1功能相当,因为它在GPU中仅花费557.6万美元。毕竟,在过去几年的“ 100个模型战争”中,国内和外国AI模型公司花费了数十亿甚至数亿美元。 Gork 3的成本成为“世界上最聪明的AI”也很高。马斯克说,Gork 3培训的累积消费量为200,000个NVIDIA GPU(单个块成本约为30,000美元),而行业内部人士估计,DeepSeek仅超过10,000。 。
但是,也有一些人缴纳了DeepSeek的代价。最近,Li Feifei的团队表示,它花费了不到50美元的云计算成本来培训推断模型S1,该推断与OpenAI的O1和DeepSeek在数学和编码能力测试中的R1相当。但是应该指出的是,S1是一个中型模型,在deepseek R1的数百亿参数之间存在差距。
即便如此,巨大的培训成本差异从50美元到数十亿美元仍然使每个人都感到好奇。一方面,我想知道DeepSeek有多强大,为什么每个人都试图赶上甚至超越它,另一方面,培训大型模型的成本是多少?它涉及什么链接?将来,是否有可能进一步降低培训成本?
01 DeepSeek,“被一边概括”
在从业者的眼中,在回答这些问题之前,我们必须首先澄清一些概念。
首先,对DeepSeek的理解是“通过部分性的”。每个人都惊讶的是它的众多大型模型之一 - 推理模型DeepSeek -R1,但它也具有其他大型模型,并且不同大型模型的功能也不同。 557.6万美元是其在其通用模型DeepSeek-V3培训过程中的GPU成本,可以理解为净计算功率成本。
简短比较:
一般模型:
收到明确的说明并拆卸步骤。用户必须清楚地描述任务,包括答案的顺序。例如,如果用户需要提示是否先进行摘要,然后给出标题,或者以相反的方式给出。
根据概率预测(快速反应),响应速度很快,并且通过大量数据预测答案。
推理模型:
接收简单明了的任务,专注于目标,直接说出用户想要的东西,并可以自己制定计划。
响应速度很慢,并且基于链条思维(缓慢的思维),回答了推理问题的步骤。
两者之间的主要技术区别是培训数据。一般的大型模型是问题 +答案,推理大型模型是问题 +思维过程 +答案。
其次,由于DeepSeek的推理模型DeepSeek-R1引起了更多的关注,因此许多人错误地认为推论模型必须比通用模型更先进。
应该肯定的是,推理大型模型属于尖端模型类型,这是一个新的范式,在大型模型的预训练范式撞击墙之后,在推理阶段增加了计算能力。与通用大型模型相比,推理大型模型更昂贵,并且培训时间更长。
