马斯克的Grok-3又延长了Nvidia的寿命吗?
接受了200,000 GPU培训的Grok -3突然重新获得了对Nvidia的信心-Li da Brick Fly仍然有效!
现在,NVIDIA的股票价格已恢复到深深res-R1的水平。
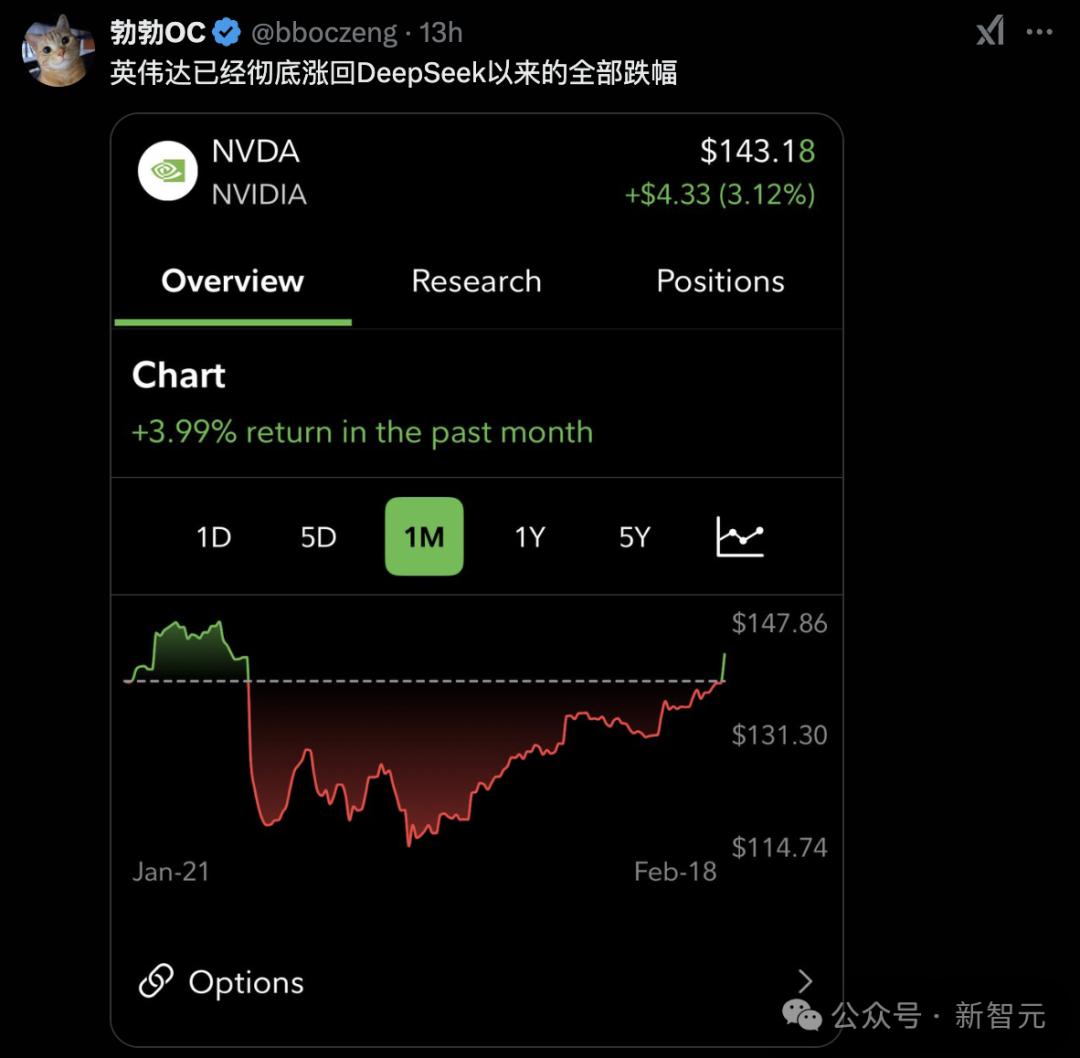
AI Tycoons认为Grok-3证明了扩展法的神话还没有结束。
随着计算能力增加了10倍,缩放定律仍在线性增长。由于我们可以通过扩大预培训的规模来成功创建一流的非推动模型,因此这意味着尽管预训练很昂贵,但仍有很大的开发空间。
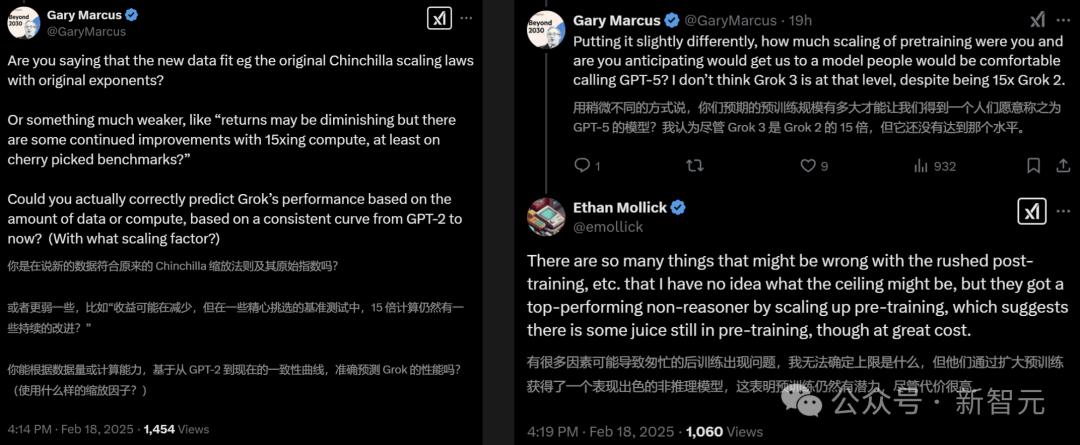
如果LLM想开发和开发,它是否应该继续在GPU上库存并积累计算能力? Grok 3的发布使许多人不确定。
不管事实是什么,最重要的是,市场和投资者的信心又回来了。
Grok-3的硬件成本被发现高达30亿美元!
在多个基准测试中,Grok-3超过了OpenAI和DeepSeek的模型。在LMSYS竞技场中,Grok-3直接屠杀了名单,并获得了1,400的超高ELO得分,而主要的型号没有超过它们。

