[新的Zhiyuan简介] Redstone是一种处理管道,可有效地在指定字段中构建大规模数据。通过优化数据处理过程,从Common Crawl中提取了诸如Redstone-Web,Redstone-code,Redstone-Math和Redstone-QA之类的数据集。 ,在多个任务中超越了现有的开源数据集,从而显着改善了模型性能。
大型语言模型(LLM)在过去几年中已成为AI研究的关键领域,从大规模的自然语言数据中学习,使他们能够以极高的准确性执行与语言相关的任务。
得益于模型可扩展性的进步,研究人员能够创建具有前所未有的复杂性的模型。
当前的研究趋势是专注于建立具有数百亿个参数的更大且更复杂的模型,但是大型语言模型的培训需要大量的培训数据,尤其是随着模型参数的数量的增加,才能获得高质量的数据。数量的要求也将进一步增加,缺乏高质量的数据量极大地限制了模型能力的进一步增长。
Redstone是一种处理管道,可有效地构建大规模的数据处理工具和自定义处理模块,以进一步优化和开发。
通过Redstone,研究人员构建了多个数据集,包括Redstone-Web,Redstone-Code,Redstone-Math和Redstone-QA,它们超过了各种任务中当前的开源数据集,并且可以预先培训大型模型。除了培训后,它还提供可靠的数据支持。

纸张地址:
存储库链接:
由于公司的开源政策,Redstone仅开源数据索引和所有处理代码用于社区复制。但是,随着社区的注意力逐渐增加,目前有一个社区生产的Redstone版本。根据GitHub的项目描述,在规模和质量方面,复制的数据集类似于Redstone的内部数据。

图1红石概述图
如图1所示,Redstone使用常见的爬网作为原始数据源,旨在使用相同的数据处理框架清洁各种目标数据。
Redstone-Web是一种大规模的通用预训练数据,将常识注入模型。
Redstone-Code和Redstone-Math是网络中各种与代码/数学相关的数据。与其他开源代码和数学类型数据不同,网页中的代码/数学自然具有纯文本和代码/数学交错的形式。例如,代码教程,问题说明等。
因此,该模型可以在像人类一样的代码/数学上下文中借助纯文本进一步理解代码/数学。此外,Redstone还构建了Redstone-QA,这是一个大规模质量检查数据集,这是将各种知识注入模型的最简单,最直接的方法。
关于Redstone-Web,Redstone认为,高质量数据的定义至关重要。早期社区认为,诸如文本流利度等指标代表数据的质量。最近,越来越多的研究人员认为,具有教育意义的数据代表了高质量的数据。
Redstone在其中找到了一个平衡点,其中包含知识并在文本中平滑,并将其定义为高质量数据。只要知识都可以以任何形式使用,只要其中包含的内容就可以进一步发展模型对世界的理解。
因此,在Redstone-Web的构建中,主要的处理框架是指优化Web和Redpajama,但是删除了原始的过滤器模块,并使用了新建的过滤系统,总共有3.1吨高质量的通用PRE PRE PRE PRE PRE - 获得培训数据。其每个步骤及相应的数据量如图2所示。
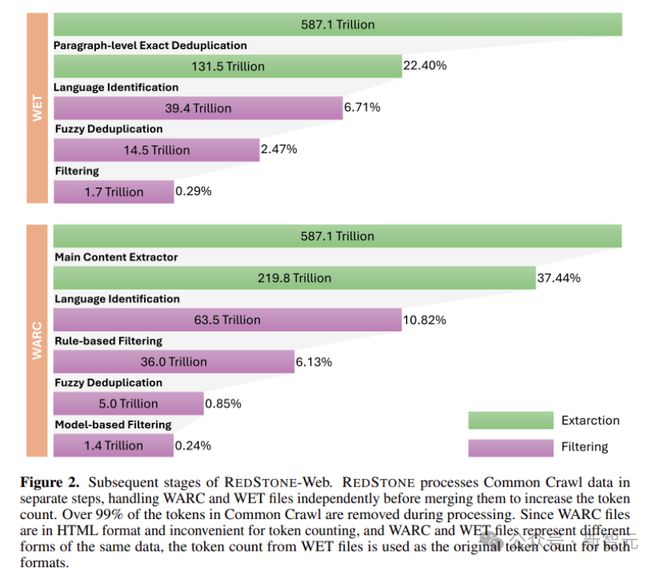
图2 Redstone-Web处理步骤
除了Redstone-Web一般领域的高质量数据集外,Redstone还认为,该网络是富有宝藏的矿物的地方,这足以挖掘出在一般领域以外遗漏的各种数据(例如,对于Redstone-Web,某些页面总体上不是高质量的,但是其中一个夹子在特定领域中具有很高的质量),然后是专有的数据建造了红石-QA。
核心仍在过滤。 Redstone提出了一个对应于不同数据量表的多层过滤系统。例如,使用fasftext对所有网页进行统一和快速过滤,然后使用更高的性能模型进行精细的过滤和碎片提取。该论文指出,Redstone支持构建其他类型的专有数据,只需自定义过滤器即可。通用和特定域数据构建代码都是开源的。
图3显示了最终单个数据集的大小。
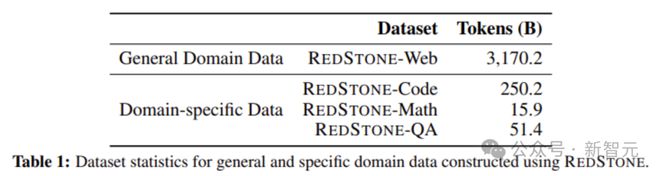
图3数据集大小
为了验证每个数据集的质量,作者使用这些数据分别训练模型,并将其与开源数据集进行了比较。如图4所示。在大多数任务中,Redstone-Web显着高于所有其他开源数据集,并且在平均得分度量中获得了第一名。这表明Redstone-Web可以显着提高模型性能并使模型训练更有效。
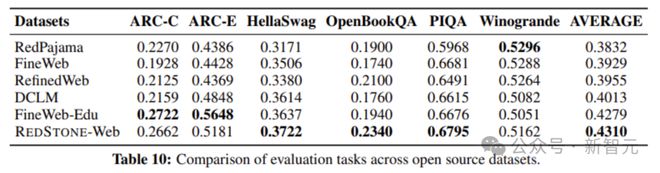
图4 Redstone-Web和开源预训练数据集的比较