但这并不意味着推论模型必须比一般模型更有用,即使对于某些类型的问题,推理模型也似乎没有用。
大型模型领域的著名专家刘·康(Liu Cong)向“固定的焦点一人”解释了。例如,如果您询问一个国家的资本/某个位置,那么推理大型模型就不那么有用。

deepSeek-r1在面对简单问题时过度思考
他说,面对如此简单的问题,推理模型不仅具有回答比一般模型低的问题的效率,而且还具有相对昂贵的计算能力,甚至可能会过度思考,最终也可能会过度思考。 ,可以给出错误的答案。
他建议,在完成诸如数学问题和具有挑战性的编码,使用推理模型以及简单任务(例如摘要,翻译,基本问答问题和答案)之类的复杂任务时,一般模型将更有效。
第三个是DeepSeek的强大。
将权威列表和从业人员的声明结合在一起,“固定的焦点一”分别在推理大型模型和一般大型模型的领域中排名。
推理模型有四个主要层:Openai国外的O系列模型(例如O3-Mini),Google的Gemini 2.0;国内DeepSeek-R1和阿里巴巴的QWQ。
不止一个从业者认为,尽管外界正在讨论DeepSeek-R1作为最高国内模型,但从技术角度来看,与OpenAI的最新O3相比,仍然存在一定的差距。
它更重要的是,它大大缩小了顶级国内和外国水平之间的差距。 “如果以前的差距是2-3代,DeepSeek-R1出现后已缩小到0.5代。” AI行业的高级从业人员Jiang Shu说。
根据他自己的经验,他介绍了这四家公司的优势和缺点:
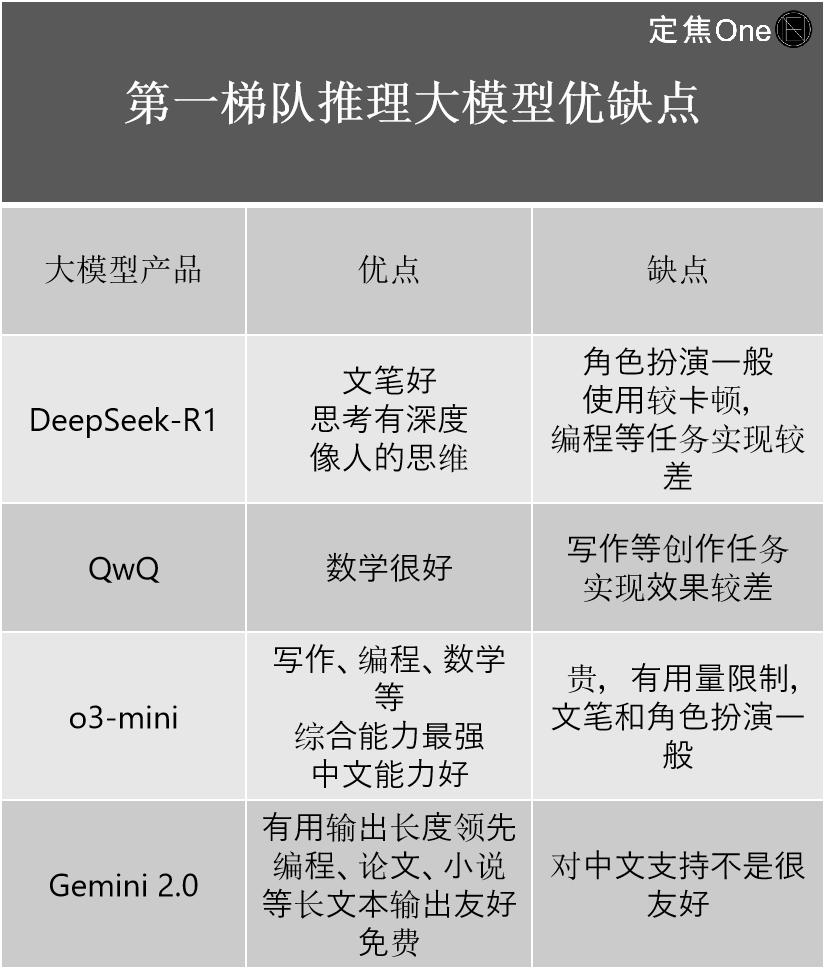
在一般大型模型领域,根据LM Arena的列表(用于评估和比较大语言模型(LLM)的开源平台),第一层中有五家公司:Google的Gemini(封闭的源)和Openai的外国Chatgpt,Anthropic的Claude;国内deepseek,阿里巴巴的Qwen。
江苏还列出了使用它们的经验。
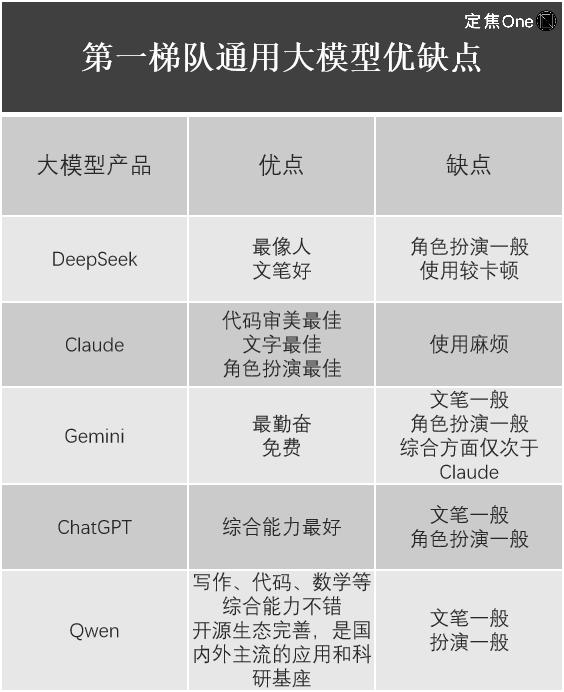
不难发现,尽管DeepSeek-R1震惊了全球技术圈,并且其价值毫无疑问,但每个大型模型产品都有其自己的优势和缺点,而DeepSeek并不是所有的大型模型。例如,Liu Cong发现,DeepSeek发行的最新多模型Janus-Pro(重点介绍了图像理解和生成任务)具有平均用法效应。
02训练大型型号要花多少钱?