这意味着,DeepSeek迷失了吗?
不!
这是因为培训的成本Grok-3太好了...
马斯克透露,在训练阶段,Grok-3使用的计算能力比Grok-2高10倍。
有人计算了孟菲斯中心Xai的GPU的总成本。如果计算为100,000 h100,而每年GPU的成本为30,000美元,则Grok-3的总硬件消耗量为30亿美元。

总费用:超过30亿美元
培训期限:2亿GPU小时
硬件投资:100,000 GPU(另一个说法是200,000)
这些数字加起来非常了不起。
在直播期间,XAI工程师不确定将来可以培训多少Grok 3。
相比之下,DeepSeek-V3的纸质培训成本为557.6万美元,这是2,048 nvidia h800,这是一个直接判断。
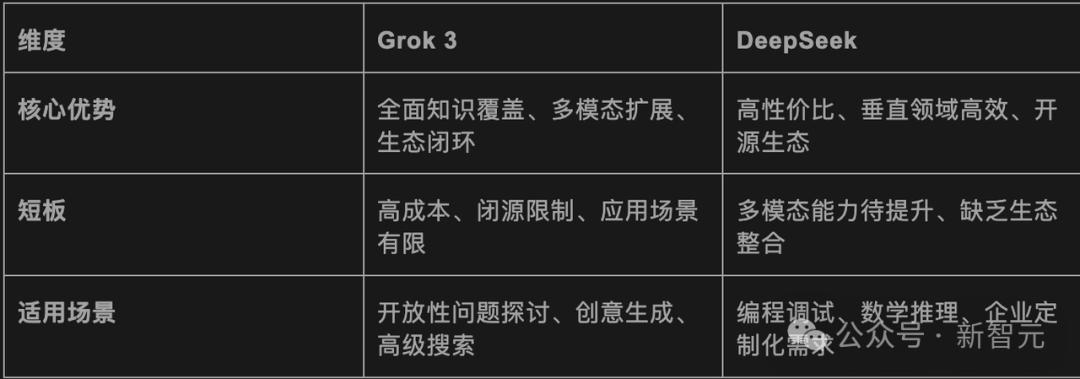
从“大哥商业观察”
此外,目前Grok-3是封闭的消息来源,每月费用为30美元,并且只计划在接下来的几个月内开源Grok-2。
DeepSeek通过其开源战略吸引了全球开发人员,将微信,Baidu和Tencent等主流应用程序整合在一起,并领导了生态系统。