图5红石代码结果显示
考虑到红石代码来自网页,并且数据的形式是交织的文本和代码的形式,因此社区中没有此类数据集,因此根据Redstone-Web添加Redstone-code进行实验。
可以看出,如果不添加纯代码(例如github),所有数据仅来自网页。红石代码还可以显着提高模型的代码功能,表明红石代码可以将足够的代码注入模型。知识,对于已经用尽代码数据的社区,这是一个数据集,可以大大扩展代码字段中的数据。

图6 Redstone-web和开源数据的比较
图6显示了Redstone-Math与社区开源数据OpenWebmath之间的比较。结果表明,在相同的设置和步骤下,Redstone-Math得分高于OpenWebmath。尽管OpenWebmath也来自网络,但这要归功于越来越多的良好过滤器最终可以实现更高的数据质量。
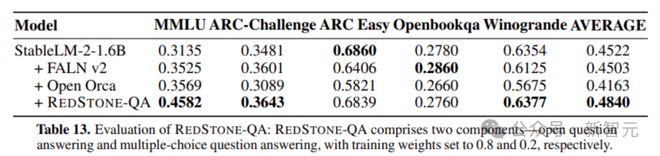
图7 Redstone-QA与开源数据的比较
与其他开源QA数据集相比,Redstone-QA仅依赖更多QA数据,只有从网络上爬行QA对,可以显着改善该模型(例如,MMLU提高了10分),这更多地表明,这表明Internet表明了Internet是富含宝藏的矿物的地方。
除上述区域外,红石的使用几乎不受域的不受限制,任何人都可以使用开源代码来爬行特定区域。
从图4到7的结果可以看出,红石构建的数据显示出LLM前训练和训练后具有有希望的能力,使其成为构建各种LLM培训数据的多功能且实用的管道。
参考:
