
文 观察者网心智观察所
DeepSeek 实现了“小扣发大鸣”。在半年多的时间里,它不仅将 LLM 通用模型从 V2 迭代到了 V3,还进一步推出了主打推理能力的 R1 模型。从训练成本、架构调整以及开源模式等多个方面来看,它都在全球范围内展现出了惊人的实力,引发了如山呼海啸般的赞誉。春节期间大洋彼岸资本市场大幅震荡,开年后国内“DeepSeek 概念股”大涨,这一现象持续成为坊间热议的焦点。
DeepSeek 获得了成功,它顺应了从预训练到推理的 AI 大模型的必然演化进程。为什么 DeepSeek 的崛起是顺天应时的举动呢?不妨先来看两段话。
去年 2 月下旬,英伟达 CEO 黄仁勋在接受美国科技媒体 Wired 采访时表示:英伟达现今的业务大概是 40%用于推理,60%用于训练。这是一件好事,因为这能让人们意识到人工智能终于取得了成功。倘若英伟达的业务是 90%用于训练,10%用于推理,那么就可以说人工智能仍处在早期研究阶段。
去年 12 月,OpenAI 的首席财务官莎拉·弗里尔在接受《Theinformation》采访时表示:“OpenAI 的 GPT Pro 向 C 端用户开放的套餐每月价格为 200 美元,这实在是过于便宜了。其合理的价格应当是每月 2000 美元。”结合她上下文的采访内容,她主要表达的意思是 OpenAI“心善”,秉持着 AI 为大众平权服务的道义感,所以没有把价格定得很高。如今,他们这种虚伪的表象在 DeepSeek R1 开源模型面前完全被揭下了。
这两段话具有代表性。一段指向 AI 技术应用的演进方向,另一段关乎 AI 推训模式落地的商业化问题。这两个层面的问题相互交织,互为表里。
OpenAI 在牵头搞“星际之门”这件事上,把算力的 Scale Law 延伸到了民间资本市场和国家投资领域,还试图将 AI 产业与美国国运绑定。就在此时,DeepSeek 对其进行了一种釜底抽薪式的叙事消解。
在众声喧哗的环境中,来自大洋彼岸的质疑以及带有恶意性质的诋毁都值得关注。
分析美国 AI 大模型行业某些头面人物的评论,能看出他们带有惊慌失措的心理。通过这样的分析,我们可以进一步深化对 DeepSeek 到底打到了对方哪些痛处的认知。知名半导体咨询机构 Semianalysis 的总裁 Dylan Patel 和 Anthropic 的 CEO Dario Amodei 代表了大洋彼岸的详细分析数据和质疑声音,这两家在中文互联网世界被翻译后大量被转载。

Anthropic的CEO Dario Amodei
他们主要从以下四个角度,试图告诉公众 DeepSeek 的突破其实没那么“硬核”:一是 GPU 囤货;二是成本测算;三是存在非技术性营销;四是模型数据蒸馏不合规。
一、摇唇鼓舌DeepSeek囤货“敏感性”高端GPU
Semianaylsis 测算得出,“DeepSeek 拥有约 10000 张 H800 GPU 芯片,同时拥有 10000 张 H100 GPU 芯片,并且还拥有大量 H20 GPU 芯片”。
Dario Amodei 在长文中转述了 Semianaylsis 的测算。他认为 DeepSeek 手上拥有用于训练和推理的 Hopper 架构的英伟达 GPU 卡,无论是阉割版还是非阉割版,数量差不多有 5 万张。这个数量与美国主要头部的 AI 模型训练机构如 OpenAI、Deepmind 等相比,差距在两三倍左右。结合基于合成数据(synthetic data generation)和强化学习进行推理能力提升的后训练(post-training)方法,他认为 DeepSeek 本来就站在巨人的肩膀上,并且使用了巨量的 GPU,才取得了今天的成果。
Dario Amodei 为何要用 Semianaylsis 数据为自己撑场面呢?因为 Dario Amodei 心中存有一个所谓的 AI 训练成本的“摩尔定律法”,即每一年大概能降低三到四倍。若使用强化学习的方法进行推理架构调整,能够把成本降至六至八倍,但这就是降低成本的极限了。依据这种成本测算假说来进行推断的话,DeepSeek拥有五万张 Hopper 卡。
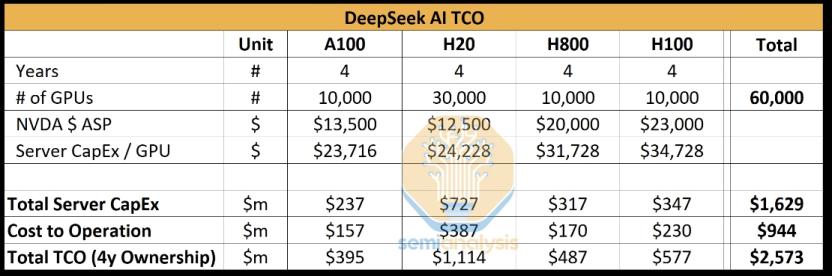
如果我们继续追问,Semianaylsis 觉得 DeepSeek 拥有如此多的高端 GPU 卡,他们是通过何种方式计算出来的呢?他们运用了一种类似于归谬法的推理方式。Anthropic 仅训练一个 Claude 3.5 Sonnet 的成本达到了数千万美元。如果 DeepSeek 具备能够大幅降低成本的能力,那么 Anthropic 又何必费尽心思去寻找亚马逊融资数亿呢?