简而言之,一个是付出巨大的努力来实现奇迹,另一个是包含技术。两条路线中的哪个更好?让我们拭目以待,看看后续行动。
Grok-3完整网络测试
话虽如此,Grok-3是世界上最聪明的,比DeepSeek-R1更快,更好吗?
Zihan Wang是DeepSeek的前员工,西北大学的博士生,他立即经历了Grok-3 Beta版本,并问了3个问题:
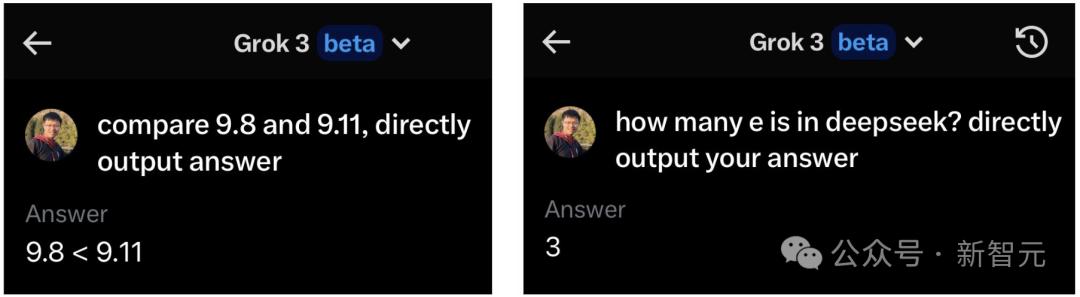
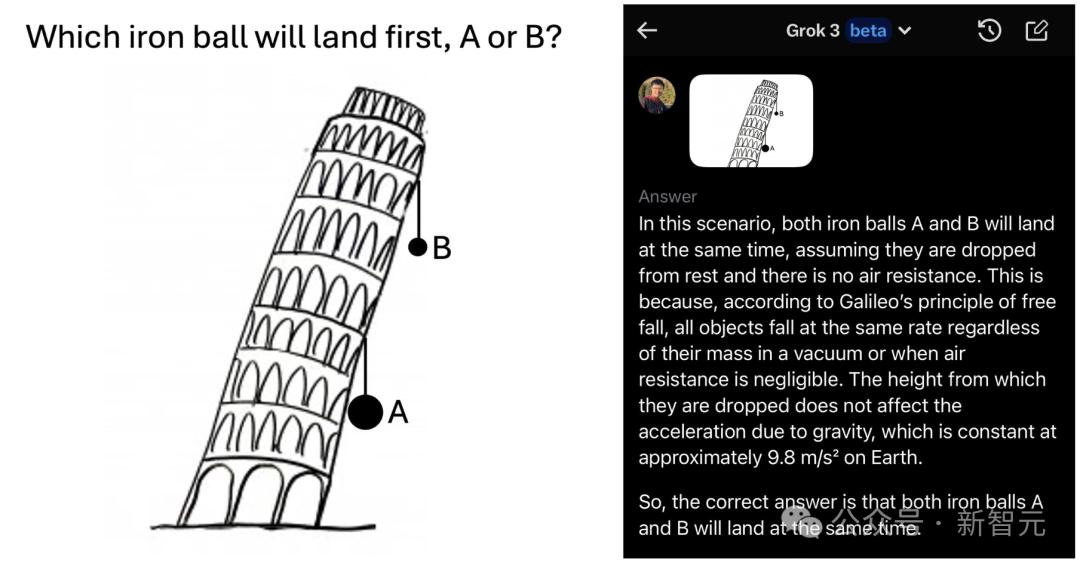
Grok-3 Beta回答所有小学生都可以正确回答的所有问题!
他说,这是一个愚蠢的天才问题:
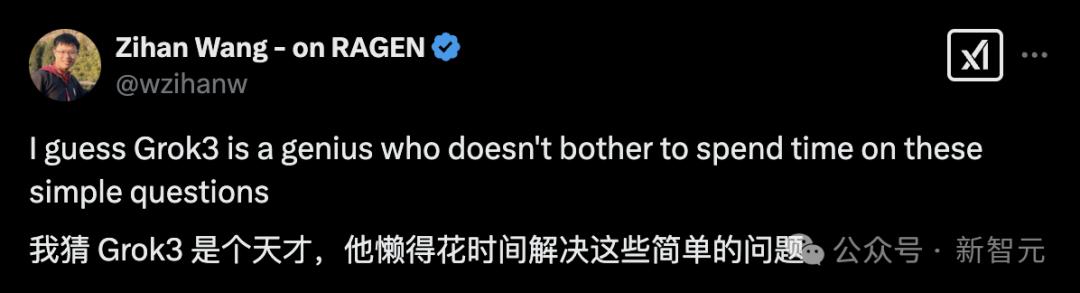
尽管Grok-3有时在提出几个问题后可以正确回答其中一个问题之一。
这吸引了XAI的研究科学家Bill Yuchen Lin的注意。他说,Grok-3仍在测试中,但每天都应该更好,更稳定。