回到培训大型型号的成本,一个大型模型到底是多么的?
Liu Cong说,大型模型的诞生主要分为两个阶段:训练前和培训后。如果将大型模型与孩子进行比较,那么训练前和训练后所需的是使孩子从天生变成认识成年人。您说的话,然后您将主动与成年人交谈。
预训练主要是指培训语料库。例如,如果您将大量的文本语料库投入模型,则可以让孩子完全的知识摄入量,但此刻他只是学会了知识,但仍然无法使用它。
训练后要求孩子告诉他们如何使用学习知识,包括两种方法:模型调整(SFT)和增强学习(RLHF)。
Liu Cong说,无论是通用模型还是推理模型,还是国内或外国人,每个人都遵循此过程。江苏还告诉“固定焦点一个”,每个公司都使用变压器模型,因此最低级别的模型组成和训练步骤没有本质上的区别。
许多从业人员说,每个大型模型的培训成本差异很大,主要关注硬件,数据和人工的三个部分。每个部分也可能采用不同的方法,相应的成本也不同。
Liu Cong分别举了例子,例如购买或租用硬件,两者的价格大不相同。如果您购买的话,早期的一次性投资将非常大,但是后期将大大减少。基本上,仅需要电费。如果您租房,则可能是初始投资不大,但是这部分成本永远无法保存。在所使用的培训数据方面,是直接购买现成的数据还是您自己爬行也有很大的不同。每个培训的成本都是不同的,例如第一次编写爬行者或执行数据筛选,但是下一版本的成本将降低,因为可以使用以前版本的重复。在最终提出模型之前,在中间迭代了多少版本也决定了成本,但是大型公司对此非常秘密。
简而言之,每个链接都涉及很多高的隐藏成本。
根据GPU的估计,在顶级模型中,GPT-4的培训成本约为7800万美元,Llama 3.1超过6000万美元,Claude 3.5约为1亿美元。但是,由于这些顶级大型模型是封闭源,并且每个公司是否都浪费了计算能力,因此很难知道外界。直到DeepSeek处于同一梯队,以557.6万美元的价格出现。

图像源/Unsplash
应当指出的是,DeepSeek技术报告中提到的基本模型DeepSeek-V3的培训成本为557.6万美元。 “ V3版本的培训成本只能代表上一次成功培训的成本。不包括先前的研究,建筑和算法试验和错误的成本;虽然论文中未提及R1的具体培训成本。”刘大说。也就是说,557.6万美元只是该模型总成本的一小部分。
半导体市场分析和预测公司半分析指出,考虑到服务器资本支出和运营成本等因素,DeepSeek的总成本可能在四年内达到25.73亿美元。
从业人员认为,与其他大型模型公司的100亿美元投资相比,DeepSeek的成本甚至低于25.73亿美元。
此外,DeepSeek-V3的培训过程仅需要2,048个NVIDIA GPU,而所使用的GPU小时仅为27.88亿。相比之下,OpenAI消耗了数万GPU,用于元训练模型Llama-3.1-405b的GPU小时为3,084。万。
DeepSeek不仅在模型培训阶段更有效,更具成本效益,而且在呼叫推理阶段更加有效和便宜。
从DeepSeek给出的各种模型的API定价(开发人员可以通过API调用大型模型来实现文本生成,对话交互,代码生成和其他功能),可以看出成本低于“ OpenAIS”的成本。人们普遍认为,开发成本高的API通常需要通过更高的定价来弥补成本。
DeepSeek-R1的API定价为:每百万个输入令牌(缓存命中)和16元产量令牌16元。相反,OpenAI的O3-Mini,输入(缓存命中)和输出令牌的定价分别为0.55。美元(4元),美元(31元)。
缓存命中,也就是说,从缓存中读取数据,而不是重新计算或调用模型以生成结果,可以减少数据处理的时间和成本。该行业具有差异化的缓存点击和缓存的失误,从而提高了API定价的竞争力,低价也使中小型企业更容易获得。
最近结束了折扣期的DeepSeek-V3已从每百万的原始输入令牌(Cache Hit)和每百万元产量2元提高到0.5元到0.5元和8元中的原始投入令牌,价格仍然较低,价格仍然较低比其他主流模型。 。
尽管很难估计大型模型的总培训成本,但从业人员同意,DeepSeek可能代表了一流的大型模型的最低成本,并且将来,公司应提及DeepSeek来下降。