关于 Anthropic 究竟是以何种方式花费投资人的钱,或许马斯克旗下的 DOGE 更愿意去进行回答。代表云服务商亚马逊一派的 Anthropic CEO 相比微软、谷歌一派,按耐不住跳出来写长文,其主要原因之一是深刻觉察到,在十万到百万级 GPU 基础上的生态进行推训时,他们的 Claude 系列总价格是最高的,总性价比也是最低的。
DeepSeek 合法拥有的 H800 与 H100 相比,主要是把 NVlink 的通信带宽给阉割了。H20 虽然也是阉割版,它的单卡算力仅仅只有 H100 的 20%。不过 H20 能够通过多卡堆叠模式,它的 HBM 容量(96GB)甚至比 A100 和 H100 的(80GB)还要高。H20 的显存带宽使得 DeepSeek 的 Decode 阶段每生成 1 个 Token 所需的时间比 H100 低。
DeepSeek 发挥出了阉割版所具备但禁运版没有的功效,这使得 Dario Amodei 竟然说出了应当对中国大陆进一步加强 GPU 管制的恶意言论,或许这才是他抨击 DeepSeek 的真正目的。
从话语体系方面来看,Semianalysis 依据 Anthropic 存在缺乏公允性的 AI 模型训练成本这一情况,反推 DeepSeek 有可能避开管制并非法持有高端 GPU。而 Anthropic 则反过来利用 Semianalysis 基于不稳固基础(如沙堆之上)所做出的推论,来论述 DeepSeek 在成本问题上并没有特别突出之处。实际上,这是一种合谋式的循环论证。
二、DeepSeek隐藏了总成本(TCO)参数?
Semianalysis 和 Anthropic 对 DeepSeek 总成本的推断,涉及到除 GPU 采购之外的一些因素。这些因素包括优化架构、处理数据以及支付员工薪资等。而这些恰恰是我们最不需要花费心思去反驳的。
通常意义上,H100 的云租赁成本不包含电力成本。在数据中心实际托管的 IT 设备成本,与占地面积有关,与园区环境有关,也与政策支持有关。
Semianalysis 从未到中国进行实地调研,它依据美国行情来判断 DeepSeek 的 API 服务成本是不合适的。并且美国本土的云服务与大模型部署合作也十分复杂。微软在公共和私有实例的推理方面,比 OpenAI 自己的 API 更受更多客户选择。微软当年用自己的云服务积分置换对 OpenAI 的“天使轮投资”,这一举措很聪明。亚马逊喜欢宣称他们的 SageMaker 平台是客户在云上创建、训练和部署模型的好工具,但实际上他们用英伟达的 Nemo 云原生框架代替 SageMaker 来开发模型。
Semianalysis 对 DeepSeek R1 模型通过 MLA(Multi-head Latent Attention)优化 KV Cache 机制进行了分析。相比之下,他们对 DeepSeek 托管、运维以及员工薪资的分析更像是一种臆测。
三、DeepSeek赢在了营销?
缺乏扎实调研和推论依据的成本估算让人觉得奇怪,而更让人惊讶的是,Semianalysis 和 Dario Amodei 都花费了不少篇幅来阐述 DeepSeek 的“营销”手段,这些手段包括 R1 模型在实战中会先向用户展示推理的思路框架,以及 DeepSeek R1 故意将发布时间定在特朗普就职典礼等。Semianalysis 的总裁 Dylan Patel 在近期的视频节目里指出,DeepSeek 的营销优势在于一个“快”字。例如,在半年多之前就推出了成熟度欠佳的 V2 模型,其目的是进行炒作。
海外大厂都是无利不起早的,它们用实际行动进行了反击这种“营销”说。从 1 月 25 日到 2 月 1 日,AMD 的 MI300X GPU 表示支持和接入 DeepSeek V3/RI/Janus 模型,英伟达 NIM 微服务也表示支持和接入,英特尔 Gaudi 2D Al 加速器同样表示支持和接入。如果 DeepSeek 没有展示出足够的技术实力,这些大厂不会配合它“营销”的。
Semianalysis 或许忽视了这样一个事实,2022 年底 OpenAI 急切地推出了 GPT,它采取的是先占据位置然后再进行调试的路线。谷歌的 Bard(如今已改名为 Gemini)晚了一步,被 OpenAI 抢占了先机,这是因为其创始团队担心这种聊天机器人会抢夺搜索引擎市场,从而影响谷歌的营收,要知道对于谷歌来说,依靠搜索引擎导入的广告收入占比很大。
这一次,OpenAI 在压力的作用下推出了全新的免费 o3-mini。有趣的是,o3 正在模仿 R1 来展示推理思维链。由此可见,“创新者困境”的魔咒与营销并无关联,这是一种推陈出新的竞争方式,像涌浪一样。指责 DeepSeek 以快取胜是没有道理的。
从另一个层面来看,OpenAI 以及 Anthropic 的同推理模型为何不展示具体的推理思路呢?展示推理链路真的是一种营销行为吗?
OpenAI 的理由是优化用户体验界面,以避免信息过载。Anthropic 的理由也是优化用户体验界面,避免信息过载。这个问题触及到了这几家公司的深层次顾虑。一方面,模型的内部工作机制,像微调策略以及特定任务的优化方法等,可能会导致竞争对手进行逆向工程。另一方面,保持黑盒化的推理过程,能够避免外界过度渲染这些工具的黑历史。从一开始,GPT 就因不断爬取《纽约时报》、《华尔街日报》等公众媒体和数据资源来进行语料训练而颇具争议性,其合规性经营一直遭受质疑,甚至一度走到了法律诉讼的层面。

由此可见,OpenAI 这些公司原本是通过营销而发展起来的。谷歌也是如此。Anthropic 同样如此。这些 AI 模型公司无法效仿 DeepSeek 所谓的“营销大法”,并非是它们不想做,而是实际上做不到。
结语:模型蒸馏是DeepSeek给全人类的美好馈赠
Semianalysis 的总裁 Dylan Patel 以及 Anthropic 的 CEO Dario Amodei 对 DeepSeek 的评述存在一个共性,他们认为 R1 远不如 V3 有趣。他们的主要论据是 R1 很有可能使用了模型蒸馏。
在保证模型性能和效率的前提下,推动 AI 技术的普惠化,让它成为像水和电那样的公共产品,模型数据蒸馏以及用户知识蒸馏是一条必然要走的路,它既优化了资源的利用,又能加速模型向本地部署和端侧推理进行迁移,对构建可持续且高效的 AI 生态有着重要的意义。
OpenAI 团队的创立是对谷歌 AI 商业化路线的一种逆反。当时 Altman 和马斯克秉持着为全人类寻找 AGI 途径的愿景,所以取了“OpenAI”这个名字。如今 OpenAI 变成了“CloseAI”,这其实已经偏离了当初的初心。
Dario Amodei 指责 DeepSeek 进行蒸馏存在侵犯知识产权的风险。然而,正如之前所说,这些美国大厂都享受到了数据时代的红利,在《纽约时报》意识到要进行法律诉讼之前,就已经将语料数据“窃取”到手了,既然已经吃下去了,又怎么可能再吐出来呢?
曾经,高深难懂的 AI 技术是学院派们专有的。英伟达的 CUDA 软件开发者系统平台,起初让先驱者们获得了在商业市场中尝试的机会。不久之后,AI 的重心从斯坦福大学、多伦多大学和加州理工等地方转移到了初创公司里。
辛顿加入了谷歌,李飞飞也加入了谷歌。吴恩达前往了百度。Altman 与苏茨克维等一起创办了 OpenAI,他们共同将 AI 带向了公众视野。
AI 生产要素的流动其实是人才、软硬件技术以及资本市场的一种变相“蒸馏”。Anthropic 本来就脱胎自 OpenAI,它也是用户知识蒸馏的最大受益者。
一段时间前,李飞飞团队以“50 美元”的成本复刻了 DeepSeek-R1。这一举措蕴含着梁文峰们的美好愿景,即推动知识与信息的平等,让 AI 成为造福全人类的公共产品。
来源|心智观察所