在许多网民的实际测试中,Grok-3的性能仍然非常酷。
Grok 3可以制作类似于Mario的迷你游戏。
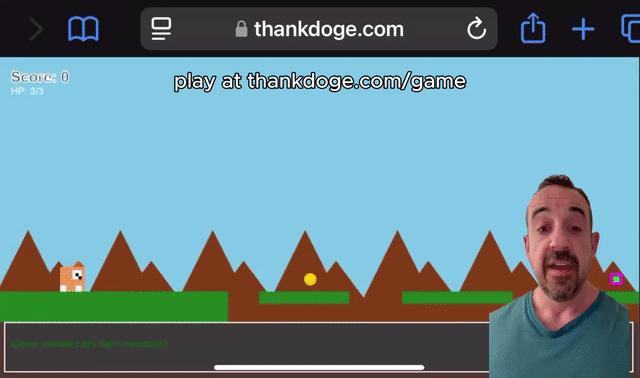
使用Grok-3,您也可以自己学习编程。


在相同的提示下,网民比较了Grok-3和DeepSeek(实际上是R1)。

1。AI趋势分析
在这个问题中,这两个模型需要分析Musk关于AI安全性的最后50条文本,确定关键主题,并将其与Lecun发表的法国帖子进行比较。
结果是Grok-3赢得了比赛,该游戏有效地确定了关键主题和对比的位置。而DeepSeek在多语言解析和上下文分析的步骤中失去了。