03 DeepSeek的降低成本灵感
DeepSeek在哪里省钱?根据从业人员的声明,每个方面都从模型结构(训练前训练)中进行了优化。
例如,为了确保答案的专业精神,许多大型模型公司使用MOE模型(混合专家模型),也就是说,在面对复杂的问题时,大型模型将其拆卸为多个子任务,然后交出不同对不同专家答案的子任务。尽管许多大型公司都提到了这种模式,但DeepSeek已经达到了最终的专业专业水平。
秘诀是采用细粒的专家细分(同一类别的专家和子任务的专家细分)和共享的专家隔离(将一些专家隔离以减少知识冗余)。这样做的优点是它可以大大提高MOE参数的效率和性能。 ,更快,更准确地给出答案。
一些从业者估计,DeepSeekmoe等同于仅使用约40%的计算,从而获得与Llama2-7B相似的效果。
数据处理也是大型模型培训的障碍。每个人都在考虑如何提高计算效率并减少硬件要求,例如内存和带宽。 DeepSeek发现的方法是在处理数据时使用FP8低精度培训(用于加速深度学习培训)。刘·康(Liu Cong)说:“此举是在已知的开源模型领先的,毕竟,大多数大型模型都采用FP16或BF16混合精度训练。FP8训练速度比它们快得多。”
就训练后的强化学习而言,战略优化是一个主要的困难,可以理解为允许大型模型做出更好的决策。例如,Alphago学会了如何在策略优化中选择最佳移动策略。
DeepSeek选择GRPO(组相对策略优化),而不是PPO(近端策略优化)算法。两者之间的主要区别是执行算法优化时是否使用了值模型。前者估计组内通过相对奖励的主要函数,而后者则使用单独的值模型。使用一个较少的模型,计算能力需求自然会较小,并且还可以节省成本。
在推理水平上,使用长期潜在的注意机制(MLA)而不是传统的长期注意力(MHA)可显着降低记忆使用和计算复杂性。最直接的优势是降低了API接口成本。
但是,DeepSeek这次给Liu Cong的最大灵感是,它可以从不同角度提高大型模型的推理能力,纯模型微调(SFT)和纯强化学习(RLHF)可以使良好的推理大型模型。
来源/pexels
换句话说,目前有四种方法可以进行推理模型:
第一种类型:纯强化学习(DeepSeek-R1-Zero)
第二种:SFT+增强学习(DeepSeek-R1)
第三类:纯SFT(DeepSeek蒸馏模型)
第四类:纯提示单词(低成本小型模型)
“以前,SFT+增强学习在圈子中被标记。没有人期望纯SFT和纯强化学习也可以取得良好的结果。”刘大说。
DeepSeek的成本降低不仅为从业人员带来了技术灵感,而且还影响了AI公司的发展道路。
Inno Angel Fund的合伙人Wang Sheng介绍了AI行业在AGI的方向上经常有两种不同的途径选择:一个是“计算能力和军备”范式,可以积累技术,金钱和计算能力,并且首先提取大型模型的性能。当它达到高点时,请考虑行业的实施;另一个是“算法效率”范式,旨在从一开始就实施该行业,并通过建筑创新和工程能力推出低成本和高性能模型。
Wang Sheng说:“ DeepSeek的一系列模型证明,当天花板仍在上升时,专注于优化效率而不是产能增长的范式是可行的。”
从业者认为,随着算法的发展,大型模型的培训成本将进一步降低。
方舟投资管理的创始人兼首席执行官“ Miao Jie”曾指出,在DeepSeek之前,人工智能培训的成本每年下降了75%,推理成本甚至下降了85%至90%。王尚还表示,到年底在年初发布的模型成本将大幅下降,甚至可能下降到1/10。
独立研究公司Semiaalysis在最近的一份分析报告中指出,推理成本的下降是人工智能持续进展的迹象之一。可以实现过去需要超级计算机和多个GPU的GPT-3模型的性能,但是现在笔记本电脑上安装的一些小型型号可以达到相同的效果。而且费用也下降了很多。拟人化的首席执行官达里奥(Dario)认为,对于GPT-3质量的发展,成本已减少了1200倍。
将来,大型模型的成本降低速度将越来越快。
本文来自Wechat公共帐户,作者:Dingjiao One团队,由36KR出版并获得授权。