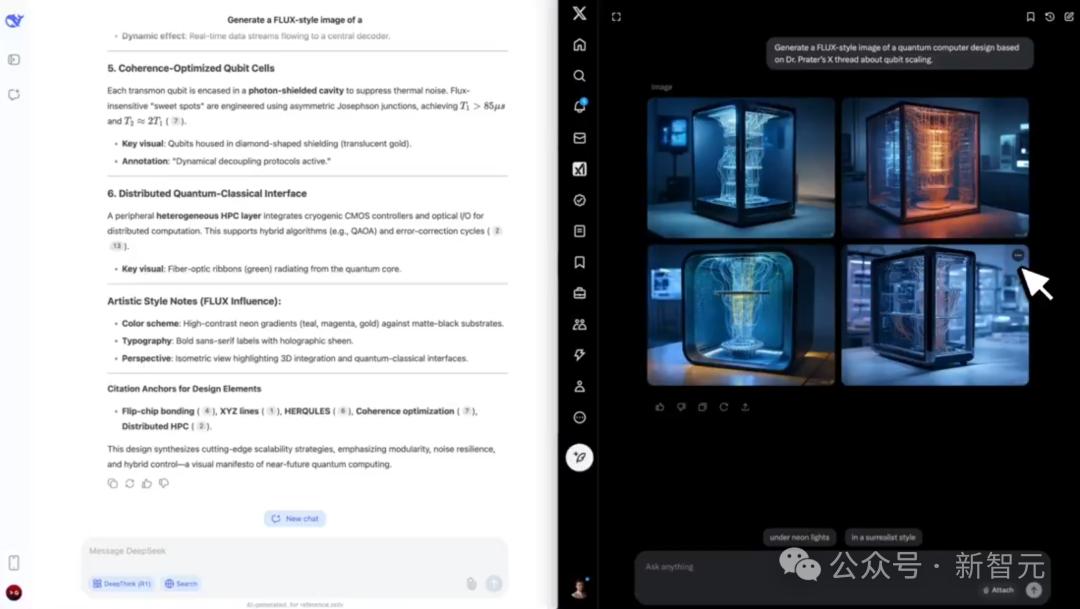
2。培养基合成
这个问题的任务是:“基于Prater博士在X上有关量子扩展的帖子,生成了磁通式量子计算机设计图。”
最后,Grok-3基于提取的数据创建了相应的图像。 DeepSeek-V3不是多模式的模型,因此未能给出结果。


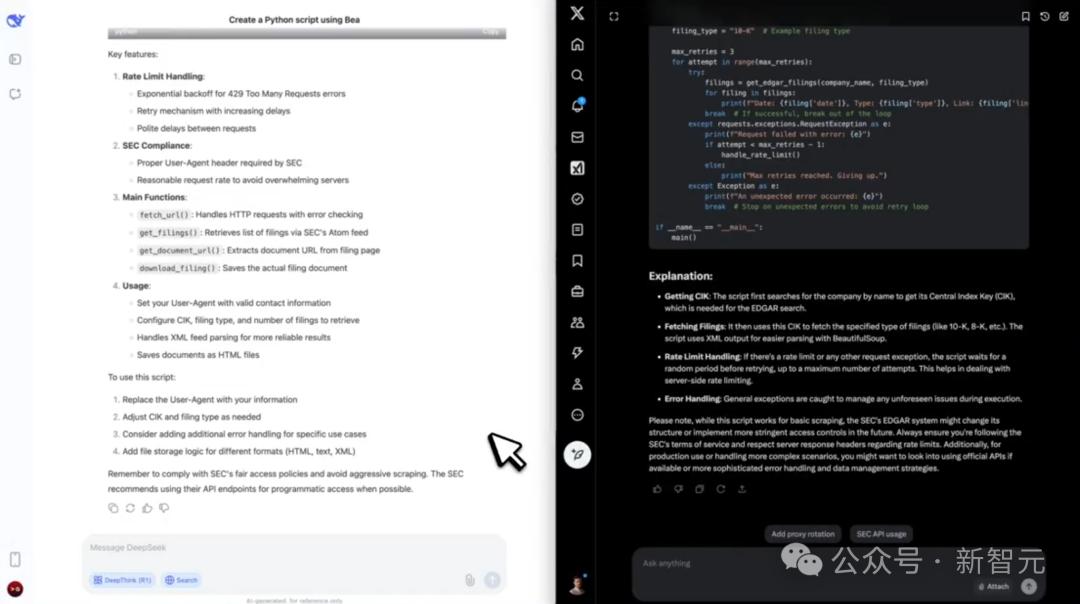
3。代码工作流
使用BeautifulSoup编写一个Python脚本,该脚本从Edgar中获取SEC文件,并包含用于限制的错误处理。
最终,Grok-3提供了一个结构化的脚本,该脚本也使用速率限制处理。虽然DeepSeek花了248秒来考虑这个问题,但没有执行它。


4。限制的创意播放
“使用莎士比亚风格的十四行诗来解释五步式Iambo中的区块链共识机制。”
这个问题是DeepSeek-V3的胜利。它使用完美的结构化押韵来模仿莎士比亚的风格。而Grok-3被困。

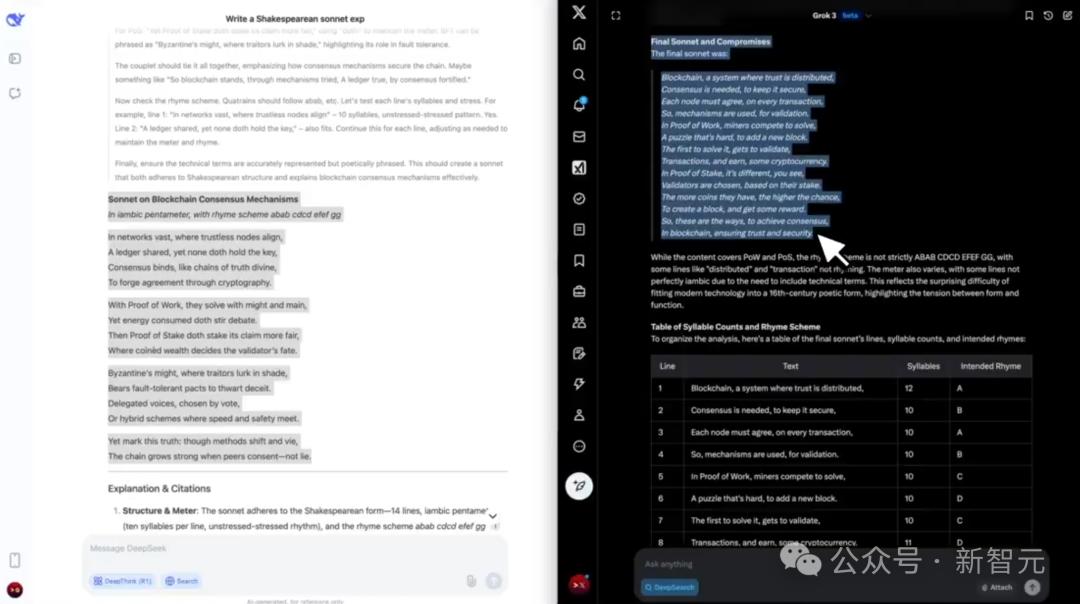

双方都在保持道德挑战,处理有争议的主题和内容依从性方面相互关联。
最后,Grok-3赢得了4:3。

AI2老板:Grok-3,将AI开发带入新阶段
艾伦人工智能研究所(AI2)的内森·兰伯特(Nathan Lambert)认为,Grok-3的释放确实意味着AI发展的新阶段。

Xai在直播中说,他们几乎“每天”更新Grok-3。 AI公司过去喜欢抑制新模型而不释放它们的时代即将结束。
自从DeepSeek-V3/R1发行以来,AI技术的开发既不是少数公司的专利,也没有放慢速度。
AI行业通常认可这一趋势,而Grok-3的发布进一步增强了这一趋势。
在2023年和2024年,真正的AI最高技术主要集中在Openai,Anthropic和Google玩家中。
这些公司可以平静地将模型从培训转变为释放,同时仍然远远超过了“技术护城河”能力的竞争对手。
当R1发布时,最受欢迎的模型是Claude 3.5十四行诗,该十四行诗已完成“ 9-12个月前”的培训。由于各种原因,诸如Claude 3.5 Opus或GPT-4.5(也称为Orion)之类的更强大的模型不向用户开放。
快速发布是最好的方法
在Deepseek和Grok带来的竞争压力下,再加上国内和国际环境的变化,这些传统的领先实验室将不得不加快产品发行速度。
该模型发布的很大一部分是“安全测试”,但我们不确定是由于安全性测试以及多少是由于成本效益的考虑(以及法律公司(法律)特定的问题,审查)。
对于这些公司而言,拥有“ Smarst Model”的品牌和文化非常重要,但是保持绝对领先的技术优势通常会带来难以忍受的财务压力。
加强竞争和减少的监督使普通用户可以在较短的时间内获得更强大的AI。
实践反复证明,拥有最强的模型至关重要。吸引新用户的唯一方法是证明该模型在某些能力或行为上是不同的。
在技术快速发展的背景下,最大化其影响力的最有效方法是缩短从培训到尽可能多的部署时间。
如今,DeepSeek和Xai已经证明,即使他们在技术实力和资源分配方面有轻微的劣势,他们也可以在竞争中脱颖而出,并超越OpenAI和Anthropic等公司,并故意保持不变,并选择不发布最新模型。
训练前的缩放法律仍然可以发挥作用吗?
从技术角度来看,Grok-3无疑非常大。尽管没有具体的细节,但可以合理地推测缩放仍然有助于提高性能(但在成本方面可能不是这种情况)。
XAI方法和发布的消息一直是尽快启动最大的计算集群。在获得更多细节之前,最简单的解释是扩展定律仍然有效。但是,Grok的性能也可能来自其他技术,而不仅仅是纯缩放。

内森·兰伯特(Nathan Lambert)认为,Grok-3是扩展法律的另一个胜利:
Grok 3按规模超过了现有的模型,回想起Nemotron 340B超过Llama 3 70b的那一刻。尽管Nemotron当时成为开源模型的领导者,但与成本投资相比,其绩效提高并不具有成本效益,并且市场接受度一直很低。
总体而言,尽管Grok-3中的技术突破有重大突破,但这并不意味着在高效模型培训领域的竞争格局已经发生了很大的变化。
Xai显然正在赶上Openai,Anthropic,尤其是Google。但是,所有现有的指标都表明,这些研究机构仍在模型培训效率方面处于领先地位。
令人高兴的是,这种竞争性情况迫使这些机构专注于提高模型的绝对情报水平,而不仅仅是继续优化其成本效益。
进步方向
如果AI模型和整个行业都在加速,那么考虑一下它们的方向很重要。
现在,用于评估领先模型的大多数方法现在不是代表性的。在许多情况下,它们实际上与正常生活完全失去联系。
解决竞争数学问题(例如AIM或所谓的“ Google证明”问题)有什么价值?也许时间会提供证据,但是对于普通用户而言,其有用性绝对有限。
Chatbotarena评论的略有改进仅表明系统稳定性略有改善。这种稳健性随着时间的推移而积累,但远非说该模型在绝对意义上更聪明。
实际上,从研究界的最新评估方法来看,测试标准似乎更关注难度,而不是实用性。
随着模型变得更强大,研究人员自然会寻找更具挑战性的任务来测试它们,但这使跟踪技术进步和相关沟通变得更加困难。
主要公司有许多未公开的内部评估指标。提高该领域的透明度将有助于更好地了解什么真正有意义的进步。
目前,在没有这些指标的情况下,用户只能根据模型与产品之间的整合程度来判断其发展。尽管这种合作确实可以导致一种宝贵的工作方式,但衡量AI进步的方法最终是间接的。
回顾2024年,尽管表面上的进度似乎有限,但实际上有许多实质性的突破,但最终只有少数人交付给用户。
直到年底,O1才来了,其他型号要么被认为“太大而无法部署”,要么缺乏必要的紧迫性。
深刻的是,带来cat鱼效应,给这些公司带来紧迫感,每年使情报进入用户2025年。
基础技术的进展将继续很高。以前预测的AI开发的所谓“瓶颈”尚未出现。
参考:jhnyz
本文来自作者:Xin Zhiyuan的微信公共帐户“ Xin Zhiyuan”,由36KR发表并授权。
